


Neurodynamics- and observer-based distributed robust formation control for mobile robots
 0
0 Abstract
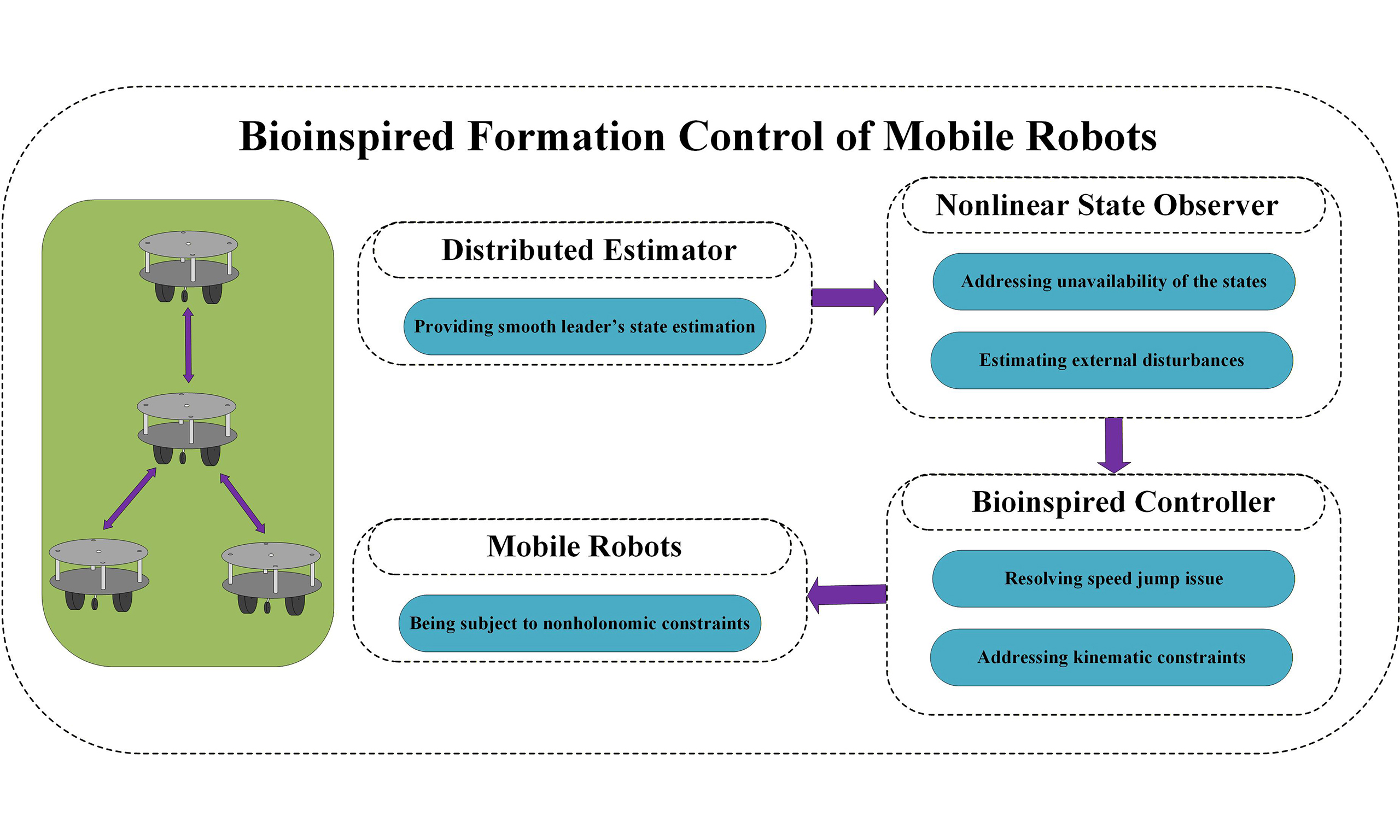
The formation control of multiple robot systems presents significant challenges due to practical constraints such as disturbances, speed discontinuities, velocity constraints, and incomplete state information. This paper introduces a novel biologically inspired control scheme that effectively addresses these challenges. First, utilizing the cascade design technique, a distributed estimator is presented to provide smooth estimates of the leader’s state without requiring derivative information. Subsequently, a nonlinear state estimator is proposed to provide accurate estimates of both states and disturbances. After that, a biologically inspired kinematic controller is developed that effectively resolves the speed surge and velocity constraint issues. Following the kinematic control design, a robust dynamic controller is developed based on the observed state to enhance robustness against disturbances. Finally, extensive simulation studies validate the effectiveness of the proposed approach and verify the theoretical results.
Keywords
1. INTRODUCTION
Autonomous robotic platforms are increasingly valued in sectors such as emergency rescue missions, agriculture, and environmental monitoring [1–4]. Formation control has been a core research topic within multirobot collaboration and still attracts much research attention. The current formation techniques are classified mainly into the following categories: behavior-based approach [5–7], leader-follower based approach [8–10], and virtual structure approaches [11–13]. Among these methods, the leader-follower approach has been widely adopted in industrial practice due to its architectural simplicity and ease of implementation [10,14,15]. This approach maintains a predefined formation by setting specific robots as the navigation reference, and the rest of the follower dynamically adjusts their relative positions to maintain the formation.
It is noticed that the robustness of the traditional centralized strategy decreases drastically when the number of following units increases, and failure of the leader node may trigger a system-level failure. Furthermore, the effectiveness of the system is strongly correlated with communication quality, and the surge of the network load is prone to lead to latency and deterioration of stability. To overcome these bottlenecks, modern research has increasingly adopted distributed control frameworks, which are developed based on local information exchange and awareness of neighboring states, thereby enhancing the system's fault tolerance and scalability [16,17]. There has been a significant amount of work that addresses the distributed formation approach of mobile robots [18–22]. However, the formation performance heavily depends on the state estimation accuracy. In the work by Peng et al., an extended state observer along with a Kalman filter is developed to compensate for the disturbances and noises for mobile robots[23]. Another research proposed a fixed-time extended state observer that observes the total disturbances [24]. This research uses their respective approach to estimate the disturbances and the robot states. Furthermore, formation performance depends not only on the accuracy of the estimation techniques but also on the handling of practical constraints, such as velocity surge at the initial stage and velocity constraints, which occur in some of the existing work [25,26]. To better understand the velocity surge, it is described that when there is an initial error, the generated velocity is non-zero and therefore potentially generates an unreachable infinite torque command. Therefore, taking these critical challenges into the design of the formation control is rather important.
In this research, we address distributed leader-following in multi-mobile robot formation control and systematically solve three core challenges, namely unknown states, velocity jumps, and dynamic constraints. Firstly, to achieve consensus, a distributed observer is constructed to carry out the estimation of the leader's positional and velocity states through the local information interaction among the following nodes. Then, we construct a nonlinear estimation scheme to realize the robot states under uncertain external perturbations. After that, we introduce the adaptive response mechanism of biological neurons to construct a neurodynamic motion controller, which effectively resolves the steep changes in velocity commands observed in some existing works and ensures that these commands remain within preset thresholds. In addition, a dynamic controller is implemented that ensures the robust behavior of mobile robots in the presence of external perturbations. This hierarchical progressive control architecture is demonstrated through simulation verification.
The main contributions of this work can be summarized as follows:
● A nonlinear observer is designed to accurately estimate the unavailable robot states while maintaining robustness against external disturbances.
● A bioinspired distributed control strategy is developed to mitigate sudden surges in velocity commands caused by initial tracking errors and to enforce velocity constraints imposed by the robots' physical limits.
● The overall formation control framework is theoretically proved to be stable, ensuring robustness and convergence of the multiple mobile robot system under disturbances.
The rest of the paper is as follows: Section 2 provides the communication model and the dynamic equations of the individual mobile robot. Then, Section 3 derives the distributed estimation method, state observer, and controllers with proved stability. After that, multiple simulation studies have demonstrated that the proposed distributed formation framework yields apparent advantages over the conventional method in Section 4. Finally, the conclusion is provided to emphasize the contribution of this study and to list some potential future work that can be done.
2. PRELIMINARIES AND PROBLEM STATEMENT
2.1. Communication topology
In this study, the communication relationship of a multi-robot system is mathematically modeled using graph theory. It is defined as follows: the system contains
Lemma 1. Matrix
2.2. Problem statement
In this study, the general structure of the mobile robot is shown in Figure 1. It is assumed that all robots share a similar structure, with the front wheel being passive and the two rear wheels being driven. There are a total of
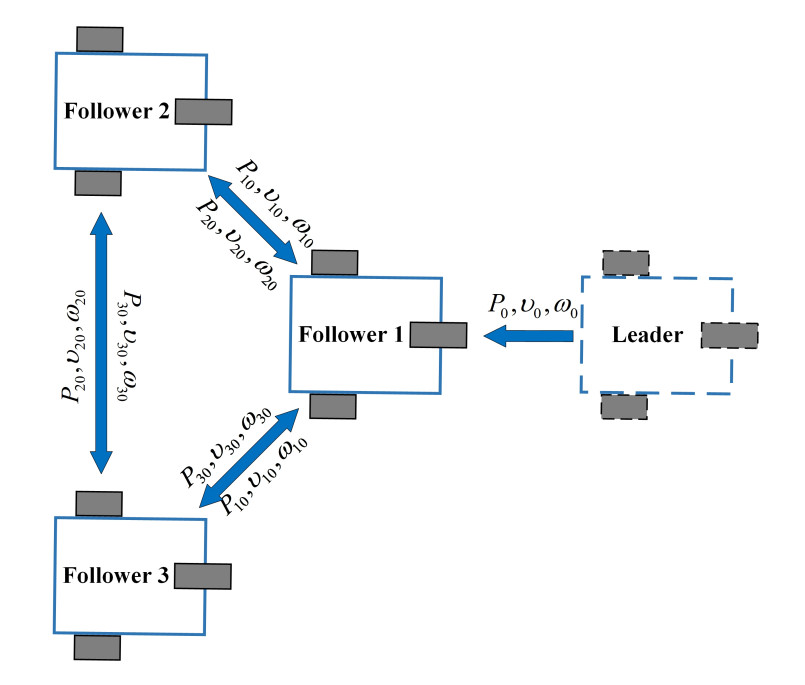
Figure 1. Mobile robot communication networks.
where
Then, define leader's linear and angular velocities as
Each mobile robot follows the dynamic model formulated in the following state-space representation [27]
where
This paper aims to present a control approach enabling multiple mobile robots to track the leader while preserving relative positions. The distance between the
3. FORMATION CONTROL DESIGN
In order to realize consensus among mobile robots, a distributed formation control strategy is developed in this section. Initially, a distributed observer is constructed to continuously estimate the leader's state using only local neighbor information, ensuring estimation smoothness. Subsequently, an extended nonlinear observer is formulated to reconstruct unknown states and external disturbances. To cope with abrupt changes in speed and enforce velocity limits, a novel kinematic controller based on neural dynamics is employed. Lastly, a dynamic compensation controller is integrated to mitigate the influence of external perturbations and enhance robustness.
3.1. Design of distributed estimator
First, a distributed estimation scheme is constructed using a cascaded design methodology, enabling each follower to precisely estimate the leader's position and velocity without requiring its acceleration information. To allow the estimation in a fully decentralized manner, a velocity estimator is first designed. We define the consensus error of the
where
where
with
where
where
Theorem 1. The estimation error dynamics given in Equations (7) and (8) are asymptotically stable if parameters in Equations (4) and (6) are properly chosen such that
Since the positional state estimation process is cascaded with the velocity estimates, we first need to prove the convergence of
where
where
Combined with the results obtained in Equation (11), Equation (10) it follows from Equation (10) that the following statement holds
where
where
After that, we present Lemma 2 to assist the following analysis.
Lemma 2. Let us consider a scalar differential equation given by
where the function
Then, the conclusion of this lemma holds true regarding the relation between
Therefore, there is
Thus,
where
where
where
3.2. Design of observer
In practical applications involving mobile robots, direct measurements of velocity and external disturbances are often unavailable, despite their importance for achieving desirable control performance. To address this limitation, a nonlinear extended state observer is constructed in this subsection to estimate both quantities with high accuracy. The design builds upon the system dynamics given in Equation (2). Denote
with
To enable real-time estimation of disturbances and velocities, we construct the following nonlinear state observer as
where
By subtracting Equation (25) from Equation (21), the estimation error dynamics is calculated as
We next formulate a theorem to ensure the stability of the designed nonlinear observer.
Theorem 2. Based on Assumptions 2, the error dynamics defined in Equation (27) converges to zero as
We select
Thus, we can infer that as long as
3.3. Bioinspired kinematic controller design
A bioinspired neural-dynamics-assisted kinematic controller is proposed in this section for formation control. The tracking error of the
where
where
where
Based on the error dynamics presented in Equation (31), the kinematic controller is subsequently formulated to regulate the formation behavior as
where
where
After designing the bioinspired controller, a torque controller is further developed to generate torque commands and compensate for external disturbances. Using the defined velocity error and given the dynamics of the mobile robot in Equation (2), we subsequently formulate the control law as
where
Algorithm 1 Nonlinear Observer-based Bioinspired Formation Control Algorithm 1. For each individual mobile robot 2. Initialize the parameters of the estimator, observer, and controller; correctly initialize the shunting-model state and the estimator's state variables. 3. while The formation objective is not complete do (a) Acquire the neighbors' measurements (b) Estimate the leader's state (c) Obtain a sample of (d) Apply the kinematic control input (e) Actuate the system with end while
3.4. Stability analysis
This section presents a comprehensive analysis of the closed-loop stability of the proposed control scheme.
Lemma 3.[10] Define
where both
We begin by examining the convergence of the velocity error dynamics. To this end, let us define the error between the actual velocity and the commanded velocity as
where
where
Following this, we shift focus to the kinematic controller. A Lyapunov function is proposed to analyze its convergence properties, defined as
The time derivative of
where
with
Based on Equation (4) and by ensuring
Then, we have
Since we have proof the convergence of
4. SIMULATION RESULTS
To verify the capability of the proposed neurodynamic observer-controller framework, several evaluation scenarios are introduced in this section. The main objective of the proposed control method is to allow each follower to maintain relative posture with the virtual leader. The simulation scenario includes a leader-follower setup composed of one leader and three follower agents. The corresponding communication topology is illustrated in Figure 1. As part of the simulation setup, a virtual leader is assigned a predefined trajectory given by
To show the effectiveness of the proposed control, Figure 2 clearly indicates that the proposed method is capable of keeping its desired distance from the leader. Furthermore, Figure 3 further demonstrates the convergence of the estimation error from the distributed estimator. As can be seen in the zoomed-in figure in Figure 4, the conventional distributed estimator (CDE) results in discontinuities in the control command, which will consequently yield discontinuities in the torque control command. Furthermore, compared with sliding mode control (SMC), the bioinspired method offers a smoother control command without speed jump, which undoubtedly offers a better control performance. Overall, the proposed distributed method allows a smooth transition in the leader's velocity estimates, which is crucial to ensure overall formation performance.
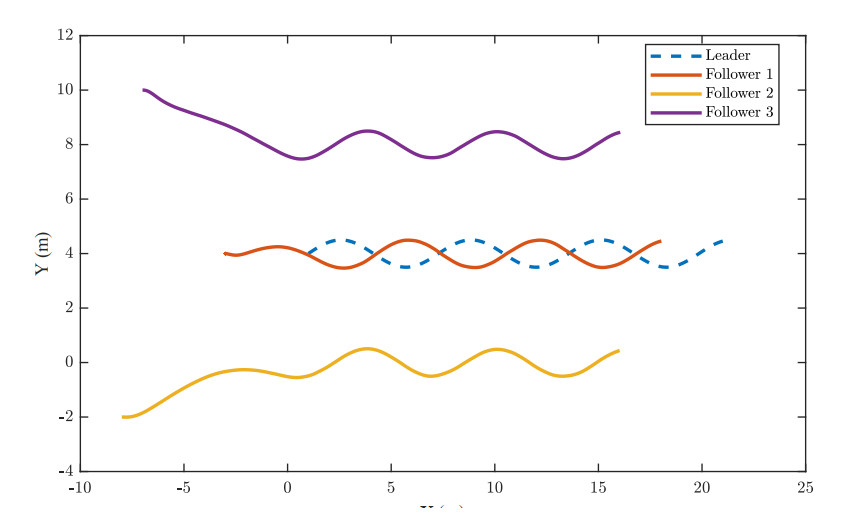
Figure 2. Positions of mobile robots using bioinspired distributed approach.
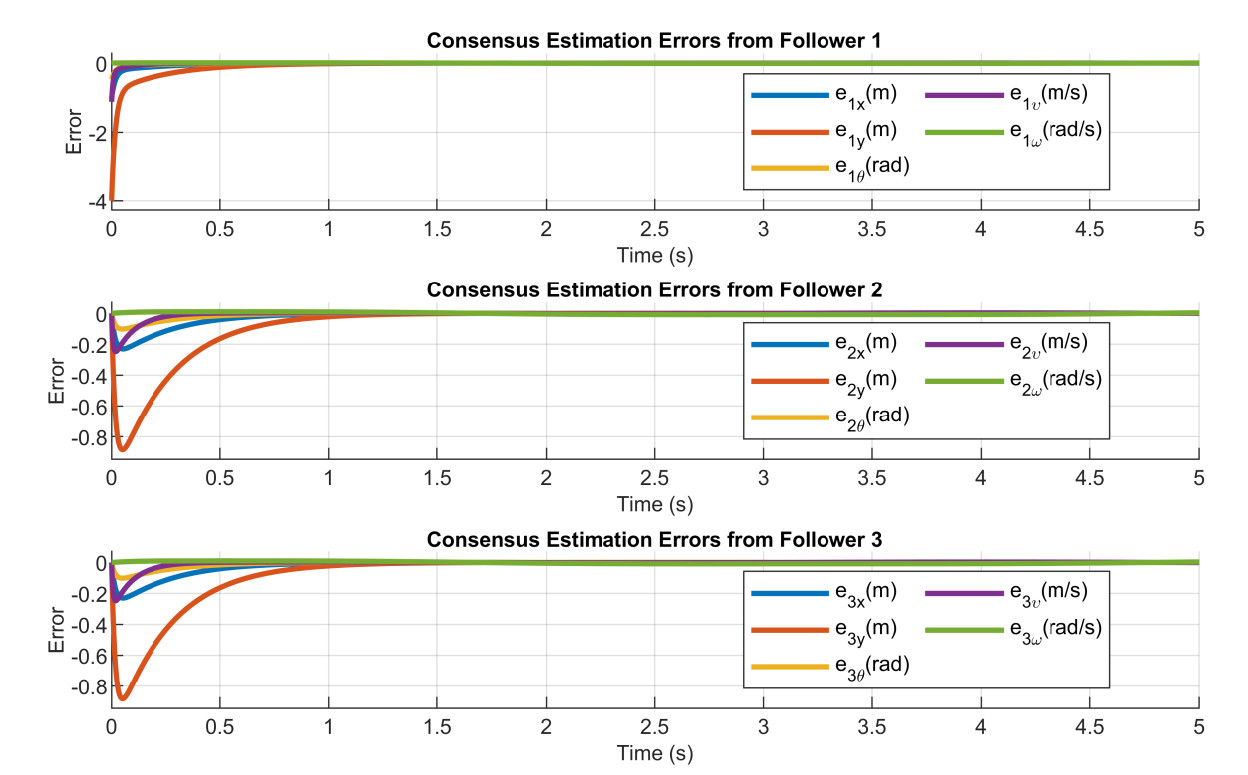
Figure 3. Consensus estimation error from the distributed estimator.
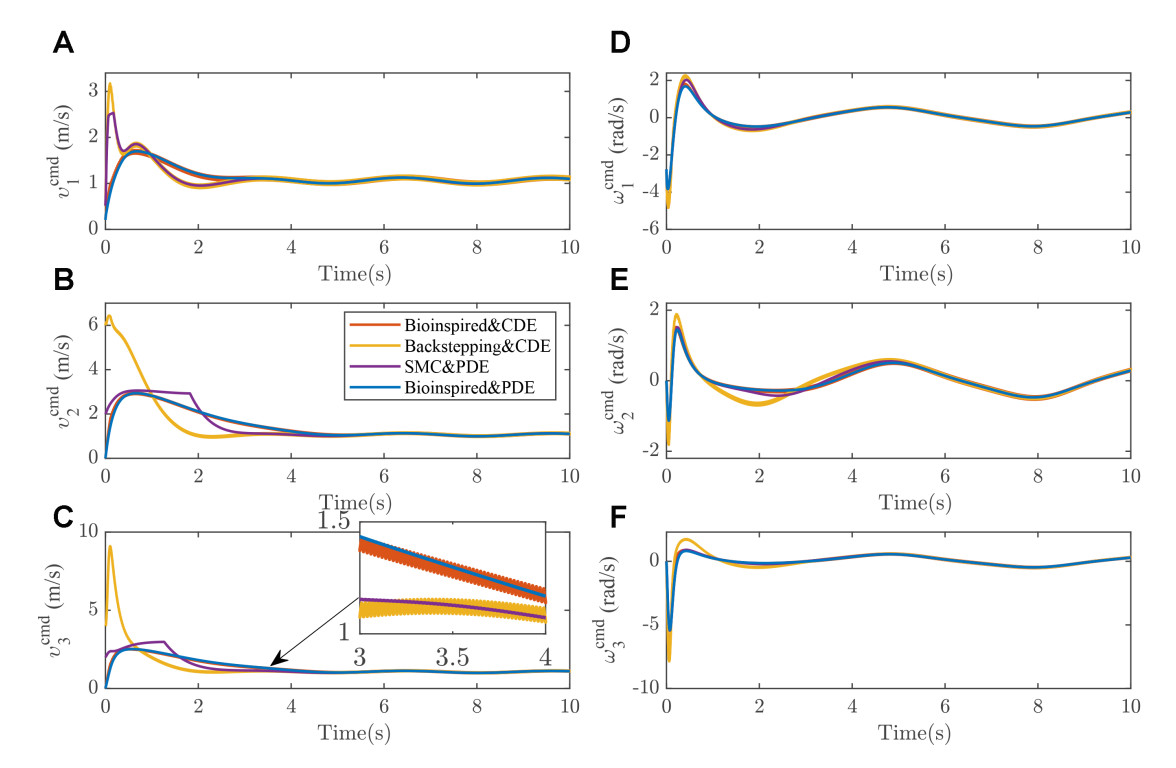
Figure 4. Velocity command generated from the velocity controller. (A-C) Linear velocity command; (D-F): Angular velocity command. CDE: Conventional distributed estimator; SMC: sliding mode control; PDE: proposed distributed estimator.
With the implementation of the neurodynamic-based controller, the speed jump issue is clearly avoided. If the initial tracking error in the driving direction is not zero, the velocity command will not be zero in the conventional approach. However, the bioinspired control method allows the initial velocity command to start from zero, allowing a lower torque command. Due to the bounded nature of the bioinspired neural dynamics, compared with the bioinspired method, the maximum velocity command from the conventional method reaches a maximum velocity of over 10m/s, which is apparently impractical.
Figure 5 illustrates the state estimation results obtained from the proposed nonlinear extended state observer. Since the velocity states are not directly measurable, the observer effectively reconstructs both the unmeasured states and external disturbances with high accuracy. As seen in Figure 5, the estimated disturbances closely match the true values, demonstrating the observer's strong estimation capability. Without this critical disturbance information, the overall formation performance would deteriorate significantly.
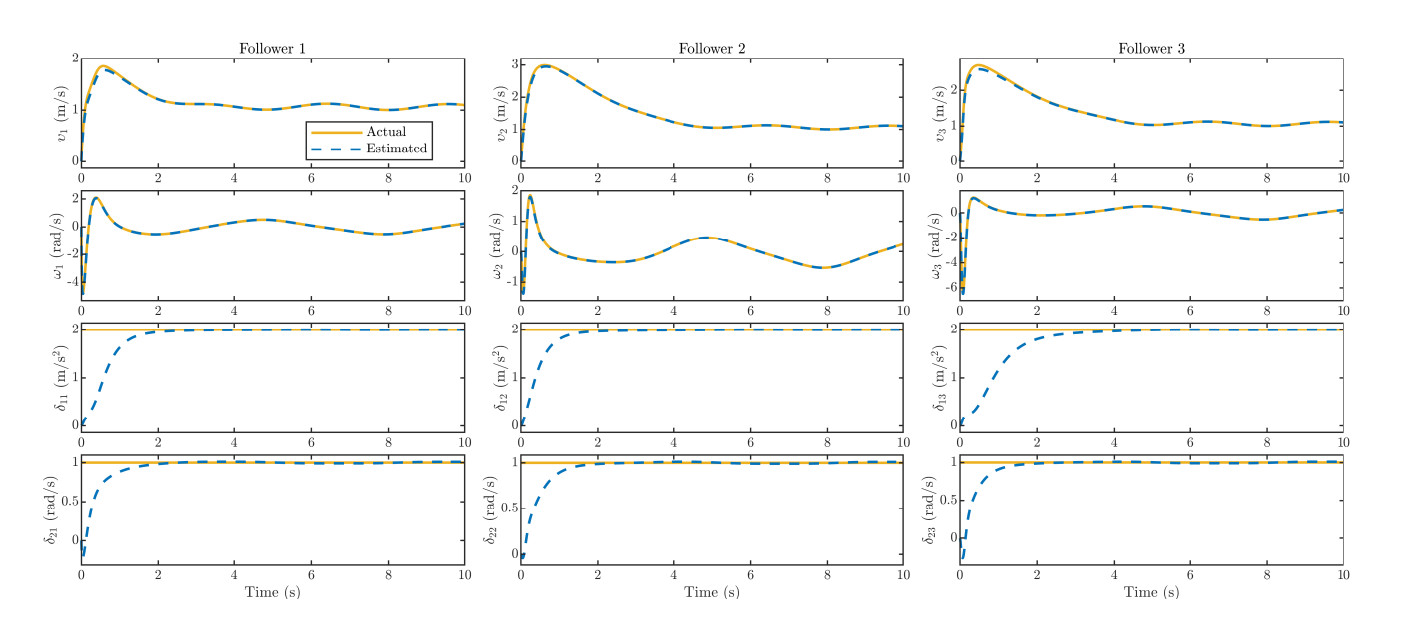
Figure 5. Velocity and disturbance estimates of each follower.
Moreover, the proposed nonlinear observer provides continuous and smooth state estimates, which enable the torque controller to generate smooth control inputs. Figure 6A-C compares the formation performance with and without the nonlinear state observer, showing that its inclusion leads to markedly improved tracking and formation stability. In Figure 6D-F, Gaussian-type noise is introduced into the inter-robot communication channels. Even under such noise, the proposed bio-inspired control law maintains smooth linear velocity outputs. This robustness arises from the bio-inspired neural dynamics given in Equation (35), which inherently act as a low-pass filter, effectively attenuating high-frequency noise and preserving continuous, noise-resilient control actions. As a result, the overall formation system exhibits improved robustness and smoother cooperative motion.
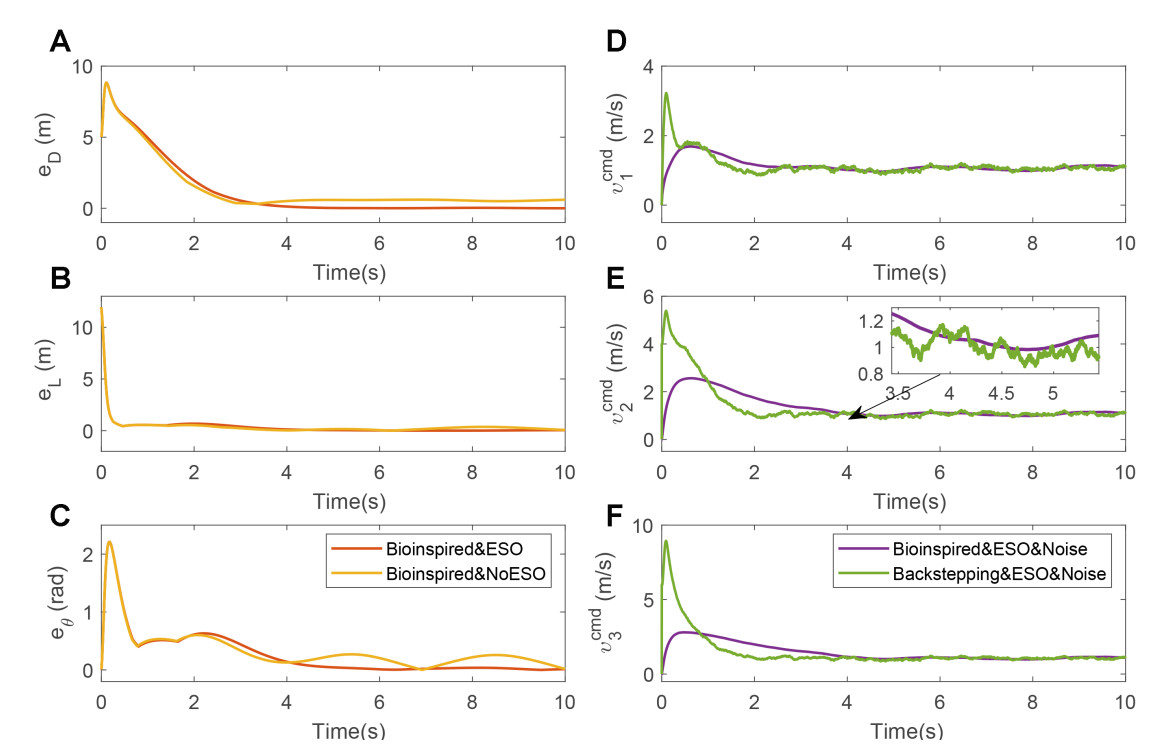
Figure 6. Tracking error with and without nonlinear state estimator (A) Tracking error in the driving direction; (B) Tracking error in the lateral direction; (C) Tracking error in the orientation; (D) Velocity command of Follower 1; (E) Velocity command of Follower 2; (F) Velocity command of Follower 3. ESO: Extended State Observer.
5. CONCLUSION
This work focuses on achieving robust formation coordination for multiple mobile robots in environments where velocity measurements are not directly accessible and external disturbances are present. To address these challenges, we construct an integrated control architecture combining distributed observation and biologically inspired coordination mechanisms. The strategy begins with a distributed estimation process that enables each robot to recover the leader's motion state continuously using only local communication. Building on these estimates, a bioinspired kinematic mechanism is introduced to generate smooth and bounded velocity commands, effectively mitigating abrupt transitions and enforcing motion constraints. To compensate for unknown dynamics and measurement uncertainties, a nonlinear observer is incorporated to estimate both actual velocities and disturbance terms. These inferred states are then fed into a robust torque-level controller tailored to maintain the formation under adverse conditions. Theoretical analysis confirms that the overall framework guarantees convergence and disturbance resilience, while numerical experiments illustrate that high-precision formation can be sustained even in the presence of significant uncertainty.
DECLARATION
Authors' contributions
Idea generation, algorithm design, and writing and editing of the original draft: Xu, Z.
Simulation and writing of the original draft: Xia, Z.
Supervision and feedback: Li, W.; Yang, S. X.
Availability of data and materials
The data supporting the conclusions of this article will be made available by the authors upon request.
AI and AI-assisted tools statement
During the preparation of this manuscript, the AI tool Chatgpt (Version 4.5, released 2025-02-27) was used solely for language editing. The tool did not influence the study design, data collection, analysis, interpretation, or the scientific content of the work.
Financial support and sponsorship
This work is supported by the Guangxi Zhuang Autonomous Region Key Research and Development Program (Project NO.AB22035023).
Conflict of interest
Yang, S. X. is the Editor-in-Chief of the journal Intelligence & Robotics. Yang, S. X. was not involved in any steps of the editorial process, notably including reviewer selection, manuscript handling, or decision-making. The other authors declare that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Hu, J.; Liu, W.; Zhang, H.; Yi, J.; Xiong, Z. Multi-robot object transport motion planning with a deformable sheet. IEEE. Robot. Autom. Lett. 2022, 7, 9350-7.
2. Macwan, A.; Vilela, J.; Nejat, G.; Benhabib, B. A multirobot path-planning strategy for autonomous wilderness search and rescue. IEEE. Trans. Cybern. 2015, 45, 1784-97.
3. Lashkari, N.; Biglarbegian, M.; Yang, S. X. Development of a novel robust control method for formation of heterogeneous multiple mobile robots with autonomous docking capability. IEEE. Trans. Autom. Sci. Eng. 2020, 17, 1759-76.
4. Li, Q.; Zhuo, Z.; Gao, R.; et al. A pig behavior-tracking method based on a multi-channel high-efficiency attention mechanism. Agric. Commun. 2024, 2, 100062.
5. Wen, J.; Yang, J.; Li, Y.; He, J.; Li, Z.; Song, H. Behavior-based formation control digital twin for multi-AUG in edge computing. IEEE. Trans. Netw. Sci. Eng. 2023, 10, 2791-801.
6. Tan, G.; Zhuang, J.; Zou, J.; Wan, L. Coordination control for multiple unmanned surface vehicles using hybrid behavior-based method. Ocean. Eng. 2021, 232, 109147.
7. Bautista, J.; de Marina, H. G. Behavioral-based circular formation control for robot swarms. In 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, May 13-17, 2024. IEEE, 2024; pp. 8989–95.
8. Xu, Z.; Yan, T.; Yang, S. X.; Gadsden, S. A.; Biglarbegian, M. Distributed robust learning based formation control of mobile robots based on bioinspired neural dynamics. IEEE. Trans. Intell. Veh. 2024, 20, 1180-9.
9. Zhao, W.; Liu, H.; Lewis, F. L.; Wang, X. Data-driven optimal formation control for quadrotor team with unknown dynamics. IEEE. Trans. Cybern. 2022, 52, 7889-98.
10. Moorthy, S.; Joo, Y. H. Distributed leader-following formation control for multiple nonholonomic mobile robots via bioinspired neurodynamic approach. Neurocomputing 2022, 492, 308-21.
11. Guo, J.; Liu, Z.; Song, Y.; Yang, C.; Liang, C. Research on multi-UAV formation and semi-physical simulation with virtual structure. IEEE. Access. 2023, 11, 126027-39.
12. Villa, D. K. D.; Brandão, A. S.; Sarcinelli-Filho, M. Cooperative load transportation with quadrotors using adaptive RISE control. J. Intell. Robot. Syst. 2024, 110, 138.
13. Moreira, M. S. M.; Villa, D. K. D.; Sarcinelli-Filho, M. Controlling a virtual structure involving a UAV and a UGV for warehouse inventory. J. Intell. Robot. Syst. 2024, 110, 121.
14. Luo, D.; Wang, Y.; Li, Z.; Song, Y.; Lewis, F. L. Asymptotic leader-following consensus of heterogeneous multi-agent systems with unknown and time-varying control gains. IEEE. Trans. Autom. Sci. Eng. 2024, 22, 2768-79.
15. Li, B.; Gong, W.; Yang, Y.; Xiao, B. Distributed fixed-time leader-following formation control for multi-quadrotors with prescribed performance and collision avoidance. IEEE. Trans. Aerosp. Electro. Syst. 2023, 59, 7281-94.
16. Zhao, X. W.; Li, M. K.; Lai, Q.; Liu, Z. W. Neurodynamics-based formation tracking control of leader-follower nonholonomic multiagent systems. Intell. Robot. 2024, 4, 339-62.
17. Li, J.; Xu, Z.; Zhu, D.; et al. Bio-inspired intelligence with applications to robotics: a survey. Intell. Robot. 2021, 1, 58-83.
18. Hou, R.; Cui, L.; Bu, X.; Yang, J. Distributed formation control for multiple non-holonomic wheeled mobile robots with velocity constraint by using improved data-driven iterative learning. Appl. Math. Comput. 2021, 395, 125829.
19. Liu, Z. Q.; Ge, X.; Xie, H.; Han, Q. L.; Zheng, J.; Wang, Y. L. Secure leader-follower formation control of networked mobile robots under replay attacks. IEEE. Trans. Ind. Informatics. 2024, 20, 4149-59.
20. Han, Z.; Wang, W.; Ran, M.; Wen, C.; Wang, L. Switching-based distributed adaptive secure formation control for mobile robots with denial-of-service attacks. IEEE. Trans. Syst. Man. Cybern. Syst. 2024, 54, 4126-38.
21. Zhao, Z.; Li, X.; Liu, S.; Zhou, M.; Yang, X. Multi-mobile-robot transport and production integrated system optimization. IEEE. Trans. Autom. Sci. Eng. 2024, 22, 7480-91.
22. Rosenfelder, M.; Ebel, H.; Eberhard, P. Cooperative distributed nonlinear model predictive control of a formation of differentially-driven mobile robots. Robot. Auton. Syst. 2022, 150, 103993.
23. Peng, J.; Xiao, H.; Lai, G.; Chen, C. L. P. Consensus formation control of wheeled mobile robots with mixed disturbances under input constraints. J. Franklin. Inst. 2024, 361, 107300.
24. Chang, S.; Wang, Y.; Zuo, Z.; Yang, H. Fixed-time formation control for wheeled mobile robots with prescribed performance. IEEE. Trans. Control. Syst. Technol. 2022, 30, 844-51.
25. Yang, J.; Yu, H.; Xiao, F. Hybrid-triggered formation tracking control of mobile robots without velocity measurements. Int. J. Robust. Nonlinear. Control. 2022, 32, 1796-827.
26. Liu, W.; Wang, X.; Li, S. Formation control for leader-follower wheeled mobile robots based on embedded control technique. IEEE. Trans. Control. Syst. Technol. 2023, 31, 265-80.
27. Dai, S. L.; He, S.; Chen, X.; Jin, X. Adaptive leader-follower formation control of nonholonomic mobile robots with prescribed transient and steady-state performance. IEEE. Trans. Ind. Informat. 2020, 16, 3662-71.
28. Chen, M.; Ge, S. S.; Ren, B. Adaptive tracking control of uncertain MIMO nonlinear systems with input constraints. Automatica 2011, 47, 452-65.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Data & Comments
Data
0













Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].