



Bio-integrated systems for silent speech recognition: from advanced bioplatforms to machine learning-assisted biosignal decoding
 0
0 Abstract
Silent speech interfaces decode intended speech from physiological signals without the need for vocalized sound. These systems provide an alternative modality to voice-based spoken communication, addressing limitations posed by physiological constraints and environmental interferences. This review presents a comprehensive overview of bio-integrated systems for silent speech recognition, with emphasis on their physiological relevance, state-of-the-art hardware designs, signal characteristics, and machine learning (ML)-assisted speech decoding pipelines. Based on the level of physical intrusion into the body, bio-integrated speech interfaces can be categorized into epidermal, intraoral, and surgically embedded systems. Each modality captures distinct physiological signals involved in speech production. The design of bio-integrated systems involves critical trade-offs among recognition accuracy, invasiveness, portability, and robustness. Recent advances in flexible and stretchable electronics have significantly enhanced device comfort, signal quality, and integration level across these modalities. This review also outlines recent progress in ML-assisted signal processing pipelines, including preprocessing, feature extraction, ML model architectures, and evaluation metrics. Both signal-to-text and signal-to-audio approaches are discussed. Finally, application scenarios such as assistive communication, human-machine interaction, and user authentication are introduced, followed by an outlook on current challenges and emerging research directions that position this field for transformative clinical and consumer applications.
Keywords
INTRODUCTION
Spoken communication, being one of the most intuitive means of communication, plays a vital role in conveying information between humans and between humans and machines. However, it is susceptible to both physiological constraints and environmental interferences[1]. From a physiological perspective, speech generation involves a complex coordination of multiple organs that are responsible for phonation, articulation, resonance, and auditory perception, including the lungs, larynx, tongue, lips, teeth, jaws, and ears[2,3]. Any disruption to these organs can impact speech or hearing abilities and potentially lead to voice disorders or hearing impairments[4], thus reducing communication efficiency in both human-human and human-machine interactions (HMIs). On the other hand, environmental interferences present additional challenges. For instance, noisy surroundings (e.g., acoustically harsh workplaces, crowded gatherings, or background noise from televisions), situations requiring privacy or silence (e.g., hospitals, public areas, or confidential communications), and environments lacking adequate acoustic transmission (e.g., underwater or outer space) often impose limitations on voice-based speech communications[5,6].
Augmentative and alternative communication (AAC) systems provide communication methods beyond vocalized speech[7] to help overcome physiological and environmental challenges for vocalized speech. However, communication rates for many AAC devices, such as those based on sign language recognition[8] or eye movement detection[9], remain slower than natural speech. Silent speech interfaces (SSIs) emerge as a promising solution to bridge this communication gap, offering the potential for near-natural communication rates. SSIs are electronic systems that capture speech-related physiological signals and employ decoding algorithms to translate these signals into communication outputs such as text or acoustic sound, eliminating the need for human vocal sound. Such interfaces have long been pursued to assist people with voice disorders caused by diseases, laryngectomy, accidents, vocal abuse, or aging[10-12]. Meanwhile, SSIs are preferred over vocalized speech in various scenarios when the acoustic signal is unreliable, secure communications are desirable, or when vocalized speech is socially inappropriate or disruptive to others. For instance, research has found that users are more comfortable using silent speech than vocalized speech in both public and private settings, and they can even tolerate higher error rates to maintain privacy and security[13].
To fully appreciate the advancements in bio-integrated silent speech recognition, it is essential to consider the broader technological landscape. Non-contact systems that employ technologies such as wireless signal reflection, ultrasound imaging, and camera-based interfaces capture speech-related articulatory movements from a distance. These modalities offer valuable baselines for system performance and user comfort. At the same time, they introduce operational constraints, including strict reliance on line-of-sight, sensitivity to ambient lighting, and reduced privacy in public spaces. This comparative background underscores the primary motivation for developing bio-integrated systems. By maintaining direct physical coupling with the user, bio-integrated platforms successfully overcome the environmental vulnerabilities of non-contact methods, ultimately enabling continuous, portable, and private speech decoding in dynamic daily settings.
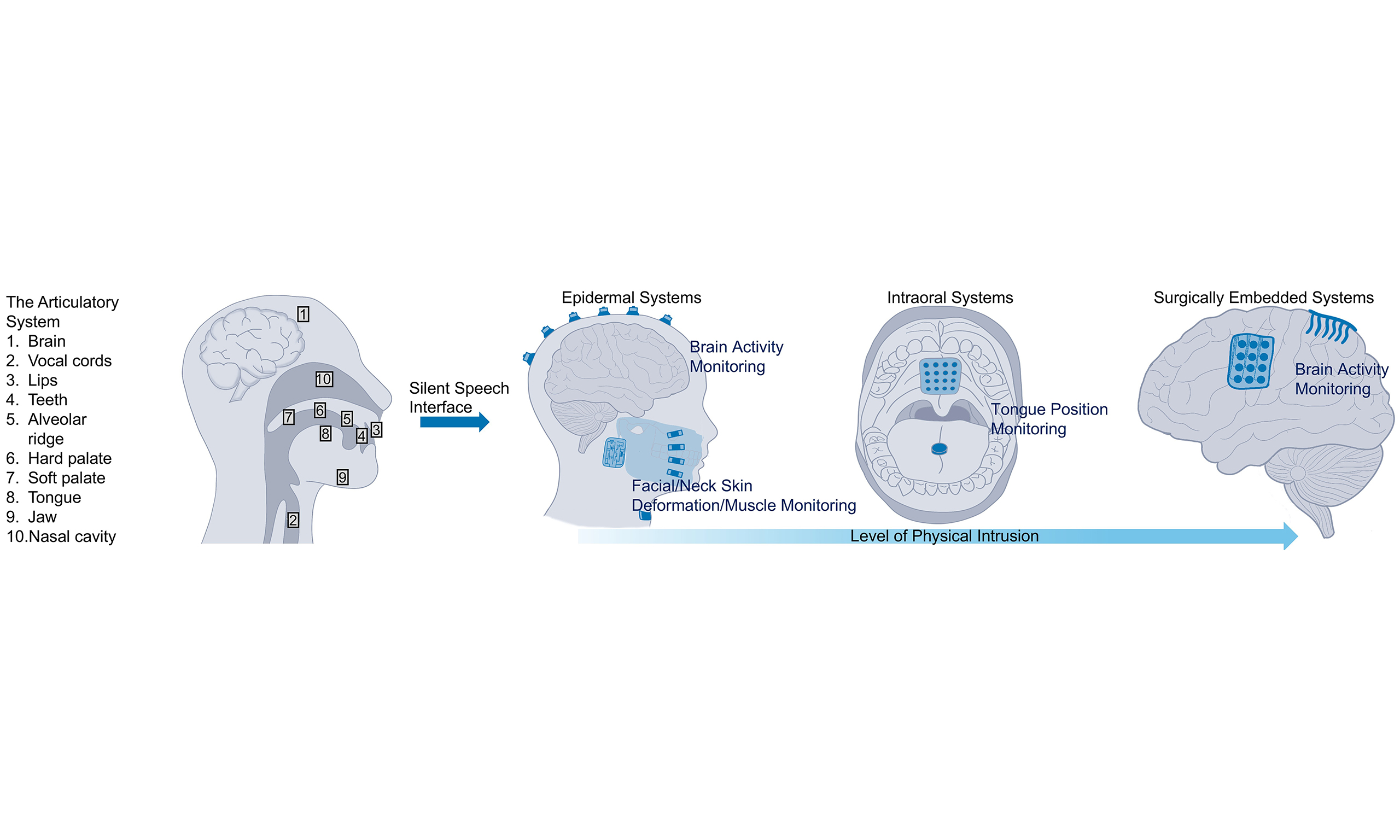
In SSIs, bio-integrated systems that are attached to the body surface or embedded within internal structures are crucial for capturing signals associated with speech, such as muscular activities, articulator movements, or neural activities[4,14,15]. Depending on how these bio-integrated systems interact with the human body, they can be classified into three categories: epidermal, intraoral, and surgically embedded systems. Each category exhibits distinct physical placement and level of integration with the body, which directly influences their user acceptance, invasiveness, signal fidelity, robustness, and suitability for different user groups, including both healthy individuals and voice-impaired patients. Recent breakthroughs in flexible and stretchable electronics have substantially improved the performance of bio-integrated hardware for SSIs, particularly for epidermal systems[16]. These devices have also shown great potential for enhancing intraoral and surgically embedded systems. For epidermal systems, flexible and stretchable devices that employ soft materials and/or deformable structures are gently attached to skin surfaces, enabling the reliable acquisition of muscular, deformation, or acoustic signals during articulation[17]. For instance, thin, stretchable, and high-density electromyography (EMG) patches built with breathable elastomers have been demonstrated to have low skin-electrode impedance under large deformations, boosting both comfort and signal quality for SSIs[18]. Intraoral systems are designed to monitor articulatory movements within the oral cavity, offering closer access to the tongue, a primary articulator in speech production[19]. These intraoral systems can benefit from wireless flexible devices that laminate onto dental appliances or palatal structures, enabling unobtrusive tongue-motion sensing without bulky wiring[20]. For neural interfacing, surgically embedded systems have been explored, offering high-resolution signals through direct interface with the brain[21]. Soft, polymer-based bioelectronic interfaces have emerged to address the mechanical mismatch between rigid implants and soft brain tissues, thereby improving mechanical compliance, reducing foreign body response, and maintaining long-term recording stability[17].
Signal processing is essential for translating biosignals acquired by bio-integrated systems into linguistic outputs. A typical processing pipeline involves several sequential steps: preprocessing, feature extraction, model inference, and evaluation. The preprocessing stage mitigates noise sources, such as motion artifacts and powerline interference, using techniques such as bandpass and notch filtering[22,23]. To ensure generalizability across users and sessions, normalization and synchronization are applied to align signal amplitudes and temporal structures for consistent analysis, especially in multimodal systems. Segmentation further structures continuous inputs into phoneme- or word-level units to improve modeling efficiency and accuracy. Following preprocessing, feature extraction converts signals into structured representations using either handcrafted metrics or deep-learning-generated features. Convolutional neural networks (CNNs) have proven effective for extracting spatial and temporal features from 2D and 3D inputs such as spectrograms or lip videos[24,25]. These features are then fed into classification architectures ranging from conventional hidden Markov models (HMM) and Gaussian mixture models (GMM) to recurrent neural networks (RNNs) and Transformer-based frameworks[26-29]. Depending on the application, SSIs may target signal-to-text or signal-to-audio outputs, with corresponding evaluation metrics such as word error rate (WER) and phone error rate (PER)[21,30]. Altogether, the processing pipeline determines system accuracy, adaptability, and deployment feasibility in real-world SSI applications.
This review aims to provide a comprehensive overview of bio-integrated SSIs - crucial and emerging systems for restoring or enhancing natural spoken communications - with a focus on working principles, state-of-the-art hardware developments, signal characteristics, and ML-assisted signal processing pipelines. Unlike previous surveys[4,31] that primarily focused on basic principles and early prototypes, this review delivers three key differentiating contributions. First, we present a systematic comparison of diverse sensing modalities (epidermal, intraoral, and surgically embedded systems), their distinct signal characteristics, and corresponding device architectures, providing quantitative benchmarks across portability, invasiveness, sensor configurations, and recognition accuracy. Second, we comprehensively analyze recent breakthroughs in hardware design, particularly highlighting how emerging flexible and stretchable sensor technologies improve user comfort and signal fidelity compared to conventional rigid systems. Third, we highlight recent advanced ML algorithms that enable sophisticated decoding capabilities, including open-vocabulary recognition in surgically embedded neural interfaces. This paper begins with an introduction to fundamental speech generation and recognition processes, followed by a detailed analysis of different sensing modalities, including epidermal, intraoral, and surgically embedded systems. The review further outlines the ML-assisted signal processing pipelines of silent speech-related temporal signals. Representative studies are critically compared across both hardware design (e.g., portability, invasiveness, and channel configurations), as well as software performance indicators (e.g., recognition accuracy and task complexity). In the following section, practical applications of SSIs are briefly reviewed. Finally, the review concludes with an outlook on current challenges and emerging trends in SSI research.
DECODING SILENT INTENT: THE PHYSICS AND PIPELINES OF SSIs
Articulation mechanics: from speech intention and articulatory movements to bio-signals
This section provides an overview of SSIs from the perspectives of the speech production process (Section 2.1) and the speech recognition process (Section 2.2); detailed coverage of state-of-the-art technologies follows in subsequent sections. As depicted in Figure 1A, the process of speech production is a multi-stage process in which various organs perform crucial functions in the generation of speech. Even in the absence of the final acoustic output, diverse methodologies can be employed to monitor the behaviors of these organs and subsequently translate them into speech, thereby enabling silent speech recognition (SSR)[10,31,33].
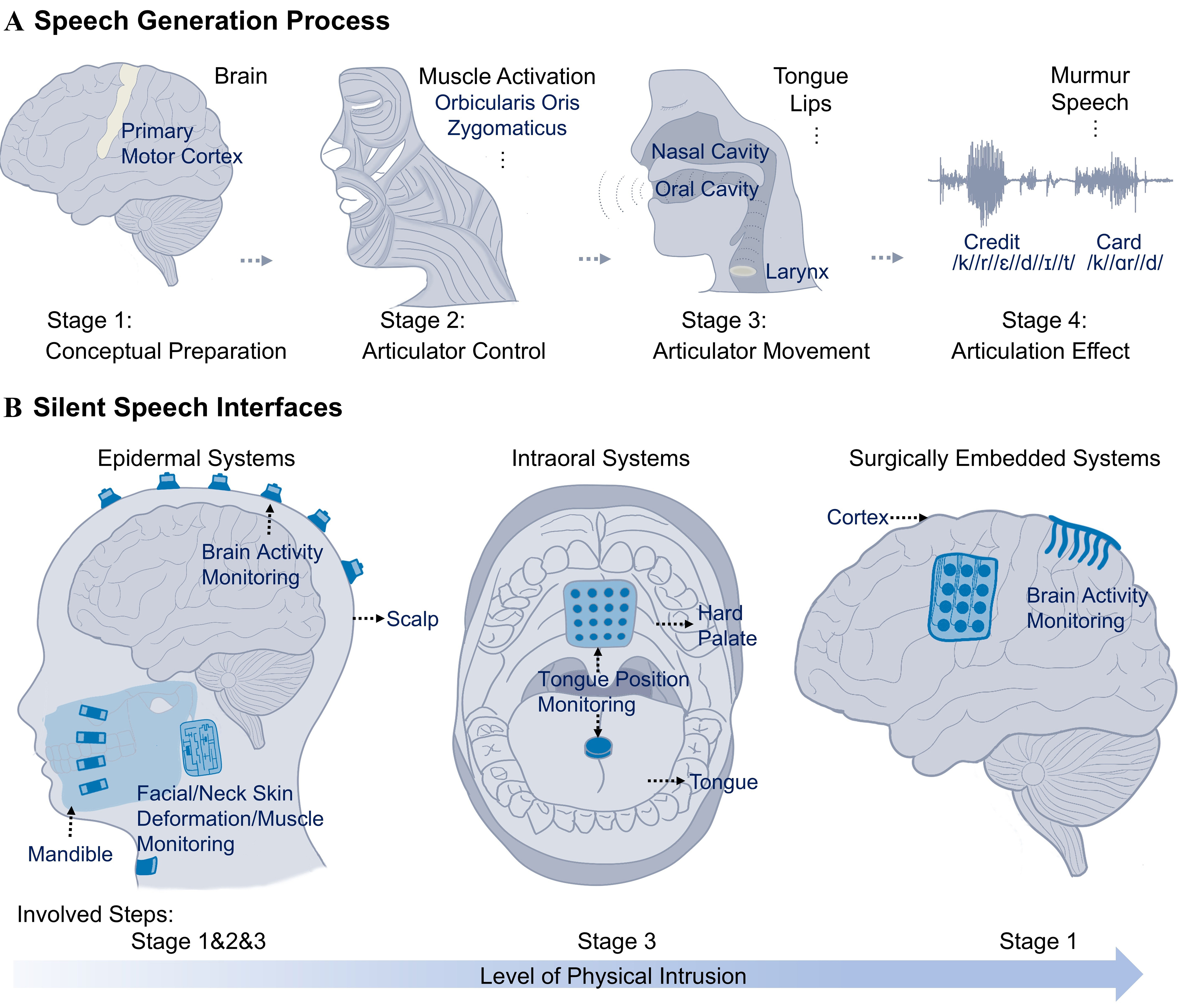
Figure 1. Overview of the speech generation process and silent speech interfaces. (A) Four stages of the speech generation process, following the process described in Ref. [31]. The figure that depicts stage 2 is adapted from Ref. [32], under CC BY 4.0 license; (B) Three categories of SSIs: epidermal, intraoral, and surgically embedded systems. These systems are classified by the level of physical intrusion into the human body. SSIs: Silent speech interfaces.
In the first stage in Figure 1A, the human brain handles conceptual preparation, forming speech intentions that will later be translated into motor commands. Studies have shown that the electrical activity of the cerebral cortex correlates highly with intended speech[34,35]. Specifically, the primary motor cortex controls the precise movements of orofacial and laryngeal muscles needed for articulation[36]. Accordingly, non-invasive epidermal systems such as skin-mounted electroencephalography (EEG) sensors can capture these cortical signals for SSR. Surgically embedded systems like electrocorticography (ECoG)[37-39] can access such signals closer to their source, achieving finer spatial resolution and higher signal-to-noise ratio (SNR), albeit with greater invasiveness [Figure 1B].
For the second stage in Figure 1A, cortical signals travel down along the nerve pathways to the brainstem and then to the orofacial/laryngeal muscles[40]. These muscles control the articulators to produce words or sentences composed of sequences of phonemes (distinct units of sound in a given language)[41]. During silent speech, orofacial muscles (such as those controlling the lips, tongue, and jaws) continue to move, while laryngeal muscles (located in the voice box) are partially activated due to the absence of voice generation. Nonetheless, these laryngeal muscles still provide valuable information. Thus, epidermal systems [Figure 1B] such as EMG[12,42-44] can be attached to the facial skin or skin near the throat to monitor muscular activities by collecting biopotentials during silent speech.
As shown in the third stage of Figure 1A, activated muscles drive the movement of articulators. This stage encompasses various somatosensory organs or anatomical structures such as vocal cords, lips, teeth, palate, tongue, and jaws. Therefore, SSR can be realized by monitoring the movements of these organs or structures. For instance, the temporomandibular joint (TMJ) is moved by the contraction of the masseter, a jaw muscle that controls the movement of the mandible (lower jaw bone, as shown in Figure 1B under epidermal systems)[45]. During this process, epidermal systems such as inertial measurement units (IMUs)[3,46,47] can capture these articulator movements through physical parameters such as acceleration and angular velocity, which are closely related to silent speech content. Another key approach for monitoring articulator movement is the intraoral system [Figure 1B], which tracks tongue positions. Trackers such as permanent magnets[19,48-50] and inductance coils[51] are attached to the tongue surface. Their trajectories can be monitored externally to infer tongue movements. Alternatively, a sensor array such as electropalatography (EPG)[52] can be placed on the hard palate to measure the relative position between the tongue and the sensor array. This relative position also conveys silent speech information.
The final stage in Figure 1A involves the cumulative effects of the preceding stages, culminating in the production of acoustic speech signals and various associated effects, such as alterations in facial expressions, vocal tract configuration, as well as non-acoustic murmur. As an effort to capture information during this stage, throat monitoring systems[1,53,54] have been investigated to measure the mechanical movement of the larynx and subtle vibrations of the vocal cords to assist in SSR.
An algorithmic pipeline for silent speech recognition
Beyond device development, researchers have designed numerous preprocessing and signal processing methods based on different types of temporal and image-based signals acquired by SSIs. These approaches draw inspiration from the automatic speech recognition (ASR) domain and adapt established pipelines to the challenges of silent speech. Figure 2 shows a representative recognition process of silent speech.
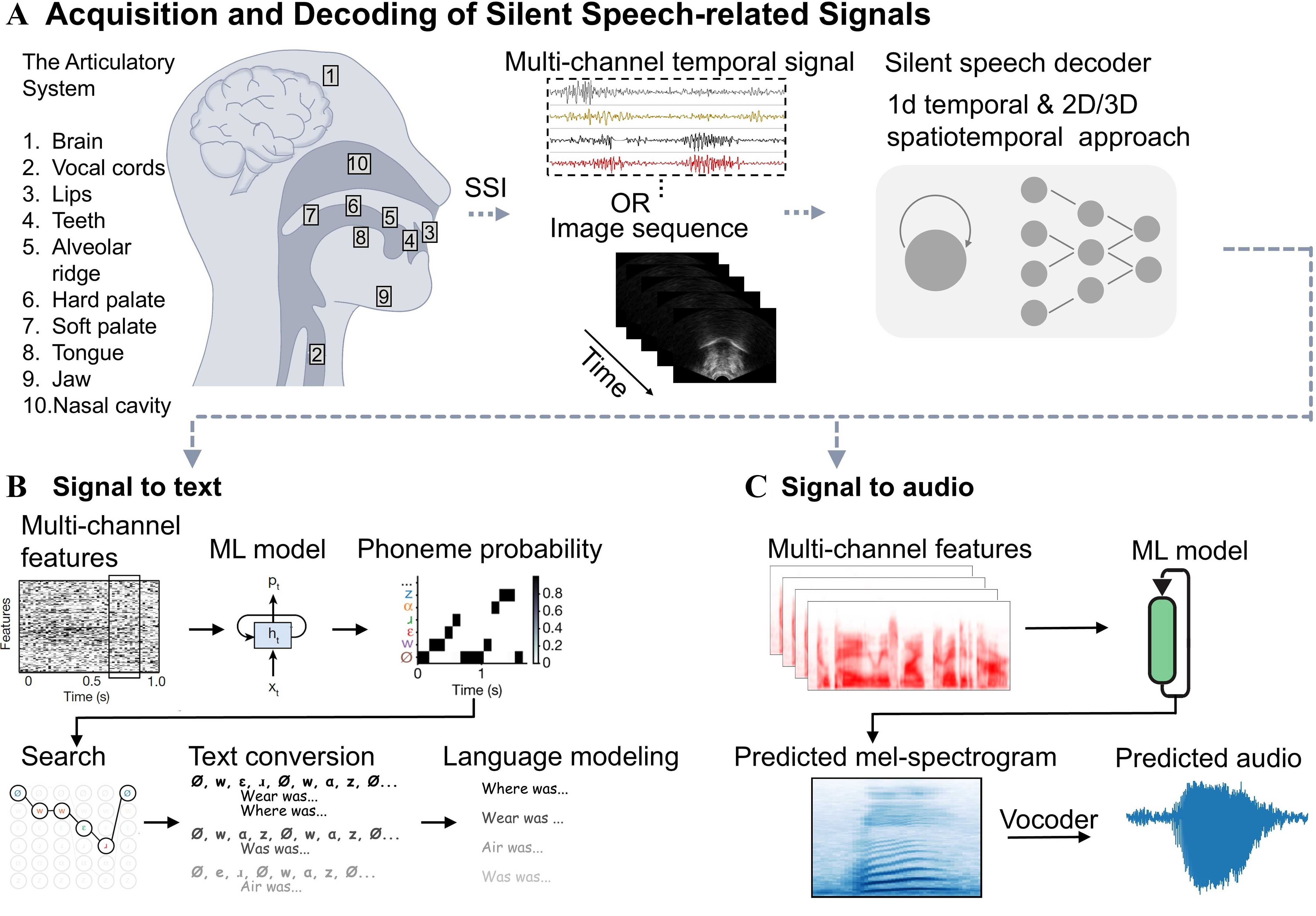
Figure 2. The representative recognition process of silent speech. (A) The sagittal view of the articulatory system and signal acquisition and decoding process for silent speech. This illustration details an algorithmic pipeline for SSIs that employ 1D temporal frameworks (e.g., time-series data like EMG) and/or 2D/3D spatiotemporal frameworks (e.g., image sequences or data from high-density spatial arrays). A representative process for converting silent speech signals into (B) text and (C) speech audio. The schematics in (B) and (C) represent multi-channel features in the time and frequency domains, respectively. Please note that features from both domains are widely utilized in signal-to-text and signal-to-audio conversions. A detailed discussion of decoding models is provided in Section 4. The image sequence in (A): Adapted from Ref. [55], under CC BY 4.0 license. Figure (B) is adapted from Ref. [38], under CC BY 4.0 license. Figure C is adapted from Ref. [56], under CC BY 4.0 license. 1D: One-dimensional; 2D: two-dimensional; 3D: three-dimensional; EMG: electromyography; SSIs: silent speech interfaces; ML: machine learning.
SSIs capture a variety of signals that can be broadly categorized into temporal data (e.g., EMG, EEG, IMU) and image data (e.g., ultrasound or lip video). With the help of various preprocessing methods (such as bandpass filtering and wavelet decomposition[57]) and temporal or vision-based ML methods (such as RNNs[58], transformers[59], and CNNs[60]), the collected signals can be converted into text [Figure 2B] or speech audio [Figure 2C].
For signal-to-text decoding, early systems used extracted features with simple classifiers to recognize a limited word set. While effective at small vocabulary scales, these methods could not perform sentence-level recognition. More advanced pipelines rely on phoneme-level decoding, where multi-channel features are input into an ML model (e.g., RNNs, CTC-based frameworks, or attention-based sequence-to-sequence models) to estimate phoneme likelihoods over time. A language model then searches across these sequences to generate the most probable sentence. This framework allows the decoding of full sentences from continuous input signals, not just isolated words.
For signal-to-audio decoding, the extracted features are typically converted into mel-spectrograms, which require paired biosignal-audio datasets for training. Established neural vocoders (e.g., WaveNet[61], HiFi-GAN[62]) then synthesize intelligible speech audio from the spectrograms. A persistent challenge is the scarcity of aligned biosignal-speech datasets, particularly for individuals with voice disorders who cannot produce parallel acoustic references. This data bottleneck remains a major obstacle for advancing signal-to-audio SSI systems.
THE HARDWARE FRONTIER: ADVANCED BIO-INTEGRATED SYSTEMS FOR SSIs
This section provides a comprehensive overview of the current modalities of SSIs in detail, which can be categorized into three primary categories: epidermal, intraoral, and surgically embedded systems. For each category, we examine the underlying working principles, state-of-the-art hardware developments, and distinctive signal characteristics, with particular attention to biopotential-based and motion-based approaches. This section also provides comparative insights into their respective advantages and limitations, evaluating each modality in terms of channel configuration, recognition performance, wearability, and invasiveness.
Non-invasive and wearable epidermal sensor systems
In this review, epidermal systems for SSIs refer to non-invasive, skin-mounted devices that adhere to the surface of the scalp, face, neck, or jaw to detect speech-related biopotentials or motions. These systems encompass a diverse range of sensing technologies - including EMG, EEG, IMU, strain, and pressure sensors - all of which capture articulatory signals without penetrating the skin.
EMG-based SSIs
EMG-based SSIs capture biopotentials of articulatory muscles during speech production [Figure 1A]. Figure 3A illustrates the working principle of EMG-based SSIs. Skin-mounted EMG electrodes acquire biopotential signals induced by facial and neck muscular activities associated with silent speech[43,65]. In typical bipolar electrode configurations[66], two recording electrodes (one positive and one negative) are placed on the target muscles to measure the voltage difference between them. A third electrode, fixed to a nearby bony area such as the collarbone, serves as a reference ground and provides a stable baseline[22]. Alternatively, monopolar electrode configurations[66] employ a single active (positive) electrode placed on the target muscle and a negative electrode on a nearby bony area. This setup occupies less space on the skin surface, allowing more channels to be placed. To understand EMG-based SSI implementation, it is essential to first examine the nature of the signals being captured. Each muscle fiber produces a brief, spike-shaped action potential. The measured EMG signal is a summation of signals from all muscle fibers within the area beneath the active electrode. During silent speech, these signals oscillate around a zero baseline with a maximum amplitude generally below 1 mV and a frequency band under 500 Hz[67,68], providing rich signal patterns that can be decoded into speech content. The acquired raw EMG signals are generally amplified by a differential amplifier. Subsequently, these signals are processed through a bandpass (anti-aliasing) filter, typically spanning 20 to 500 Hz[67,68]. This stage is critical for removing high-frequency noise and ensuring that the signal bandwidth conforms to the Nyquist-Shannon sampling theorem before digitization, thereby preventing aliasing. An analog-to-digital (A/D) converter finally converts the signals to digital output for further processing.
Figure 3. EMG-based SSIs. (A) Working principle of EMG-based SSIs; (B) Dry electrode made by gold thin films for SSIs. Adapted from Ref. [63], under CC BY 4.0 license; (C). Dry electrode based on AgNWs for SSIs. Adapted with permission from Ref. [5] Copyright 2023, Wiley-VCH; (D) Wet electrode based on ion gels for SSIs. Adapted with permission from Ref. [64] Copyright 2023, Wiley-VCH. EMG: Electromyography; SSIs: silent speech interfaces; AgNWs: silver nanowires; Difff. Amp.: differential amplifier; PET: polyethylene terephthalate; SEM: scanning electron microscope.
The effectiveness of EMG-based SSIs is fundamentally limited by the quality of the electrode-skin interface, driving continuous innovation in electrode materials and designs. Traditional approaches have relied on commercially available electrodes, including gold-plated cup dry electrodes, Ag/AgCl dry electrodes, and pre-gelled wet electrodes[69-71]. Among these options, pre-gelled electrodes often provide superior signal quality due to the low electrode-skin impedance. However, they suffer from several limitations for long-term use, including signal degradation caused by gel dehydration, skin irritation triggered by the conductive gel, and bulkiness and visibility on the skin surface[72]. To address these concerns, researchers have developed soft gel-free dry electrodes that prioritize both long-term performance and user comfort[73-76]. To ensure mechanical compatibility with biological tissues, these systems employ materials with properties that closely match those of skin or neural tissues, including elastomers such as PDMS (Young’s modulus ~1-3 MPa[77]). In addition, soft materials, such as hydrogels, are frequently selected for their high stretchability (up to 1,000%) and low bending radii. These characteristics minimize mechanical constraints on natural movements[78]. The developed electrodes can seamlessly conform to the morphology of the skin, even under skin deformations during speech. A representative example is shown in Figure 3B, where thin gold film electrodes have been used for EMG sensing[63]. The thickness of the gold thin film is 1.2 µm, and the film is supported by a 47-µm Tegaderm patch [Figure 3B, Structure]. The electrode array can achieve conformal contact with the skin texture, as confirmed in the SEM images [Figure 3B, Interface SEM]. Conformal contact is essential for high-fidelity EMG signal acquisition, as this can minimize the interface gap between the electrode and skin, reduce electrode-skin impedance, and alleviate interference from motion artifacts[5,79].
Although gold thin-film electrodes improve user comfort, they remain opaque and visibly noticeable on facial skin. This visibility challenge has motivated the development of EMG electrodes with high transmittance[80]. Specifically, electrodes based on silver nanowires (AgNWs) provide good transmittance, in addition to high conductivity and excellent stretchability[5]. Figure 3C illustrates the unobtrusive appearance of an AgNW-based electrode on human skin. Owing to the large aspect ratio of nanowires, a low-density AgNW network can maintain conductive pathways via overlapping nanowires, which allows most visible light to pass through [Figure 3C, AgNW SEM][81]. Notably, when placed around the mouth and neck muscles, AgNW electrodes are able to detect subtle muscle activities during silent speech. Assisted by ML-based speech recognition models, the system can differentiate between words with similar visemes, such as “ship” and “sheep”[5], by capturing fine articulatory differences that are visually indistinguishable but electrically distinct. Ionogel-based electrodes represent another approach to achieving unobtrusive EMG sensing. The soft and transparent gel forms a continuous ionic pathway and remains transparent in the visible spectrum[82]. Figure 3D presents an example of SSIs enabled by ionogel electrodes. The iongel can establish conformable contact with the skin, ensuring low impedance and high signal quality[64]. Practically, the electrode array connects to a compact circuit board that can be conveniently placed in a chest pocket for everyday use. Instead of relying on skin patches, electrodes can also be built directly into everyday accessories. For example, recent designs hide graphene-coated textile electrodes inside headphone earmuffs to read muscle signals completely unnoticed[83].
EMG electrodes described above must be paired with appropriate data acquisition systems to realize their full potential. The performance of EMG-based SSIs also depends on the data acquisition device. For research and clinical settings, bench-top systems such as ADInstruments PowerLab with built-in filters offers high precision acquisition of EMG signals, with sampling frequencies up to several tens of kilohertz[84]. Portable devices are also available for daily applications. For instance, the OpenBCI Cyton streams data at 250 Hz via Bluetooth and up to 1 kHz via Wi-Fi, with a lightweight, pocket-sized form factor[85]. Another portable system, the Delsys Trigno Quattro, comprises built-in filters, four EMG channels, and wireless transmission, with sampling frequencies up to 2.2 kHz[86]. Sampling rate is the key to capturing precise information from EMG signals. The informative frequency band of speech-relevant EMG signals is generally below 500 Hz. According to the Nyquist-Shannon sampling theorem, to accurately capture these signals without distortion, the sampling rate must be at least twice the highest frequency present[87,88]. Therefore, a minimum sampling rate of 1 kHz is necessary to prevent aliasing and ensure accurate signal reconstruction. This requirement is crucial when selecting data acquisition devices for EMG applications, as inadequate sampling rates can lead to the loss of critical information and misinterpretation of muscle activity. Therefore, choosing a device often involves balancing precision and portability. While traditional setups rely on bench-top instruments or portable rigid-printed PCB devices to digitize signals, these rigid components heavily restrict overall wearability and create a severe mechanical mismatch with soft epidermal sensors. To overcome this limitation, recent academic research has shifted toward deploying fully integrated, flexible PCB (fPCB) data acquisition (DAQ) systems[89]. By matching the mechanical compliance of human skin and eliminating the need for bulky hardware, this structural integration ensures long-term attachment stability and minimizes motion artifacts typically induced by rigid components[90].
EMG-based SSIs are highly promising for daily use due to their noninvasive nature, compatibility with soft, skin-conformal electrodes, and ability to operate reliably in various conditions, including low-light and noisy environments. Advances in dry stretchable electrodes (such as those enabled by serpentine-patterned gold films, AgNWs, and ionogels) have greatly improved the wearability, user acceptance, and signal quality of EMG electrodes[5,63,64]. Despite these advances, several technical challenges should be addressed to enhance the long-term deployment. Future research should focus on long-term robustness to tackle problems related to sweat accumulation, instabilities caused by repeated removal and reattachment, and signal variations caused by motion artifacts. From a system integration perspective, efforts should also be devoted to minimizing the size of data acquisition components, improving the flexibility of integrated systems, and reducing power consumption. The path forward requires coordinated advances across multiple domains. Advancements in low-power amplifiers, wireless transmission techniques, data compression methods, and optimized compact designs, can help minimize power consumption and device size without compromising signal quality. These hardware improvements, combined with continued electrode innovation and signal processing advances, position EMG-based SSIs as one of the most promising approaches for practical SSR systems.
EEG-based SSIs
Please note that we limit our discussion of EEG-based SSIs to the assessment of EEG signals alone as a sensing modality. We acknowledge that strategies such as multimodal fusion and mixed training paradigms can enhance overall brain-computer interface (BCI) performance and system-level accuracy. As illustrated in Figure 4A, EEG-based SSIs measure brain electrical activities in the conceptual preparation stage of the speech generation process [Figure 1A]. Similar to EMG, EEG captures biopotential signals using either bipolar or monopolar configurations. EEG electrodes are placed on the scalp to monitor brain activity rather than on muscles. A common placement follows the international 10-20 system, which standardizes electrode positions over key brain regions[95]. The neural signals originate from cortical neurons and spread through brain tissues via volume conduction. Subsequently, the signals travel through structures such as the skull and scalp to the scalp electrode via capacitive conduction[96]. These weak signals, typically ranging from 1 to 100 µV in adults[97], are then amplified by a differential amplifier, filtered through a band-pass filter, and digitized by an A/D converter. This signal conditioning process is similar to that used for EMG but is adjusted for lower amplitudes and narrower bandwidths. More details on EEG data acquisition devices can be found in the previous review paper[98]. The resulting EEG signals are generally decomposed into five frequency bands: delta (< 4 Hz), theta (4-8 Hz), alpha (8-12 Hz), beta (12-30 Hz), and gamma (> 30 Hz)[99]. In SSI research, delta and theta bands are typically analyzed because their slower rhythms are better aligned with the pacing of phrases and syllables during speech, offering stronger links to speech intention. Some studies also use gamma band activities to capture finer details and improve recognition accuracy[100-102].
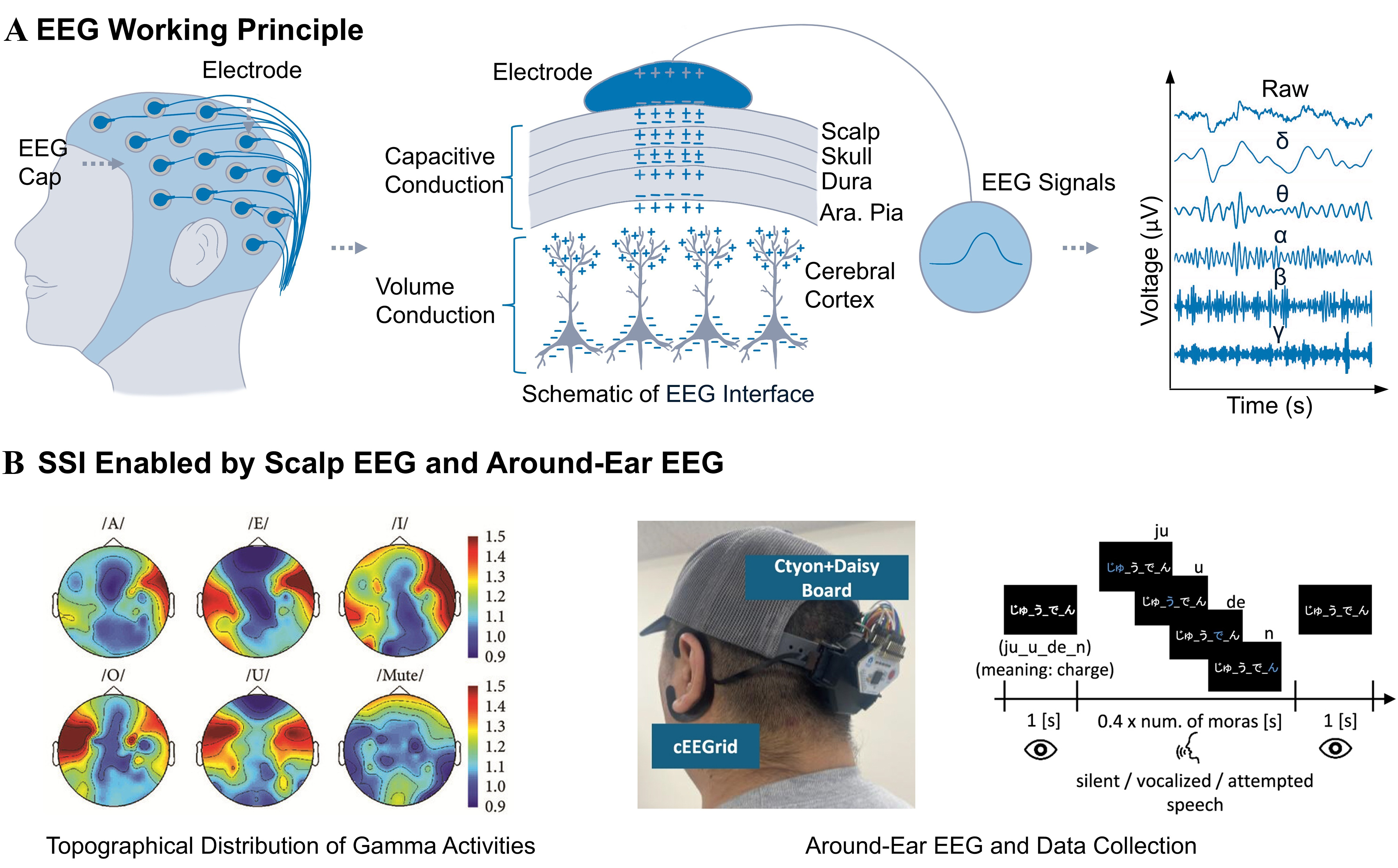
Figure 4. EEG-based SSIs. (A) Working principle of EEG-based SSIs. The simplified EEG interface in the middle part of (A): Adapted from Ref. [91], under CC BY 4.0 license. EEG signals in the right part of (A): Adapted from Ref. [92], under CC BY 4.0 license; (B) SSIs enabled by scalp EEG and around-ear EEG. Scalp EEG: Adapted from Ref. [93], under CC BY 4.0 license. Around-ear EEG: Adapted from Ref. [94], under CC BY 4.0 license. EEG: Electroencephalography; SSIs: silent speech interfaces.
While EEG sensors offer a non-invasive approach, these signals typically undergo severe attenuation and reduced spatial resolution due to volume conduction through the skull. Despite these physical limitations, recent studies demonstrate emerging potential for EEG-based SSR. Early work successfully decoded vowel imagery using EEG and extreme learning machines[93]. Figure 4B shows the topographical distribution of gamma-wave activity in one subject during vowel imagery. Enhanced activity was observed in both temporal regions when the subject imagined vowels. More recently, researchers achieved silent speech decoding utilizing around-ear EEG combined with large-scale training data[94], as shown in Figure 4B. Furthermore, this domain is advanced by pretraining large brain language models specifically for active EEG-based BCIs[103]. Capturing these highly attenuated signals requires robust sensor interfaces.
To obtain high-fidelity EEG signals, a typical setup requires the participant to wear a cap [Figure 4A] on the head. Electrodes are mounted on the cap to measure biopotentials from the scalp[104-107]. A chin rest is often necessary since it can help reduce the motion artifacts in the signals. Similar to EMG, the electrode design in EEG is crucial. Commercial pre-gelled electrodes used in EMG can often be applied to EEG. Additionally, snap electrodes with a comb structure are also widely used for EEG, since they can form better contact with the scalp, especially with the interference of hair[108,109]. However, the limited contact area of comb tips can result in higher electrode-skin impedance, potentially reducing signal quality. Recent developments have explored bio-gels to paint or print electrodes directly onto the skin, offering an effective solution for maintaining electrode-skin contact in hairy regions[110,111]. The bio-gel offers several beneficial features, including strong adhesion, rapid curing, and easy removal, while also being skin-friendly and environmentally sustainable.
Apart from gel electrodes, gel-free dry electrodes have been explored to address concerns with conductive gel in commercial pre-gelled electrodes. One system based on dry electrodes demonstrates basic command-based control, such as ‘stop’ and ‘forward,’ for wheelchair users[112]. Another example utilizes a similar design but with different electrode attachment positions[113]. This system comprises a wireless earbud-like EEG device with three electrodes (working (positive), reference (negative), and ground) placed on the facial skin. Compared to commercial EEG devices, the earbud-like EEG device shows better signal quality with higher SNRs[113]. Although the above two systems have not yet been directly applied to silent speech analysis, they share the same goal as SSIs - that is, to interpret people’s attempts and intentions. However, such interfaces lack sufficient electrodes and signal channels for achieving a more comprehensive SSR.
EEG-based SSIs face significant challenges in both comfort and signal quality. Traditional headsets are often bulky and uncomfortable, making them difficult to wear for long periods. While reducing the number of electrodes and the coverage area can enhance comfort, this approach typically compromises performance, given the fact that the speech recognition accuracy is limited even with high-density electrode configurations. EEG signals are highly vulnerable to interference, particularly interference from non-speech-relevant brain activities, such as cognitive distractions and mental wandering. These fundamental limitations, combined with substantial inter-subject variability and session-to-session variations, create significant barriers to achieving the stable and practical performance required for continuous use.
IMU-based SSIs
IMU-based SSIs track changes in articulator movements (e.g., speech-induced jaw and skin movements) during the speech generation process [Figure 1A and Figure 5A]. One IMU unit, typically in the form of a small circuit board, can provide up to 9 degrees of freedom (9DOF) by combining a tri-axis accelerometer, gyroscope, and magnetometer[116]. The accelerometer and gyroscope are often used together for SSIs, while the magnetometer is usually used in a different setup because it requires external permanent magnets. For the accelerometer and gyroscope-based SSIs, the IMU is typically attached to the neck, jaw, or facial skin using medical tape or a soft adhesive elastomer[47]. This allows the IMU to move together with the skin, transferring skin movements during silent speech through the IMU-skin interface. The accelerometer records subtle changes in acceleration, and the gyroscope detects changes in angular velocity. These signals are converted into digital signals that reflect articulatory movements. Unlike the accelerometer and gyroscope-based approach, in a magnetometer-based SSI, the sensor is placed on a bony area with negligible skin movements during speech, and a small permanent magnet is attached to the skin where deformation occurs[115]. The magnetometer detects changes in the magnetic field caused by the magnet’s movement. These approaches capture low-frequency (about 1-20 Hz[117]) deformations related to silent speech. The signals are easily affected by head movements and changes in the geomagnetic field.
Figure 5. IMU-based SSIs. (A) Working principle of IMU-based SSIs. The left and right parts of (A): Adapted from Ref. [114], under CC BY 4.0 license; (B) IMU-based SSIs with calibration of head movements. Adapted from Ref. [114], under CC BY 4.0 license; (C) SSIs based on the soft magnetic skin and magnetometers. Adapted with permission from Ref. [115] Copyright 2023, RSC. IMU: Inertial measurement unit; SSIs: silent speech interfaces; DF: differential feature.
Extensive research has been conducted on IMU-based SSIs[3,46,47,117]. Researchers have developed SSI using two IMUs attached below the jaw and on the neck to detect subtle skin deformations during speech[47]. Such a system applies deep learning to interpret silent commands from motion signals. When the users silently read on-screen text, the system roughly pairs sensor data with phoneme sequences generated from the text using the timestamp. Connectionist temporal classification (CTC)[118] is then used to establish the alignment between the motion data and the target phonemes, enabling silent speech-to-text recognition[47]. Figure 5B shows a similar IMU-based interface, but incorporates an additional sensor mounted on the head[114]. This extra sensor enables real-time calibration that eliminates motion artifacts caused by head and body movements, ensuring that only lip and chin movements are captured. A data fusion algorithm combines signals from the three IMUs to reconstruct high-fidelity lip motion, and a speech movement reconstruction strategy is used to generate fluent sentence data from a small set of word-level samples [Figure 5B, Data Fusion]. The calibration process for removing motion artifacts is crucial, particularly for mobile or daily applications, as it significantly improves signal quality, long-term stability, and the resulting speech recognition accuracy.
Apart from accelerometer and gyroscope-based SSIs, Figure 5C highlights an interface using a single piece of soft magnetic skin and two magnetometers (one working and one reference) to monitor deformations from the TMJ[115]. The soft magnetic skin, which is a stretchable composite of magnetic particles and a silicone matrix, was attached to the facial skin behind the ramus. As the user silently articulates, skin and jaw movements in the TMJ region alter the magnetic field from the soft magnetic skin, which can be detected by a nearby working magnetometer placed behind the ear. To reduce noise from non-speech body motions or geomagnetic fields, a reference magnetometer is placed on the opposite side of the head [Figure 5C, Sensor Positions]. To optimize sensor placement, digital image correlation (DIC) is adopted to map skin strain and displacement during silent speech. The ramus area near the ear is identified as the optimal sensing location, considering both signal strength and wearability [Figure 5C, DIC Measurement]. Such a system is very similar to the PMA system (discussed in Section 3.2), with the primary difference being the placement locations of the magnetic components.
IMU-based SSIs are well-suited for daily use due to their compact design, low power consumption, and built-in wireless data transfer capabilities. However, these systems often suffer from poor skin conformability because rigid circuit boards do not adapt well to curved and moving surfaces. Development of flexible and stretchable IMUs is essential for enhancing comfort and ensuring more precise, stable tracking of natural facial and jaw movements. In addition, motion artifacts and ambient interference remain significant challenges in IMU systems. Importantly, the motion artifacts in IMU systems are fundamentally different from those in biopotential signals, such as EEG and EMG. Motion artifacts in EEG and EMG mainly arise from disturbances at the electrode-skin interface. In contrast, motion artifacts in IMU-based systems are typically induced by body movements. Additional units acting as calibration references are necessary to eliminate the influence of body movements or geomagnetic fields.
Strain sensor-based SSIs
Strain sensor-based SSIs measure changes in articulator movements [Figure 1A] by detecting facial skin deformations associated with speech articulation using strain sensors. Figure 6A depicts the working principle of SSIs based on strain sensors. To accurately capture facial movements, the strain sensors must be highly stretchable and conformal to the skin[119]. This conformability allows the sensors to deform alongside the skin surface during articulation, ensuring good mechanical contact without restricting natural facial movements. This approach differs from IMU-based methods in two key aspects: (1) IMUs acquire motion signals at discrete points or acquire averaged signals across a broader area, whereas strain sensors provide continuous multi-location deformation measurements; (2) Commercial IMU devices are typically rigid and cannot achieve conformal skin contact. Fully conformal IMU systems could potentially offer superior performance, but they have not yet been developed for SSI applications.
Figure 6. Facial skin-mounted strain sensors for SSIs. (A) Working principle of strain sensor-based SSIs. The left part of (A): Adapted from Ref. [119], under CC BY 4.0 license. Signals in the right part of (A): Adapted from Ref. [120], under CC BY 4.0 license; (B) SSIs enabled by resistive strain sensors for monitoring facial strain and DIC techniques for selecting sensing locations based on strain and displacement. Adapted with permission from Ref. [121], Copyright 2022, ACS; (C) SSIs enabled by biaxial resistive strain sensors for monitoring facial strain. Adapted from Ref. [120], under CC BY 4.0 license; (D) SSIs enabled by triboelectric sensors for monitoring facial movements. Adapted from Ref. [11], under CC BY 4.0 license. SSIs: Silent speech interfaces; DIC: digital image correlation.
Strain sensors can operate based on various principles, such as resistive, piezoelectric, and triboelectric effects[11,120,122-127]. For instance, resistive strain sensors generate highly sensitive signals (i.e., resistance changes) in response to tiny skin movements around the lips, which can be acquired using simple data acquisition methods[120]. These signals typically occur within a low-frequency range below 20 Hz, effectively capturing the subtle mechanical motions of speech articulation.
Most strain sensors developed for SSIs utilize resistive sensing mechanisms. A representative single-axis resistive strain sensor based on AgNWs is shown in Figure 6B[121]. This sensor incorporates a strain-modulating structure to increase the sensitivity [Figure 6B, Structure]. The strain-modulating structure features periodic Ag-Ni particle regions in a PDMS matrix that locally increase stiffness, which leads to concentrated strain in adjacent softer PDMS regions and thus enhanced sensitivity. This study adopts DIC analysis combined with ML algorithms to identify optimal sensor placement locations [Figure 6B, DIC Measurement]. The ML model ensures that sensors are positioned not only in regions of maximum strain but also at locations rich in discriminative information for distinguishing speech-related facial movements[121].
Beyond single-axial strain sensors, biaxial resistive sensors have been developed to capture facial skin deformations in two orthogonal directions [Figure 6C][120]. In this approach, four sensors were placed around the mouth to monitor dynamic skin deformations during silent speech [Figure 6C, Sensor Position]. Each sensor comprises two orthogonally aligned silicon nanomembrane (SiNM) strain gauges [Figure 6C, Structure]. Due to directional sensitivity and mechanical decoupling achieved through the fractal serpentine design, strain along one axis induces minimal response in the orthogonal gauge, effectively minimizing crosstalk [Figure 6C, Biaxial Sensing]. The fractal serpentine design also enhances the sensor stretchability by allowing the intrinsically stiff silicon material to accommodate large deformations through its geometrically engineered layout. With a total thickness under 8 μm, the self-standing sensor conforms seamlessly to facial skin during speech, enabling accurate and repeatable signal acquisition [Figure 6C, Conform to Skin]. By minimizing bending stiffness, this reduced thickness allows the intrinsically stiff and brittle single-crystalline silicon to accommodate large deformations without fracturing.
Besides the resistive sensor, triboelectric sensors represent another approach for SSIs [Figure 6D][11]. Triboelectric sensors were positioned at similar facial locations as resistive strain sensors [Figure 6D, Sensor Position]. Each triboelectric sensor consists of flexible polyvinyl chloride (PVC) and nylon layers separated by a sponge spacer and encapsulated in a polyimide film [Figure 6D, Structure]. During speech articulation, skin deformation causes mechanical contact and separation between the layers, which generates triboelectric charges and leads to measurable electrical signals [Figure 6D, Charge Transfer]. While these electrical signals do not directly represent strain values, they correlate strongly with skin strain caused by lip motions[11]. Piezoelectric strain sensors, such as the conformable AlN-based conformable facial code extrapolation sensor (cFaCES)[122], have shown strong potential for decoding facial deformations by converting localized skin strains into electrical signals. Although these sensors offer high sensitivity and rapid response to dynamic strain, they have not yet been implemented in SSIs, despite their proven ability to capture facial motions.
Strain sensor-based SSIs offer excellent skin conformability and wearing comfort, through the use of soft, stretchable materials and deformable structural designs (e.g., fractal patterns). However, one of the major challenges lies in system integration. Current designs often lack compact, high-density, multi-channel arrays capable of supporting accurate spatial mapping of articulatory movements. Additionally, repeated attachment and removal cycles can lead to mechanical degradation or signal drift, compromising long-term reliability and usability. The development of fully integrated systems incorporating wireless data transmission, robust interconnections, and enhanced reusability remains a critical research focus for the practical deployment of strain sensor-based SSI technology.
Throat-mounted mechanical sensor-based SSIs
Throat-mounted mechanical sensor-based SSIs capture mechanical deformations associated with articulator movements and articulation effects [Figure 1A]. Figure 7A summarizes the sensing of throat movements. Unlike facial strain sensors that primarily detect low-frequency skin deformations on the cheeks and lips, throat-mounted sensors capture a broader spectrum of physiological signals with distinct frequency characteristics[1]. These sensors, typically implemented as ultrasoft patches positioned over the larynx, detect both slow muscle motions (mechanical deformation rather than biopotentials) and high-frequency residual vibrations with frequencies extending up to 2 kHz. The captured signals exhibit distinct frequency bands corresponding to different physiological processes: Muscle motions around the throat are typically confined to relatively low frequencies, while esophageal voice signals extend to mid-frequency ranges, and remaining laryngeal or acoustic energy can appear at higher frequencies[1]. Importantly, throat movement signals persist during silent speech, although the high-frequency content may be significantly attenuated or absent. Because the sensor is positioned directly at the source of these signals, it captures richer mechanical and acoustic information and remains less susceptible to interference from head movements or background noise.
Figure 7. Throat-mounted mechanical sensors for SSIs. (A) Signals at different frequencies from the throat. The right part of (A): Reproduced with permission from Ref. [1] Copyright 2023, Springer Nature; (B) SSIs enabled by soft magnetic composites for monitoring throat movements. Adapted from Ref. [54], under CC BY 4.0 license; (C) SSIs enabled by ion gel-based sensors for monitoring pressure at the skin-sensor interface on the throat. Adapted from Ref. [128], under CC BY 4.0 license. SSIs: Silent speech interfaces; PDMS: polydimethylsiloxane; MI: magnetic induction; MC: magnetomechanical coupling.
The development of throat monitoring for SSIs is concentrated around strain, pressure, and vibrational sensing. As an example of the strain-based devices, Figure 7B presents a throat monitoring system based on magnetoelasticity and electromagnetic induction for detecting laryngeal muscle movements[54]. It should be noted that the motion sensor shown in Figure 7B utilizes a magnetic sensing mechanism. The articulatory movements alter the geometry of the soft magnetic film and therefore change the magnetic flux density. The key sensing layer is the magneto-mechanical coupling (MC) layer, composed of a PDMS matrix embedded with magnetic microparticles [Figure 7B, Structure]. During silent speech articulation, laryngeal muscles expand and contract, causing the MC layer to undergo corresponding deformations [Figure 7B, MC Layer Deformation]. These deformations alter the magnetic flux within the surrounding serpentine copper coils, consequently modifying the induced current. The kirigami structure amplifies both horizontal and vertical strain responses, ensuring that subtle throat muscle motions can be effectively converted into electrical signals.
Pressure sensors represent another approach for detecting throat movements. For instance, Figure 7C shows a throat-mounted device using a pressure sensor based on a zwitterionic hydrogel[128]. This structure features seamless integration of a hydrogel sensing element, a polymer support frame, and a wireless data acquisition circuit in a compact, skin-conformal design [Figure 7C, Structure]. The device monitors the pressure between the throat skin and the sensor. The sensing mechanism relies on force-induced ion generation: When throat pressure is applied, the distance between zwitterionic groups decreases, triggering water dissociation and generating mobile OH⁻ ions. The ion generation produces measurable ionic currents, leading to resistive changes under pressure [Figure 7C, Morse Code Signal]. The ion-based conduction enables high sensitivity even under very low pressures. Rather than attempting full word recognition, this system demonstrates its capability in Morse code recognition. The user controls the contraction of their muscles around the throat, and the system converts the silent cues into short and long signals that represent dots and dashes. While this method enables silent communication without audible speech or visible movement, reliance on Morse code limits its efficiency for rapid and natural communication.
As for vibrational sensing, an artificial throat is a device that detects muscle movements or residual vibrations in the throat and converts them into sound or speech[53,129]. This technology has attracted significant research interest due to its potential to assist individuals who have lost their voice box in regaining the ability to communicate[1,130]. The artificial throat integrates both sensing and sound-emitting functions within a single patch attached to the laryngeal skin[1]. Its structure includes a perception layer that is made using laser-induced graphene on a flexible polyimide substrate, whose electrical resistance changes under subtle strain. The perception layer detects low-frequency throat muscle motions and mid-to-high-frequency vocal vibrations. A separate vocalization layer converts the collected electrical signals into audible sound. This system collects motion signals, converts them into spectrograms, and applies deep learning to recognize speech content. The recognized text is then synthesized into audio output by the artificial throat, thereby restoring speech capability to users without vocal cords. Newer acoustic sensors utilize piezoelectric micromachined transducers to achieve a broader bandwidth and higher sensitivity[131]. This allows for accurate speech recognition even in noisy environments or while the user is wearing a mask.
Throat-mounted SSIs offer a simple wearable solution for capturing laryngeal movements. Their compact design enhances user comfort and facilitates continuous monitoring, making them suitable for daily use. However, throat-mounted systems are often limited to single channels and may not provide sufficient information to support full natural language recognition[128], especially when signals corresponding to laryngeal movements are weak.
Comparisons of epidermal systems for SSIs
Representative epidermal systems for SSIs are summarized in Table 1, as detailed in Sections 3.1.1 to 3.1.5. The research landscape encompasses two primary development trajectories: (1) Hardware-focused studies that prioritize signal quality enhancement and improved wearability (reflected in advances in stretchability and unobtrusiveness); and (2) Algorithm-centric approaches that emphasize signal processing innovations, including phoneme-level recognition, speech synthesis, and large-scale dataset utilization. These systems fall into four main hardware modalities: EMG, EEG, IMU, and deformation sensors (including facial or throat-mounted variants). A fundamental distinction exists between signal types: EMG and EEG capture biopotential signals, while IMU and deformation sensors (e.g., strain and pressure sensors) detect mechanical motions. This fundamental signal difference underlies the core trade-off: Biopotential signals are closer to the neuromuscular source, providing direct access to neural activation patterns, whereas mechanical signals reflect articulator movements in a more straightforward manner.
Comparisons of representative epidermal systems for SSIs
| Methoda | Location | Channel amount | Conformability | Unobtrusivenessb | Identification taskc | Dataset | Algorithm | Recognition rated |
| EMG[63] | Cheek | 4 | Yes | Medium | Word | 110-word | LDA | 92.6% |
| EMG[5] | Cheek/neck | 8 | Yes | High | Word | 11-word | LDA | 97.6% |
| EMG[64] | Cheek | 4 | Yes | High | Word | 18-word | TCN | 91.5% |
| EMG[30] | Cheek/neck | 8 | No | Low | Audio | 18-hour-sentence | Transformer | 57.8% |
| EMG[132] | Cheek/neck | 8 | No | Low | Phoneme | 18-hour-sentence | Transformer | 87.8% |
| EMG[69] | Cheek/neck | 8 | No | Low | Phoneme | 2.5k-word | HMM | 89.7% |
| EEG[133] | Scalp | 64 | No | Low | Word | 3-word | RVM | ~50.0% |
| EEG[134] | Scalp | 64 | No | Low | Audio | 13-word | GAN | 31.7% |
| EEG[135] | Scalp | / | No | Low | Word | 15-word | CNN | 51.4% |
| IMU[47] | Chin/neck | 12 | No | Medium | Phoneme | 56-phrase | CNN/RNN | 80.8% |
| IMU[114] | Lip/chin | 18 | No | Low | Word | 93-word | TCN | 97.4% |
| IMU[46] | Jaw | 12 | No | High | Phoneme | 100-word | Particle filter | 94.8% |
| IMU[115] | Jaw | 6 | Yes | High | Word | 20-word | LDA | 87.3% |
| Strain[120] | Cheek | 8 | Yes | Medium | Word | 100-word | CNN | 87.5% |
| Strain[121] | Cheek | 4 | Yes | Medium | Word | 5-word | RNN | 85.2% |
| Strain[11] | Cheek | 2 | Yes | Low | Word | 20-word | RNN | 94.5% |
| Strain[136] | Cheek | 8 | Yes | Low | Word | 21-word | CNN | 84.4% |
| Strain[137] | Throat | 1 | Yes | High | Word | 20-word | CNN | 95.3% |
| Strain[1] | Throat | 1 | Yes | High | Word | 6-phrase | SVM | 91.0% |
| Strain[54] | Throat | 1 | Yes | High | Word | 5-phrase | CNN | 94.7% |
| Pressure[128] | Throat | 1 | Yes | High | Letter | 26-letter | Morse code | 95.0% |
In terms of hardware, EMG and strain-sensor systems have demonstrated significant progress in wearing comfort, unobtrusiveness, and social acceptance. These improvements have been facilitated by the adoption of flexible, stretchable, and often transparent materials that conform to the skin, thereby enhancing physical comfort and social acceptance. In contrast, EEG systems are bulky and require a large number of channels. Existing systems often rely on rigid and opaque components. Due to these limitations, EEG and IMU systems are considered less comfortable and socially acceptable for extended daily deployment.
Skin-mounted sensors face significant interference from motion artifacts during daily activities. These artifacts primarily arise from interface impedance instability, overlapping biopotentials, and mechanical disturbances. To ensure signal integrity, a multi-layered approach is required[138]. (1) At the hardware level, achieving a stable bioelectronic-tissue interface is critical. Using low-modulus materials ensures mechanical matching with the skin, preventing detachment and subsequent impedance fluctuations. Other approaches to enhance conformal contact include reducing device thickness or using deformation-tolerant structures such as serpentines or kirigami patterns. Additionally, covalent chemical bonding or bio-adhesives provide robust integration in dynamic environments[139-141]; (2) At the sensor level, specialized sensor designs, such as material-enabled dampers or strain isolators, can absorb or block mechanical vibrations before they reach the sensing area[142]; (3) At the circuit level, signal compensation channels can be deployed to capture and subtract common-mode noise[143,144]; (4) At the software level, algorithmic intervention remains a pivotal post-processing strategy. Adaptive filtering and transforms (e.g., wavelet or fast Fourier) selectively remove unwanted frequency components[145,146]. For more complex, non-linear artifact patterns, ML and deep learning models can be trained to extract target physiological features from noisy datasets[146,147].
Powering flexible SSIs remains a primary challenge for continuous, real-world deployment. Conventional bulky and rigid batteries severely compromise the skin-conformability of bio-integrated systems. Future interfaces may integrate flexible power sources or advanced energy harvesting modules, such as biomechanical or thermal harvesters, to enable self-sustained, battery-free systems[148]. Beyond hardware improvements, deploying AI-assisted power management strategies is equally critical. By intelligently and dynamically balancing sensor sampling rates with model computation loads, these systems can possibly reduce overall energy consumption without sacrificing decoding accuracy[149].
Regarding software development and SSR performance, recent studies have demonstrated that EMG- and IMU-based SSIs can achieve high recognition accuracy at both the word and phoneme levels[46,132]. In contrast, EEG and deformation-sensor-based systems generally achieve lower accuracy[121,133]. Notably, the recognition accuracy for EEG systems sometimes falls below 50% for certain recognition tasks, as shown in Table 1. Although direct performance comparisons remain challenging due to variations in datasets and evaluation metrics, collective findings across multiple modalities reveal the relative strengths and limitations inherent to each method. A detailed discussion of ML-assisted signal processing of silent speech cues is provided in Section 4.
Intraoral interfaces for tapping the articulatory cavity
Intraoral systems for SSIs are devices placed inside the mouth to monitor articulatory movements, particularly tongue movements. The systems discussed in this Section, including EPG, electro-optical stomatography (EOS), permanent magnetic articulography (PMA), and electromagnetic articulography (EMA), capture either the position or contact patterns of the tongue relative to the hard palate, providing detailed information about silent-speech-related articulation.
EPG-based SSIs
EPG-based SSIs capture cues from articulator movements (i.e., tongue movements) in the speech generation process [Figure 1A]. As shown in Figure 8A, an EPG system employs a custom-made palate plate placed in the user’s mouth, sitting against the hard palate[152]. This plate contains an array of small electrodes connected to an external control unit[153]. A low-level alternating current is applied between each electrode and a reference electrode placed on the skin, such as on the cheek or wrist[154]. When the tongue makes contact with an electrode, the impedance changes, allowing the system to detect the contact through changes in the electrical signal. If there is no contact, the signal remains unchanged. Each electrode records a binary signal that reflects the presence or absence of tongue contact at each moment[155]. It is worth noting that EPG does not measure biopotential signals as EMG does. Instead, it senses direct physical contact rather than measuring voltage changes stemming from ion flows in the body. By sequencing the on/off patterns from all electrodes over time, EPG provides a real-time contact map. These spatial-temporal patterns from the map reflect the tongue’s position relative to the hard palate during silent speech, making EPG useful for SSR.
Figure 8. EPG or EOS-based SSIs. (A) Working principle of EPG-based SSIs. The left part of (A): Adapted from Ref. [150], under CC BY 4.0 license; (B) EPG systems that can measure the contact between the tongue and the sensor. Adapted with permission from Ref. [52], Copyright 2022, ACM; (C) EOS systems for measuring contact and distance between the tongue and the sensor. Adapted from Ref. [151], under CC BY 4.0 license. EPG: Electropalatography; EOS: electro-optical stomatography; SSIs: silent speech interfaces.
One example of an EPG-based SSI is illustrated in Figure 8B. The user wore a custom-made dental retainer (palate plate) embedded with 124 electrodes that detect tongue-palate contact at a sampling rate of 100 Hz [Figure 8B, EPG User][150]. The palate plate must be custom-fit through a dental impression process[156] to ensure accurate electrode placement. Signals are transmitted through a wired cable to an external processing device, which currently limits both social acceptability and portability [Figure 8B, Custom Palate Plate]. The system can visualize contact patterns, known as palatograms[157], to capture tongue positions during silent speech. An example of palatograms for the silent letter “s” is provided in Figure 8B, EPG Signals. The palatograms show clear electrode activation when the tongue makes contact with the palate plate. In contrast, vowels such as “i” often involve little or no contact with the palate [Figure 8B, EPG Signals], resulting in sparse or absent signals.
EPG-based SSIs offer detailed signals about tongue-palate contact during speech, providing high spatial and temporal resolution beneficial for speech therapy and research. However, their practical application faces several challenges. The requirement for a custom-fit artificial palate with embedded electrodes can cause discomfort, affecting wearability and user compliance. This setup is also sensitive to factors such as saliva-induced electrode degradation and saliva bridging between adjacent electrodes[155], which can compromise signal quality and robustness over time. Moreover, EPG’s reliance on physical contact limits its effectiveness in capturing certain phonemes, especially those involving minimal tongue-palate interaction[151]. These limitations affect EPG’s standalone efficiency as an SSI, indicating a need for integration with complementary sensing methods to enhance performance and user experience.
EOS-based SSIs
Intraoral systems for SSIs are designed to monitor articulatory movements, capturing movement patterns of the tongue relative to the hard palate. While traditional contact sensors (EPG) are excellent for characterizing direct tongue-to-palate contact when pronouncing consonants (e.g., /t/, /d/, and /n/), they fail to capture the tongue kinematics during the production of vowels (e.g. /o/, /e/), where the tongue lowers to create an open space, or during certain fricatives (e.g., /s/, /sh/) that require near-palate constrictions with zero applied pressure. Proximity sensing is therefore essential to bridge this gap, as it maps the continuous trajectory of the tongue even during these non-contact gestures. For example, systems like EOS extend traditional EPG by integrating optical modules acting as proximity sensors to capture both contact and non-contact information. Furthermore, given the highly limited space inside the oral cavity for mounting sensors, developing compact, multi-modal sensor units capable of both proximity and pressure sensing in a planar layout is highly meaningful for the practical advancement of intraoral SSIs.
The EOS system combines EPG and optical distance sensing to overcome EPG’s limitations [Figure 8C, Assembled Sensor Unit][151]. The contact sensing component of the EOS system includes 32 gold-plated pads arranged to detect the tongue-palate contact during silent speech. The body clock contact establishes electrical contact with the user’s body to serve as a reference node [Figure 8C, Circuit]. When the tongue touches any sensor pads, a voltage drop is detected, indicating contact between the tongue and the plate. This body block contact ensures a consistent voltage baseline across the array and enables accurate, stable contact sensing.
In addition to the EPG electrodes, the EOS system includes several pairs of light emitters and detectors embedded in the custom-fit palate plate [Figure 8C, Circuit][151]. The tongue acts as the reflective surface. Each infrared emitter sends light toward the tongue, and the nearby detector senses the amount of light reflected [Figure 8C, Optical Distance Sensing Principle]. When the tongue is close to the palate, more light is reflected, resulting in a higher detector voltage. As the tongue moves further away, less light is reflected, and the voltage decreases. After calibration, the system converts these voltage changes into real-time measurements of the distance between the tongue and each optical distance sensor.
By combining binary contact data with distance measurements, EOS-based SSIs can track the tongue’s position relative to the hard palate even without direct contact, addressing a key limitation of traditional EPG. However, like EPG, EOS systems suffer from saliva-related issues that can interfere with sensor function. Additionally, similar to EPG systems, the need for a wired connection to an external control unit reduces their wearability and limits social acceptance due to the visible and cumbersome cabling.
PMA-based SSIs
Like other intraoral systems, PMA-based SSIs track tongue positions during the speech generation process [Figure 1A]. Figure 9A illustrates the working principle of PMA-based SSIs. Similar to the IMU-based method discussed in Section 3.1.3, PMA employs magnetometers, but differs in the magnet placement. In PMA, some magnets are attached to the tongue, making it an intraoral system[158]. In contrast, in the IMU-based SSIs, magnets are placed on the facial skin, making it an epidermal system[115]. In PMA, external magnetometers, typically integrated into a headset, detect changes in the magnetic field caused by the movement of the magnets and, consequently, the tongue[158,161]. However, PMA cannot identify the movement path of each magnet because every magnetometer senses the combined magnetic field. The final signal is the sum of all magnetic flux densities from all magnets[162]. Nevertheless, different silent speech movements produce distinct magnetic patterns, which can be recognized using appropriate models. The output of the system is a time-series of tri-axis magnetic flux density values. These signals can be used directly for SSR or transformed into approximate movement paths[158].
Figure 9. PMA or EMA-based SSIs. (A) Working principle of PMA-based SSIs. The left part of (A): Adapted from Ref. [4], under CC BY 4.0 license; (B) PMA system for SSIs. The PMA headset and one magnet in the left part of (B): Adapted from Ref. [158], under CC BY 4.0 license. The portable device and multiple magnets in the right part of (B): Adapted from Ref. [4], under CC BY 4.0 license; (C) Working principle of EMA-based SSIs. The left part of (C): Adapted from Ref. [159], under CC BY 4.0 license. Signals in the right part of (C): Adapted from Ref. [160], under CC BY 4.0 license; (D) EMA system for SSIs. The wave system in the left part of (D): Adapted from Ref. [158], under CC BY 4.0 license. The rest of (D): Adapted from Ref. [159], under CC BY 4.0 license. PMA: Permanent magnetic articulography; EMA: electromagnetic articulography; SSIs: silent speech interfaces.
Figure 9B presents one PMA system that integrates a camera for lip motion capture, a microphone for audio recording, and an array of 24 three-axis magnetometers for tracking tongue movements[158]. In this system, only one small permanent magnet (3 mm in diameter) was attached approximately 1 cm from the tongue tip [Figure 9B, One Magnet]. During silent speech, the magnetometers positioned around the cheeks record changes in the magnetic field caused by tongue motions. These obtained magnetic signals are projected into a 2D lateral path, providing trajectories that correspond to specific silent speech phrases. Despite high accuracy and rich information from multiple magnetometers, the headset[158] is not portable and is fixed in place during experiments to minimize head motion and ensure accurate tracking. The system captures multimodal data, including magnetic signals, lip images, and audio, simultaneously. However, this study did not perform full data fusion. Instead, only the magnetic signals and audio signals were used for tongue-movement-to-speech synthesis. Lip image data from the camera were collected but not used in this analysis.
Besides the system introduced above, a portable PMA system has also been developed using a lightweight headset [Figure 9B, Portable Device][4,161,162]. The headset integrates three working magnetometers and one reference magnetometer. A total of six small permanent magnets were attached using tissue adhesive: four on the lips, one on the tongue tip, and one on the tongue blade [Figure 9B, Multiple Magnets]. The working magnetometers track changes in the magnetic field caused by articulator motions, while the reference sensor isolates the geomagnetic field and ambient interference. This setup reduces environmental noise, allowing reliable signal extraction. In addition, this design offers greater portability and reduces hardware complexity. The trade-off exists between sensor density and portability. While the first system is non-portable due to its large array of magnetometers and the need for head stabilization, it provides higher spatial resolution and can convert raw magnetic signals into tongue trajectories. In contrast, the portable device sacrifices spatial fidelity and uses raw magnetic signals directly without spatial reconstruction for SSR.
Overall, PMA offers a wireless solution for SSIs by tracking articulator movements through magnetic field variations. This wireless design enhances wearability, eliminating the need for intrusive wires, which is typically necessary for EPG, EOS, and EMA. However, PMA faces several challenges in terms of robustness and precision. The system relies heavily on magnetic field measurements but lacks explicit positional tracking of specific points. This can create difficulties in capturing specific regions’ positions, potentially affecting speech recognition accuracy. Additionally, PMA systems are susceptible to interference from geomagnetic fields and user head movements, which necessitate additional calibration processes.
EMA-based SSIs
EMA-based SSIs are another approach to monitor tongue position during the speech generation process [Figure 1A and Figure 9C]. EMA requires an external device composed of several transmitter coils that are fixed around the head and driven by distinct alternating currents. These coils create overlapping magnetic fields with known strength and phase at each moment[163]. Small receiver coils are attached to the tongue, lips, jaws, or palate and are connected to the control unit by cables. As each receiver coil moves with the articulator, its position changes within the external magnetic field, causing a change in the voltage induced in the receiver coil due to Faraday’s law[164]. This induced voltage varies with the receiver coil’s distance and orientation relative to the transmitter coils. By sampling the voltage signal from each coil, the system processes these signals and calculates their three-dimensional positions and thus the tongue movement.
In a representative work, the EMA system utilized the commercially available NDI wave system [Figure 9D, Wave System] to capture tongue movements using the external electromagnetic fields[163]. Different studies may attach the wired sensor coils to the tongue at different positions [Figure 9D, EMA Sensors], but a reference sensor is usually placed on the forehead to account for head movements and enable motion correction [Figure 9D, Calibration Sensor][159,165]. The sensor coils are compact, typically measuring just a few millimeters in size [Figure 9D, Coil Structure][166]. They are lightweight and designed to minimize interference with natural speech production. Since such an EMA system is a commercial device, it can directly output the trajectories of coils using available integrated algorithms for processing raw data.
Compared to PMA systems, EMA offers higher spatial accuracy and more stable performance, making it well-suited for precise articulatory tracking[167,168]. This is because EMA tracks each sensor coil individually, allowing it to reconstruct the full movement path of every attachment point[167,168], which is not possible with PMA. However, EMA is less portable due to its reliance on wired sensors and external magnetic field generators[163], which can reduce user comfort and limit movement. EMA is also sensitive to nearby metal objects. Moreover, EMA outputs raw induced voltage signals that can be converted into 2D or 3D motion paths, providing physically interpretable trajectories[158]. whereas portable PMA systems often use raw magnetic signals directly in ML models without spatial reconstruction.
Comparisons of intraoral systems for SSIs
In summary, the intraoral systems, as detailed in Sections 3.2.1-3.2.4 and summarized in Table 2, can be divided into hard palate-mounted systems (EPG and EOS) and tongue-mounted systems (PMA and EMA). From a hardware development perspective, intraoral systems often face challenges in wearability and user comfort. EPG, EOS, and EMA designs require wired connections to external acquisition systems (as indicated by WDI = Yes in Table 2), making them unsuitable for daily use. Conversely, PMA shows advantages in device compactness, but the tongue-mounted permanent magnet (as indicated by TMI = Yes in Table 2) can reduce user comfort as it has not been optimized for the oral environment. Efforts have been made to improve the compactness of the device and wireless transmission in intraoral systems, such as the tactile oral pad[174], but this oral pad has not yet been applied to SSIs. From a software perspective, intraoral systems have demonstrated promising recognition performance. For instance, both EOS and EPG have achieved great word recognition rates[52,170]. PMA and EMA systems have been applied to both word-level and phoneme-level tasks, often using deep learning models such as RNNs to decode rich spatial-temporal tongue motion data. Signal-to-audio synthesis tasks using intraoral data have also been explored, although many results are not yet benchmarked with standardized accuracy metrics. A detailed discussion of algorithms can be found in Section 4.
Comparisons of representative intraoral systems for SSIs
| Method | Location | Channel amount | WDIa | TMIb | Identification taskc | Dataset | Algorithm | Recognition rated |
| EPG[52] | Hard palate | 124 | Yes | No | Word | 1,164-word | HMM | 93.0% |
| EPG[169] | Hard palate | 124 | Yes | No | Audio | 319-sentence | RNN | / |
| EOS[170] | Hard palate | 39 | Yes | No | Word | 30-word | KNN | 97.0% |
| PMA[158] | Tongue | 72 | No | Yes | Audio | 132-phrase | DNN | / |
| PMA[162] | Tongue | 12 | No | Yes | Audio | 2.55-hour-sentence | RNN | 74.8% |
| PMA[171] | Tongue | / | No | Yes | Phoneme | 25-phoneme | DNN | / |
| EMA[158] | Tongue | 3 | Yes | Yes | Audio | 132-phrase | DNN | / |
| EMA[172] | Tongue | 27 | Yes | Yes | Audio | 354-utterance | RNN/GAN | / |
| EMA[173] | Tongue | 3 | Yes | Yes | Phoneme | 732-phrase | SVM/HMM/GMM/DNN | 73.9% |
High-Fidelity implantable neural interfaces for silent communication
Surgically embedded systems for SSIs are typically BCI devices implanted within or on the surface of the brain to record neural signals related to speech production. Within this category, approaches are distinguished by both their recording locations and specific electrode architectures. Anatomically, subdural sensors rest on the brain’s surface beneath the dura mater, intracortical arrays penetrate directly into the grey matter, and depth modalities target deeper subcortical structures. This section focuses on three primary methods spanning these levels. Regarding recording modalities, systems primarily utilize ECoG for subdural recordings and stereo-electroencephalography (SEEG) for deep cortical and subcortical recordings. In terms of electrode architecture, microelectrode arrays (MEAs) are typically employed to penetrate the cortical tissue. Compared to the EEG methods discussed in Section 3.1, these surgically embedded systems offer high spatial and temporal resolution by capturing cortical activity at or near its source. Although functional magnetic resonance imaging (fMRI)-based BCI has also been applied to SSIs[175], it will not be discussed here as this review focuses on bio-integrated systems.
Figure 10A summarizes the differences between ECoG, MEA, and SEEG based on their anatomical locations and captured signals. These invasive BCI methods are generally used exclusively in clinical cases, such as patients with Amyotrophic Lateral Sclerosis (ALS), and are not applied to healthy individuals. ECoG array rests on the brain surface beneath the dura to monitor cortical activity, avoiding tissue penetration while still requiring craniotomy[21]. They record summed local field potentials (LFPs) with amplitudes typically ranging from tens to hundreds of microvolts, potentially reaching low millivolt levels during intense neural activity[179]. The useful frequency range is typically below 200 Hz[37]. MEA systems (Utah array) insert short pins approximately 0.5 to 1.5 mm into the cortex[180]. While more invasive than ECoG, MEA can detect both LFPs and single-neuron spikes. Spikes represent fast, sharp voltage changes (up to 7 kHz) that reflect the firing of individual neurons, whereas LFPs reflect the combined synaptic activities of a group of neurons[179,181]. SEEG employs thin depth electrodes inserted through small skull openings to access deep brain areas. This method requires less invasive surgery and also records LFPs[179].
Figure 10. Surgically embedded SSIs. (A) Comparison of invasive BCI techniques. The brain anatomy in the middle part of (A): Adapted from Ref. [176], under CC BY 4.0 license. Signals in the right part of (A): Adapted from Ref. [177], under CC BY 4.0 license; (B) ECoG systems for SSIs. Adapted from Ref. [178], under CC BY 4.0 license; (C) MEA systems for SSIs. The surgically embedded devices and positions of (C): Adapted from Ref. [38], under CC BY 4.0 license. SSIs: Silent speech interfaces; BCI: brain-computer interface; ECoG: electrocorticography; MEA: microelectrode array; SEEG: stereo-electroencephalography; LFP: local field potential.
ECoG-based SSIs
ECoG systems have been applied to assist a participant whose speech ability was affected by a severe stroke[37]. In severe cases, patients suffer extensive damage to the left hemisphere, including brainstem atrophy resulting from the stroke. Brainstem atrophy can impair speech abilities because it is responsible for critical neural pathways that coordinate the muscles involved in speech production[182]. Damage to the brainstem area disrupts these pathways, leading to speech disorders such as dysarthria[183]. Despite the injury and disrupted neural pathways, the motor cortex remained viable, allowing placement of a high-density ECoG array to capture neural signals. The implemented array consists of 253 electrodes positioned over regions of the sensorimotor cortex[37]. The sensorimotor cortex is a relatively large area that includes the primary motor cortex and primary somatosensory cortex, covering speech production areas associated with the movement of the face, tongue, jaw, and larynx[184]. This placement allows researchers to capture cortical signals corresponding to articulatory intentions, even though the participant could not physically produce speech.
The sample neural signals were recorded from these electrodes when the participant attempted different articulator movements beyond pure imagined speech[37]. These signals reflect the electrical activity of the brain during attempted speech and exhibit distinct temporal patterns for different activities. The participant used a visual cue system (monitor) to prompt attempted speech, and the resulting ECoG signals were decoded in real time using an RNN. The design and placement of the ECoG array, combined with advanced decoding algorithms, achieve a median WER of 25% on a vocabulary set of 9,655 sentences[37]. Recent developments in specialized, high-resolution ECoG electrode arrays have significantly improved speech decoding[178]. The flexible polymer ECoG electrode array in Figure 10B is equipped with either 128 or 256 micro-electrodes. These tiny sensors are compared against much larger, traditional macro-ECoG setups [Figure 10B, array comparison]. This massive upgrade highlights a jump to 34-57 electrodes per square centimetre [Figure 10B, electrode density]. Such precise placement maps exactly how these high-resolution arrays are implanted directly over the speech motor cortex [Figure 10B, electrode position]. Recent work also extends this technology to continuously streaming neuroprostheses that synthesize speech in 80-ms increments[185]. These models can also personalize the audio output to match a participant’s pre-injury voice. Beyond stroke patients, researchers have successfully applied ECoG-based speech synthesis to individuals with ALS[186]. These systems decode neural activity into intelligible keywords while allowing the user to speak at their own pace. In comparison to the MEA method, ECoG adopts a flat grid placed over a large area of the sensorimotor cortex, enabling broad coverage of speech-related regions. ECoG is less invasive than MEA but lacks single-neuron resolution and cannot access deeper brain structures.
MEA-based SSIs
Similar to ECoG, MEA has been used to develop a high-performance SSI for an ALS patient[38]. The participant is severely dysarthric and cannot produce clear speech, though the partial facial movements are retained. Four MEAs, each with 64 channels, were implanted in the cortex [Figure 10C, Embedded Devices, Sensing Positions], targeting two key regions: Two arrays were positioned in the area of the ventral premotor cortex (area 6v)[187], and the other two arrays were placed in the Broca’s area (area 44)[188] to capture signals associated with facial movements and language planning. The study found that area 6v contains a rich representation of speech articulators. Each array measures 3.2 mm × 3.2 mm and was manufactured by Blackrock Microsystems, featuring 1.5 mm-long silicon microelectrodes coated with iridium oxide. These penetrating electrodes enable single-neuron-level recordings of spiking activities. The implanted MEAs are connected to external recording hardware through a percutaneous pedestal with a wire bundle containing 256 leads [Figure 10C, Component]. Although 256 electrodes were used, neural decoding is primarily driven by the 128 electrodes in area 6v due to their stronger tuning to speech articulators. Data from each electrode is processed in real time using digital filters and algorithms, extracting features including threshold crossings and spike power. These features are fed into an RNN model trained to decode phonemes in real time for reconstructing intended sentences. The MEA system achieves a WER of 9.1% for a 50-word vocabulary and 23.8% for a 125,000-word vocabulary[38]. Compared to ECoG, the MEA system offers much higher spatial resolution and the ability to detect single-neuron activities[189], critical for fine articulatory decoding. Recent studies have expanded the capabilities of MEA-based speech systems by exploring new cortical regions and decoding techniques. MEA devices implanted in the supramarginal gyrus have successfully decoded internal or imagined speech at the single-neuron level[190]. Researchers have also achieved instantaneous voice synthesis by recording neural activity from 256 microelectrodes in the ventral precentral gyrus of a participant with ALS. This closed-loop neuroprosthesis translates cortical signals into audio in real time, allowing the user to consciously modulate their intonation[191]. Furthermore, this high-density setup calibrates rapidly, enabling self-paced conversations at approximately 32 words per minute[192]. However, MEA implantation is more invasive, covers a limited cortical surface area, and may experience signal instability over time.
SEEG-based SSIs
SEEG, as a minimally invasive surgical procedure, is primarily used to identify deep areas in the brain where difficult-to-treat epileptic seizures originate[193]. Researchers have applied SEEG to map speech areas in the brain[194]. During the surgery, surgeons drill small holes in the patient’s skull and use MRI images to guide thin leads to reach the selected cortical and subcortical (white matter) areas. Each SEEG lead comprises 10-18 platinum contacts, with 0.8 mm in diameter, 2 mm contact length, and 1.5 mm inter-contact spacing. Patients performed simple language tasks like naming pictures or saying action words, while SEEG recorded their brain signals. SEEG signals are recorded in bipolar configuration at 1,200 Hz sampling frequency. These signal changes can reveal active speech regions. Notably, this study involved speech region mapping but has not yet applied SEEG to speech reconstruction. Regarding similarities and differences of SEEG to ECoG/MEA, SEEG records LFPs[195], similar to ECoG. Unlike SEEG and ECoG, MEA can also capture single-neuron spikes[189]. However, SEEG’s depth electrodes can monitor brain activities throughout deeper regions, not just on the cortical or subcortical surfaces. SEEG relies on stereotactic implantation through small burr holes, avoiding the need for a large craniotomy. From a surgical access perspective, this skull-level exposure is less invasive than subdural grid placement[196,197]. However, the procedure still requires advancing depth electrodes directly into the gray and white matter, carrying an inherent risk of local neural tissue damage[198]. Therefore, labeling SEEG as “less invasive” strictly refers to the cranial opening. This physical disruption of internal tissue should be accounted for when evaluating the total system safety. Consequently, SEEG offers a favorable balance between invasiveness, coverage, and functional mapping capabilities, though its potential for speech reconstruction has not been explored as thoroughly as ECoG and MEA. To address the historical lack of SEEG data, researchers have recently introduced comprehensive datasets capturing vocalized, mimed, and imagined speech modes[199]. This includes expanding SEEG research to tonal languages like Mandarin Chinese, where variations in pitch necessitate highly nuanced decoding algorithms. Beyond discrete word recognition, recent studies demonstrate that the continuous acoustic speech envelope can be successfully reconstructed from SEEG signals[200].
Comparisons of surgically embedded systems for SSIs
As detailed above and in Table 3, the surgically embedded system represents the most invasive but also the most information-rich modality of SSIs. From a hardware standpoint, ECoG and MEA require craniotomy, with MEA being more invasive due to its penetration through cortical gray matter (see columns “Location” and “Surgery Invasiveness” in Table 3). SEEG offers a less invasive approach because it requires only burr holes for inserting electrode shafts. All three methods can provide hundreds of channels of signal for speech recognition (see column “Channel Amount” in Table 3). MEA can provide neural signals (spikes) with the highest resolution among the three methods, albeit at the expense of increased invasiveness. From the software perspective, ECoG and MEA have shown promising performance in decoding speech at the phoneme and word levels. ECoG has also been applied to signal-to-audio synthesis[39]. SEEG, while less extensively studied compared to the other two methods, has shown moderate recognition performance in word-level recognition and signal-to-audio synthesis[204,205]. A more detailed discussion of word-level, phoneme-level, and audio synthesis can be found in Section 4.
Comparisons of representative surgically embedded systems for SSIs
| Method | Location | Channel amount | Surgery invasivenessa | Identification taskc | Dataset | Algorithm | Recognition rated |
| ECoG[37] | Cortical surface | 253 | Medium | Phoneme | 9,655-sentence | RNN | 75.0% |
| ECoG[39] | Cortical surface | 64 or 128 | Medium | Audio | 50-word | CNN/RNN/Transformer | / |
| ECoG[201] | Cortical surface | 60 | Medium | Word | 6-word | CNN | 85.2% |
| ECoG[202] | Cortical surface | 64 | Medium | Word | (244-372)-word | CNN | / |
| MEA[38] | Cortical gray matter | 256 | High | Phoneme | 125,000-word | RNN | 76.2% |
| MEA[203] | Cortical gray matter | 96 | High | Word | 8-word | LDA/SVM | 91% |
| SEEG[195] | Cortex & subcortex | < 256 | Low | Mappingb | / | / | / |
| SEEG[204] | Cortex & subcortex | / | Low | Audio | 100-word | RNN/Transformer | / |
| SEEG[205] | Cortex & subcortex | 6 | Low | Word | 27-word | CNN/RNN | 55% |
System Benchmarking: A Trade-Off Analysis of SSI Platforms
As shown in Table 4, the three modalities of SSIs (epidermal, intraoral, and surgically embedded systems) differ in sensor placement and configuration, stages of the speech process that they capture, and levels of user burden. These differences create distinct advantages and limitations for each approach.
Comparisons of bio-integrated SSIs based on the level of physical intrusion
| Modality | Methoda | Location | Channel amountb | Informative band (Hz)c | Signal interferenced | Portability | Recognition ratee |
| Epidermal | EMG | Cheek/neck | ≲ 8 | 20-500[67,68] | M | Yes | Medium |
| EEG | Scalp | ≲ 64 | γ: 70-150 δ: 0.5-4 θ: 4-8[100-102] | M, P | Yes | Low | |
| IMU | Cheek/chin/neck/lip/jaw | ≲ 18f | 0-20 | M | Yes | Medium | |
| Strain-facial | Cheek | ≲ 8 | 0-20 | M | Yes | Low | |
| Strain-throat | Throat | 1 | \g | M | Yes | Low | |
| Intraoral | EPG | Hard palate | ≲ 124 | 0-20 | M | Yes | Medium |
| EOS | Hard palate | ≲ 5 optical; ≲ 32 EPG | 0-20 | M | Yes | Medium | |
| PMA | Tongue | ≲ 72 | 0-20 | E, M | Yes | Medium | |
| EMA | Tongue | ≲ 27 | 0-20 | E, M | No | Medium | |
| Surgically Embedded | ECoG | Cortical surface | ≲ 253 | high: 70-150 low: 0.3-17[37] | M, P | No | High |
| MEA | Cortical gray matter | ≲ 256 | 125-5,000[206] | M, P | No | High | |
| SEEG | Cortex & subcortex | ≲ 256 | 60-200[204] | M, P | No | Low |
Epidermal systems are applied directly to the skin surface and are better suited for long-term use. They offer the most practical solution for widespread adoption. Among them, surface EMG electrodes placed on the face or neck can detect muscular activities in an informative band of 20-500 Hz, with demonstrated accuracy for phoneme‑level decoding. However, the signals are sensitive to motion artifacts and require precise placement during repeated removal and reattachment. Scalp EEG systems share the advantage of being non-invasive, but the acquired signals are extremely weak and can be easily affected by the skull and hair. The low SNRs reduce speech recognition accuracy despite the availability of high channel counts and access to low-frequency brain rhythms. IMUs and soft strain sensors, typically attached to the chin or throat, are more robust against electrical noise because they capture low-frequency mechanical movements, typically below 20 Hz[210,211]. These systems are easy to wear and relatively comfortable. However, their limited signal bandwidth and vulnerability to head movements reduce their ability to capture detailed speech information. Among them, throat-mounted strain sensors have yet to achieve phoneme-level decoding in the current literature.
As more invasive but potentially more accurate approaches, intraoral systems require sensors to be placed inside the mouth, allowing articulatory movements to be captured closer to their source while remaining removable. These systems demonstrate varied sensing principles and performance characteristics. EPG systems employ a thin electrode array attached to the hard palate to detect the pressure patterns induced by tongue contact. The high spatial resolution enables accurate phoneme recognition; however, the wired setup and need for a custom dental plate limit their comfort and social acceptability. EOS systems[151] rely on optical distance sensors (light emitters and photodiodes) to provide both contact and proximity sensing capabilities for tongue movements, but they also require a wired setup and need precise calibration of optical sensors to function properly. PMA systems[158,162] employ small magnets attached to the tongue and magnetometers positioned on the wearable headphone, which enable three-dimensional tracking with a more compact and wireless setup. However, the magnets pose a swallowing risk and are vulnerable to interference from external magnetic fields. EMA methods achieve the highest positional accuracy among intraoral methods by detecting induced voltages in coil receivers within a controlled electromagnetic field. Their bulky wired setup and sensitivity to metal objects restrict their use to laboratory environments.
At the highest level of invasiveness, surgically embedded interfaces possess high signal fidelity. ECoG arrays are placed on the cortical surface, recording LFPs with broad coverage across speech-related areas[189]. This method involves moderate surgical risk and has demonstrated strong decoding performance. MEA systems require deeper insertion of microneedles into the gray matter to capture single-neuron spikes at kHz frequencies. While this method provides exceptional temporal resolution, it comes with higher risks, including potential tissue damage and reduced coverage area. SEEG uses depth electrodes inserted through small skull openings to reach both cortical and subcortical regions. This method is able to capture mid-frequency LFP without the need for a full craniotomy. Despite their signal quality advantages, all implanted systems share significant limitations: They are impractical for healthy individuals and offer virtually no portability. For patients with severe motor impairments who require assistive communication devices, however, these implanted systems remain the most powerful option for accessing detailed neural signals.
Selecting a sensing modality fundamentally impacts information bandwidth and signal fidelity. Surgically embedded implants record localized action potentials directly. This direct access yields the highest possible information bandwidth[212]. Epidermal systems, in contrast, need to overcome physical barriers, such as skin and underlying tissue impedance, which severely attenuate the source signals and result in much lower signal fidelity and spatial resolution. Recent hardware innovations are shifting the paradigm. High-density epidermal arrays now dramatically increase sensor channel counts[213], potentially narrowing the performance gap between non-invasive wearables and invasive implants.
Cost and accessibility vary drastically across sensing modalities. Off-body and epidermal systems that employ commodity hardware and scalable manufacturing offer the most accessible entry point[16]. Intraoral devices often require custom dental molding and specialized fitting. Surgically implanted systems remain entirely cost-prohibitive for the general public. They require invasive neurosurgery, highly custom-designed solutions, and rigorous clinical oversight[5]. Currently, implants are strictly limited to patients with severe motor impairments. Future hardware development must bridge this economic gap to make SSIs widely accessible.
Overall, the design of each SSI system necessitates a broad range of trade-offs: The closer the sensors are to the brain, the richer the acquired information, and the higher the decoding accuracy. These advantages, however, are obtained at the cost of greater invasiveness, elevated maintenance challenges, and reduced user acceptability. Therefore, each design demands a careful balance between performance and practicality.
ML-ASSISTED ADVANCED SIGNAL PROCESSING AND DEEP DECODING OF SILENT INTENT
This section focuses on the signal processing pipeline, outlining key steps such as signal preprocessing, feature extraction, model architecture, and evaluation metrics across different SSI modalities.
Biosignal preprocessing for enhanced clarity
Signal preprocessing is a critical stage in SSR, directly influencing model accuracy and generalization. It reduces noise in biosignals while preserving task-relevant features essential for reliable speech decoding. Normalization and synchronization address temporal and amplitude variability, which is particularly important for multimodal integration. Signal segmentation further structures continuous input into linguistically meaningful units, enabling efficient and precise modeling. Collectively, these steps constitute the foundation of a robust SSR pipeline.
Noise reduction
Preprocessing in SSR typically begins with modality-specific noise reduction techniques, forming the first step toward reliable signal representation. The biosignals used in SSR, such as sEMG and EEG signals, are inherently susceptible to various sources of noise, including motion artifacts, sensor drift, and powerline interference. To address this, tailored denoising strategies are applied. In sEMG, bandpass filtering (e.g., 20-500 Hz[67,68]) is commonly used to eliminate low-frequency motion artifacts and high-frequency noises, while the notch filter (50/60 Hz)[23] is used to mitigate the impact of powerline interference. For EEG, methods like common spatial patterns (CSP)[214] and independent component analysis (ICA)[215] can help isolate task-relevant neural signals from background activity. Additionally, the wavelet transform[216] is broadly employed across modalities to suppress transient disturbances while preserving essential signal characteristics. These noise reduction steps not only improve signal quality but also serve as a prerequisite for accurate recognition and robust cross-condition generalization.
Normalization and synchronization
The variability introduced by differences in subjects, sessions, and sensor setups poses a key challenge for SSR, which can be addressed through effective normalization and synchronization. Normalization ensures that signal amplitudes and distributions are consistent across conditions, enabling models to focus on task-relevant variations rather than irrelevant fluctuations. Different normalization strategies are applied depending on the structure of the data and the model architecture. Feature normalization methods, such as z-score normalization, min-max scaling, and channel-wise standardization, are commonly used in the preprocessing stage to align signal scales across users or sessions[217]. These approaches are particularly effective for biosignals like sEMG, where different channels may exhibit distinct baseline characteristics. In deep learning-based SSR systems, normalization may also occur within the model. Batch normalization[218], which normalizes inputs across the batch dimension during training, helps stabilize learning and accelerates convergence, especially in convolutional architectures. However, in sequential models such as RNNs or Transformers, where batch statistics vary over time, alternative strategies are often preferred. Temporal normalization, for instance, normalizes signal features along the time axis and is useful in handling signal drift and session-specific shifts[219]. Similarly, instance normalization and layer normalization[220,221], which operate at the sample or layer level, are beneficial in real-time SSR scenarios where batch sizes may be small or inconsistent. Synchronization complements normalization by ensuring temporal alignment across different modalities. This is especially critical in multimodal SSR systems that combine, for example, sEMG and lip imagery[222]. Methods such as cross-correlation, energy-based alignment, and the use of external triggers help maintain semantic consistency across input streams. Together, normalization and synchronization significantly improve recognition accuracy, enable effective multimodal integration, and support the development of robust, generalizable SSR systems.
Signal segmentation
Segmentation transforms continuous biosignals into modeling-ready units, such as phonemes, words, or sentences, and is a crucial step in SSR preprocessing. By converting raw, unstructured signals into discrete chunks, segmentation enables models to better capture the temporal and linguistic structure of speech. Traditionally, fixed-size sliding windows, typically 30 to 50 milliseconds and having overlaps between windows, are used, as they roughly match the duration of phonemes[67,223]. These overlapping windows help capture local articulatory dynamics and provide uniform inputs for downstream processing. However, static segmentation schemes struggle with natural variability in speech rate and articulation. In fast or slow speech, fixed windows may misalign with actual phoneme boundaries, leading to degraded performance. To overcome this limitation, adaptive segmentation methods have been introduced. For instance, dynamic time warping (DTW) aligns utterances by minimizing temporal distortion across articulatory patterns[224]. In higher-level tasks, such as sentence-level SSR, hierarchical segmentation is often applied. This involves first detecting word-level pauses or silences and then segmenting those regions further into phonemic units[12]. Such multi-scale segmentation improves linguistic alignment and model interpretability. Segmentation also impacts computational complexity. Smaller windows offer higher temporal resolution but result in longer sequences and increased memory usage, while larger or adaptive segments reduce computational load but may sacrifice detail. Therefore, effective segmentation balances linguistic precision with efficiency. Ultimately, segmentation supports both accurate modeling and practical deployment, making it a foundational component of robust SSR systems.
Feature engineering and selection
Once biosignals have been preprocessed, the next critical step in the SSR pipeline is feature extraction. This stage translates signals into structured representations that are more amenable to ML and classification. Effective feature extraction bridges the gap between low-level physiological signals and high-level linguistic interpretation. Broadly, features used in SSR can be categorized into handcrafted descriptors based on signal processing techniques and learned representations derived from data-driven models such as deep neural networks (DNN). Both approaches have their strengths, and many SSR systems benefit from combining them.
Handcrafted features in time and frequency domain
Handcrafted features form the foundation of early SSR systems and remain widely used due to their interpretability and simplicity. In the time domain, statistical features such as root mean square (RMS), zero crossing rate (ZCR), mean absolute value (MAV), and integrated EMG (IEMG) are commonly extracted to characterize signal energy, muscle activation, and waveform complexity[225]. These features are particularly informative in EMG and EEG-based SSR tasks, where temporal fluctuations correspond to articulatory muscle activities or cortical responses. In the frequency domain, spectral analysis techniques help capture phoneme-level acoustic or articulatory characteristics. Power Spectral Density (PSD) and Short-Time Fourier Transform (STFT) reveal frequency-specific energy distributions, which are useful in distinguishing different speech gestures[226,227]. Time-frequency representations, such as Continuous Wavelet Transform (CWT)[228], further improve robustness by capturing localized spectral variations over time, especially important for nonstationary signals like ultrasound. Among the most widely used handcrafted descriptors are Mel-Frequency Cepstral Coefficients (MFCCs), originally developed for acoustic speech recognition[229]. In SSR, MFCCs have been adapted by computing them on transformed biosignals, such as EMG spectrograms or lip imagery treated as pseudo-spectrograms. While this allows for the reuse of well-understood features, MFCCs rely on perceptual auditory scaling, which may not always align with the physical properties of biosignals like EMG or EEG, limiting their interpretability in non-acoustic modalities.
Learned features from deep models
To overcome the limitations of manually designed features, modern SSR systems increasingly rely on learned features derived from data-driven models. Deep learning, particularly using CNNs, has become the dominant framework for feature extraction in recent SSR research. CNNs are especially well-suited for 2D and 3D inputs such as spectrograms, lip images, or ultrasound frames. These networks automatically learn hierarchical representations, capturing both low-level textures and high-level articulatory patterns without manual engineering. In high-density sEMG (HD-sEMG) applications, CNNs are often used to extract spatiotemporal activation maps, which encode channel-wise information across time and frequency[213]. These learned features have been shown to improve both phoneme and word-level classification performance. For image-based modalities such as lip or tongue motion, CNNs can be applied directly to raw image frames or processed representations such as motion fields[230]. In 3D CNN architectures, temporal sequences of images are input as volumetric data, allowing the model to simultaneously capture spatial and temporal correlations. To further improve spatial sensitivity, attention mechanisms can be integrated into CNNs, allowing the network to focus on informative regions while ignoring background noise or irrelevant areas[231]. Some SSR systems employ hybrid approaches, feeding handcrafted features such as MFCCs or CWT coefficients into CNNs. This allows the model to benefit from the domain knowledge embedded in handcrafted features while gaining the adaptability of learned representations[232]. Importantly, learned features offer greater flexibility and generalization compared to handcrafted ones. They can adapt to varying signal modalities, speaker-specific traits, and environmental conditions, making them particularly valuable in large-scale or cross-subject SSR applications. Moreover, the ability to fine-tune learned representations using end-to-end training pipelines facilitates joint optimization of feature extraction and classification. In summary, both handcrafted and learned features play complementary roles in SSR, and the choice or combination of feature extraction methods directly influences system performance, adaptability, and scalability.
Data augmentation is particularly important for SSIs due to the scarcity and high acquisition cost of physiological signals. Recent work has explored augmentation strategies directly on articulatory time-series, extending concepts from SpecAugment to non-acoustic modalities[233]. These include time masking and articulatory-dimension masking to simulate temporal dropout and sensor corruption, as well as signal-level perturbations (such as noise injection and temporal scaling) to model variability in sensor noise and speaking rate[234]. In contrast to conventional audio augmentation, these approaches preserve underlying articulatory dynamics while introducing controlled variability, which improves model robustness in low-resource SSI settings.
Deep decoding: architectures for continuous and open-vocabulary recognition
Model architectures in SSR have been developed along multiple directions, from traditional statistical methods to advanced deep learning approaches. This evolution reflects not only progress in ML techniques but also the need to address diverse challenges across different SSR tasks. Conventional models offer simplicity and interpretability, making them suitable for scenarios with limited data or strict real-time constraints. In contrast, deep learning architectures - particularly end-to-end and multimodal designs - are more capable of handling complex input patterns, large datasets, and speaker variability. This section reviews the development of SSR modeling approaches and examines how different architectures align with specific application requirements.
Traditional sequence models
Before the adoption of deep learning techniques, SSR systems largely relied on statistical models such as HMMs and GMMs[27,28]. These approaches followed a structured pipeline comprising sequential stages: signal segmentation, handcrafted feature extraction, and statistical classification. Among these, HMM-GMM frameworks were particularly prominent for modeling the temporal dynamics of biosignals, especially in sEMG-based SSR. An HMM represents a sequence of observed data as a series of hidden states, where each state has a probability distribution over the possible observations. Transitions between states follow a Markov process, meaning the current state depends only on the previous state. In the context of SSR, each state is typically associated with a subunit of speech, such as a phoneme or syllable, and observations correspond to extracted features from the biosignals, such as MFCCs or RMS energy. GMMs are often used to model the emission probabilities, capturing the variability of feature vectors within each state[4,19,26,50,235-238]. For example, in the EMG-PIT corpus[239], sEMG signals are segmented into fixed-size windows and transformed into MFCC or RMS features. These are then used to train an HMM where each word or phrase is represented by a sequence of states with learned transition and output probabilities. This framework allows the system to capture local temporal dependencies and perform sequence decoding via algorithms such as the Viterbi algorithm[240]. In visual modalities such as ultrasound or lip video, traditional classifiers including Support Vector Machines (SVMs) and Random Forests (RFs) were commonly employed, often with frame-level features[52,241,242]. While these methods are computationally efficient and relatively interpretable, they have several limitations. They require extensive feature engineering and lack the ability to model long-range dependencies. Moreover, their generalization across speakers, sessions, and noise conditions is often poor, which restricts their scalability in real-world SSR applications.
Deep learning models
The introduction of RNNs marked a major shift in SSR, moving away from rigid, handcrafted pipelines toward data-driven, end-to-end learning. RNNs are specifically designed to handle sequential data by maintaining an internal memory of past inputs, making them well-suited for modeling the temporal dynamics of biosignals such as EMG, EEG, or lip movement sequences[234,243-248]. Unlike HMMs, which rely on predefined state transitions and assume conditional independence between observations, RNNs are capable of learning complex, long-range temporal dependencies directly from data without strong assumptions about sequence structure.
Among RNN variants, Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) have become the most widely used in SSR tasks due to their ability to avoid the vanishing gradient problem inherent in standard RNNs. These gated architectures maintain memory over longer time horizons and selectively update internal states based on input relevance. This enables more accurate modeling of articulatory patterns that span multiple frames, which is particularly important in biosignals that exhibit temporal variability and nonstationarity. Bidirectional RNNs (BiRNNs) further enhance the modeling capability by incorporating both past and future context into the hidden state representation[249-251]. This dual perspective is especially valuable in SSR, where signal noise, delays, or articulation ambiguity may obscure the correct interpretation of a phoneme or word when viewed in isolation.
These architectures have been successfully deployed in SSR systems such as EarSSR[248], which uses sEMG signals, and LipWatch[24], which uses lip video inputs. Both systems combine RNN encoders with CTC decoders, allowing the model to learn alignments between input features and output sequences without needing frame-level labels. The CTC objective function introduces a blank symbol and multiple alignment paths, making it robust to uncertain or variable-length input-output correspondences. A common SSR architecture today is the hybrid CNN-RNN-CTC pipeline. In this design, CNNs serve as front-end feature extractors for spatial or spatiotemporal representations, such as spectrograms or lip image sequences, while RNNs model the temporal evolution of these features[252-254]. CTC decoding then enables flexible output prediction, even in the presence of inconsistent alignment across training samples. Compared to traditional HMMs, which require explicit state definitions and emission models, this pipeline learns both representation and alignment jointly, resulting in more adaptive and scalable systems.
In addition to improved performance, deep learning models offer better generalization across subjects and recording conditions, especially when combined with regularization strategies, data augmentation, or domain adaptation. As such, RNN-based architectures represent a foundational step in the transition from handcrafted SSR pipelines to fully trainable, end-to-end learning systems.
In recent years, Transformer-based architectures have emerged as a powerful alternative to RNNs for modeling sequential data[59]. Transformers use self-attention mechanisms to capture global dependencies in the input without relying on recurrence. This allows for parallel computation, significantly improving training efficiency and scalability for long sequences. Transformers compute attention scores between all input positions, enabling the model to directly relate distant time steps - an advantage particularly relevant for SSR, where articulatory cues or EMG patterns at one time may depend on earlier or later contexts[30,44,255-260]. Recent adaptations such as Lightweight Transformers or Conformer architectures, which combine convolution and attention, have also been proposed to reduce computational complexity and latency, making real-time or on-device SSR applications more feasible[253]. Deploying SSR on wearable interfaces imposes strict constraints on inference latency and computational load. While heavy architectures, such as standard Transformers, can achieve high accuracy, they incur memory and power costs that far exceed the capabilities of edge microcontrollers. Consequently, on-device implementation requires aggressive architectural optimization to maintain real-time responsiveness while minimizing battery drain[261]. To achieve this, standard compression strategies such as model pruning, knowledge distillation, and low-bit weight quantization are widely explored[262]. Additionally, replacing computationally expensive self-attention mechanisms with lightweight, convolution-dominant temporal networks has recently enabled low inference latencies on edge-AI platforms[263]. In addition, pretrained Transformer models, when fine-tuned on SSR data, show promise for transfer learning and cross-subject generalization, particularly in low-data settings[256]. Overall, the introduction of Transformer-based models marks a new phase in SSR development, offering flexible, scalable, and highly expressive modeling capabilities that outperform RNNs in many settings. As SSR datasets grow in size and modality diversity, Transformer architectures are expected to play an increasingly central role in future research and deployment.
End-to-end pipelines and cross-modal fusions
End-to-end SSR systems aim to directly map raw or minimally processed signals to linguistic outputs. A key enabler is CTC, which removes the need for manual alignment[241,264]. CTC-based decoders, when paired with CNN or RNN encoders, allow flexible training from unsegmented data, making them especially suitable for SSR tasks with weak supervision. In multimodal fusion settings, systems like mSilent[255] or EarCommand[265] incorporate inputs from different sensor streams. Here, multi-stream CNNs or attention-based fusion layers integrate modality-specific features before sequence modeling. This enables richer representations and improves robustness. Residual CNNs, depthwise separable convolutions, and lightweight architectures further support real-time deployment on wearable devices. Recent work in SSR adopts modular architectures that separate signal encoding from language modeling. Transformer-based encoders extract structured representations from non-acoustic inputs (e.g., lip movements or EMG), while large language models (LLMs) serve as semantic decoders that resolve ambiguity and improve linguistic consistency[266,267]. Integration of LLMs with perceptual front ends significantly reduces WER by leveraging strong language priors, either through direct conditioning (e.g., prompt-based decoding) or post-hoc correction of predicted sequences. In addition, Transformer-based cross-attention supports multimodal fusion, allowing alignment of complementary signals such as EMG and visual features within a unified representation[268]. These approaches improve robustness, particularly in low-resource and cross-subject SSR scenarios[268]. Recent efforts also explore adversarial training or domain adaptation (e.g., Mordo2[254]) to enhance generalization across subjects. Inter-subject variability in physiological signals motivates the use of domain adaptation techniques. Adversarial approaches such as adaptive domain adversarial neural network (TADANN)[269] and its variants[42] learn domain-invariant representations through discriminator to align feature distributions across subjects. Discrepancy-based methods, particularly maximum mean discrepancy (MMD), explicitly minimize the distribution differences in feature space and are often combined with adversarial training. Such hybrid approaches reduce cross-subject performance degradation in EMG-based SSR, especially under limited-data settings[270]. Collectively, these deep learning frameworks represent the most scalable and effective SSR modeling paradigm.
Signal-to-text vs. signal-to-audio
SSR systems typically aim for one of two types of outputs: signal-to-text or signal-to-audio. The majority of existing research focuses on signal-to-text systems, which translate biosignals into discrete linguistic tokens such as phonemes, words, or full sentences. These systems are well aligned with traditional ASR frameworks and are commonly evaluated using standard metrics such as WER[271]. Their popularity stems from the relative ease of supervision, availability of text-labeled datasets, and the clear interpretability of symbolic outputs. In contrast, signal-to-audio systems seek to reconstruct acoustic speech waveforms from articulatory or physiological inputs. These systems typically employ regression-based architectures and are evaluated using perceptual quality metrics, such as Perceptual Evaluation of Speech Quality (PESQ) or intelligibility scores[272]. Unlike classification-based signal-to-text systems, signal-to-audio pipelines must learn precise, fine-grained mappings from articulatory dynamics to acoustic features, making the task significantly more challenging. Temporal alignment and prosodic control further increase the modeling complexity. Due to the difficulty of acquiring high-quality parallel bio signal-speech waveform data, signal-to-audio SSR remains a relatively underexplored area. A limited number of systems (e.g., articulatory-to-waveform synthesis models[30]) have attempted this task, but they are often constrained by data sparsity, modality noise, and high computational demands. Despite these challenges, signal-to-audio SSR holds promise for applications in speech prostheses or silent communication interfaces where natural-sounding output is desired. Continued progress in generative modeling, such as diffusion models or neural vocoders, may eventually help close the gap between articulatory signals and intelligible speech reconstruction. Recent work also considers edge-oriented deployment strategies for wearable SSI systems, including model compression and knowledge distillation to reduce computational and memory requirement. Knowledge distillation allows compact models to retain performance by transferring information from larger teacher networks, which supports real-time on-device inference[273].
Standardized metrics for SSI performance
As shown in Table 5, the evaluation of SSR can begin with a comprehensive characterization of the dataset. Key dataset characteristics include the number of unique words, total number of words, and number of sentences, which collectively describe the vocabulary diversity and scale of the training and testing data[21]. The dataset length measured in hours serves as a crucial indicator of the temporal scope and depth of the collected biosignal data.
Evaluation metrics for silent speech recognition
| Metric family | Metric name | What they capture |
| Dataset metrics | Number of unique words | These metrics describe how wide and varied the words and sentences are in the training and testing sets |
| Number of words | ||
| Number of sentences | ||
| Dataset length (in hours) | ||
| Signal-to-text | Word error rate (WER) | These metrics show how accurately and quickly a model can convert signals into written text |
| Phoneme error rate (PER) | ||
| Character error rate (CER) | ||
| Words per minute decoded (WPM) | ||
| Signal-to-audio | Mel-cepstral distortion (MCD) | These metrics measure how clearly and fast the model can turn signals into audio |
| Human-transcribed WER | ||
| System latency |
For signal-to-text SSR systems, WER remains the widely adopted metric [Table 5]. WER quantifies recognition performance by measuring the number of insertions, deletions, and substitutions needed to match the predicted text with the ground truth transcription[271]. As a direct inheritance from conventional ASR, WER offers an intuitive and standardized way to compare system performance. In small-vocabulary or command-based SSR applications, token-level accuracy, such as classification accuracy, is often reported. For applications requiring finer-grained evaluation, Phoneme Error Rate (PER) is employed to assess articulation recognition at the phoneme level, while Character Error Rate (CER) provides character-level accuracy assessment, as shown in Table 5. Additionally, Words per Minute Decoded (WPM) serves as a temporal performance metric, measuring both accuracy and processing speed, which is crucial for real-time applications. When SSR involves segmentation tasks or keyword spotting, traditional information retrieval metrics such as precision, recall, and F1-score become relevant[274]. Additionally, speaker-dependent versus speaker-independent performance is commonly compared to assess system generalization. This distinction is especially critical in SSR, where cross-subject variability in biosignals is typically high, and generalizability remains a key challenge.
In contrast, signal-to-audio SSR systems aim to synthesize natural and intelligible speech waveforms from articulatory inputs. Their evaluation focuses on perceptual quality and intelligibility rather than discrete token accuracy. Mel-Cepstral Distortion (MCD) serves as a key objective measure, calculated as the Euclidean distance between mel-cepstral coefficients extracted from synthesized and reference audio frames, typically averaged across all frames in the utterance. MCD values are expressed in decibels, where lower values indicate better spectral matching[272,275]. Human-transcribed WER provides a bridge between objective and subjective evaluation, measuring intelligibility through human perception of the synthesized audio. System latency, defined as the elapsed time from the onset of an intended speech attempt to the onset of synthesized audio[21], becomes critical in audio synthesis applications where real-time performance is essential for practical deployment and user acceptance. The evaluation of signal-to-audio systems often requires a combination of objective and subjective measures, as the lack of aligned acoustic speech data, particularly in applications involving laryngectomy patients or truly silent speech scenarios, makes standardized evaluation more challenging than text-based approaches.
TRANSLATING SILENT SPEECH INTO PRACTICAL DEPLOYMENT
Compared with voice-based spoken communications, SSIs can be used when acoustic signals are infeasible, unreliable, or inappropriate. This section summarizes several representative applications of SSIs, including assistive technologies, HMIs, and security applications [Figures 11 and 12].
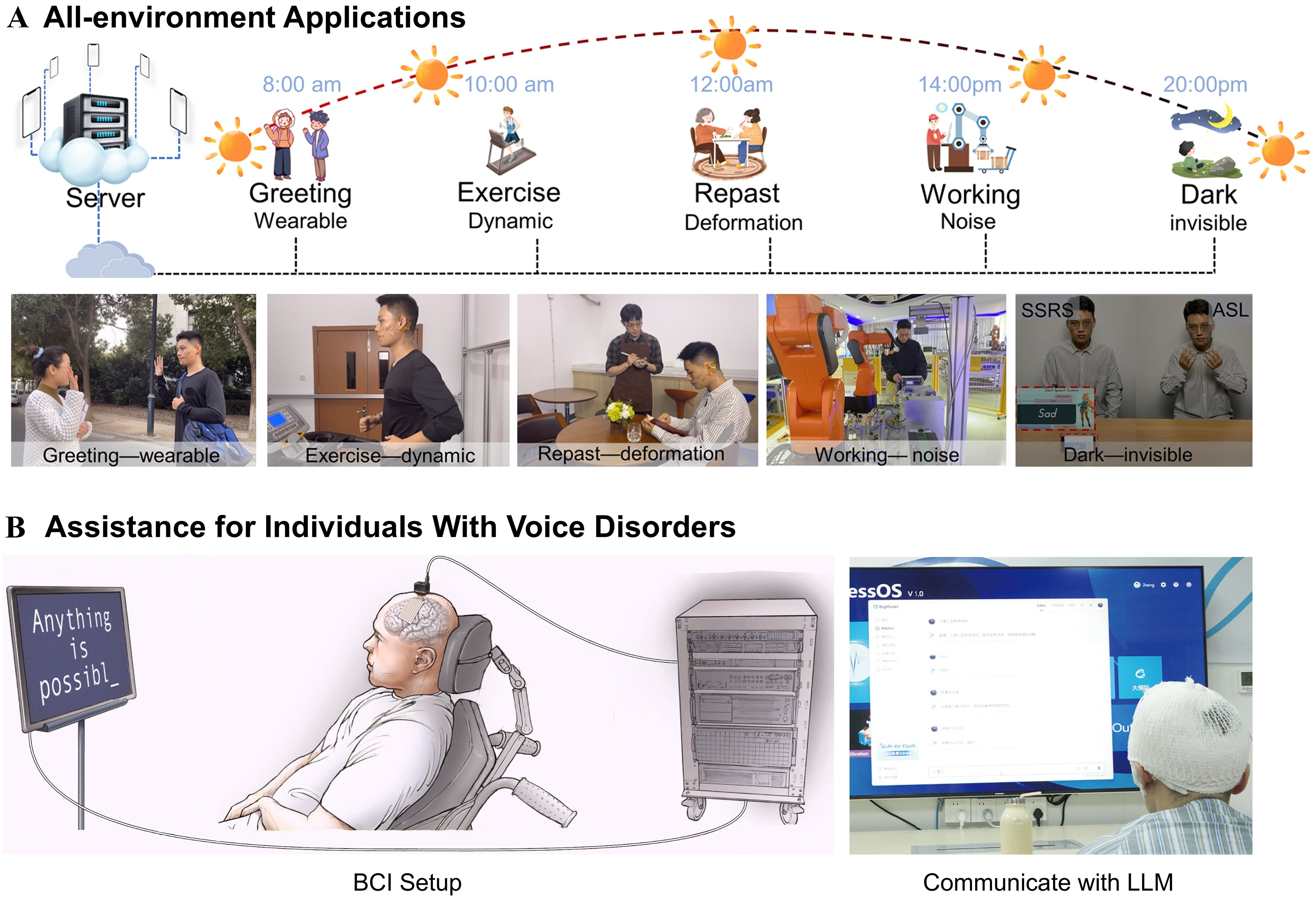
Figure 11. SSIs enabled all-environment applications and assistant devices. (A) All-environment applications for the whole day. Adapted from Ref. [63], under CC BY 4.0 license; (B) Assistance for individuals with voice disorders and applications with LLM. BCI setup in the left part of (B): Adapted from Ref. [35], under CC BY 4.0 license. Communicate with LLM in the right part of (B): Adapted from Ref. [276], under CC BY 4.0 license. SSIs: Silent speech interfaces; LLM: large language model; BCI: brain-computer interface; SSRS: silent speech recognition system; ASL: American sign language.
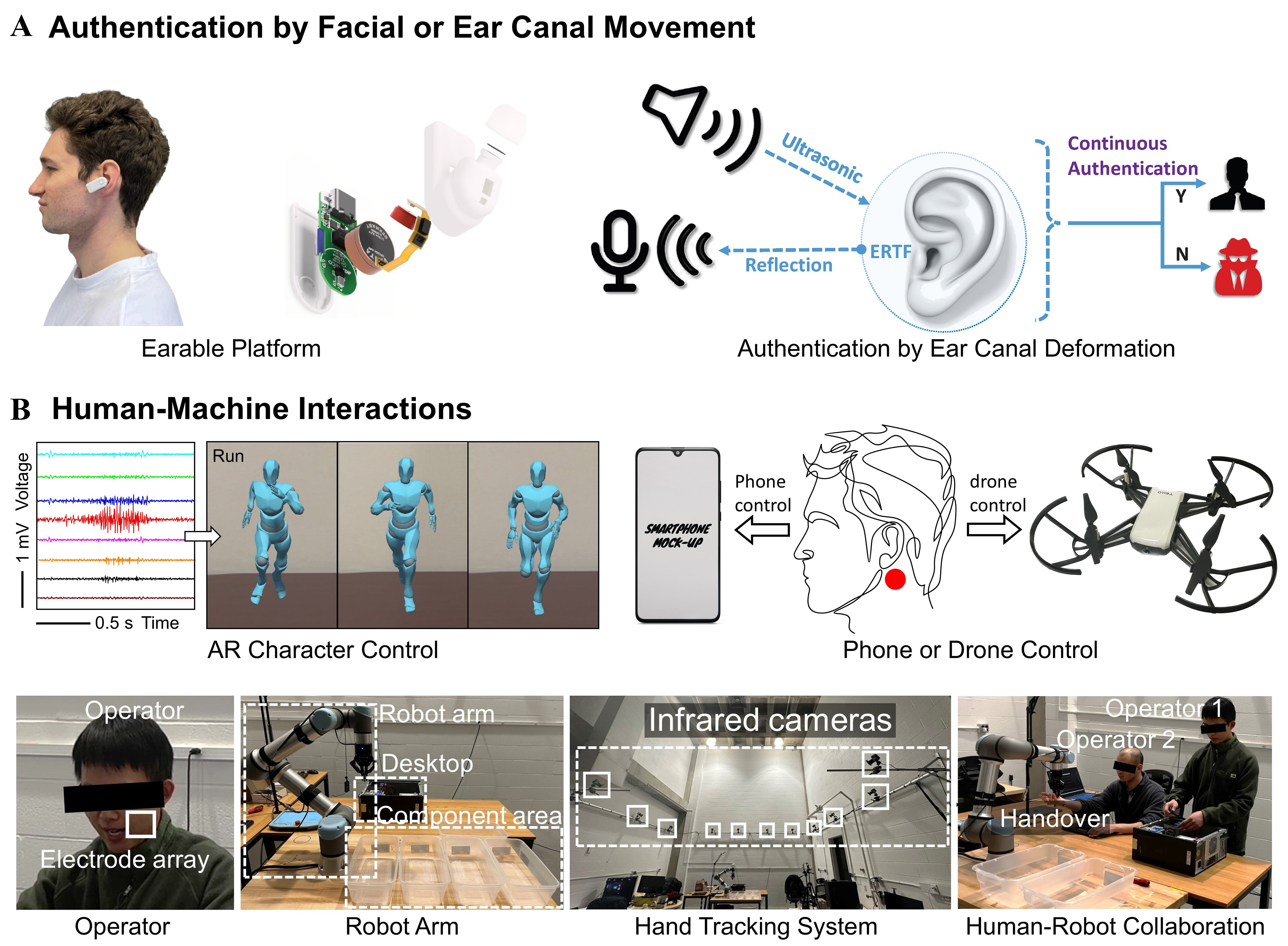
Figure 12. SSIs enabled applications in authentication and interactions. (A) Authentication for security applications. Earable platform in the left part of (A): Adapted from Ref. [277], under CC BY 4.0 license. Authentication by ear canal deformation in the right part of (A): Adapted from Ref. [278], under CC BY 4.0 license. (B) Human-machine interactions. AR character control: Adapted with permission from Ref. [5] Copyright 2023, Wiley-VCH. Phone or Drone Control: Adapted with permission from Ref. [115] Copyright 2023, RSC. Human-Robot Collaborations: Adapted with permission from Ref. [64] Copyright 2025, Wiley-VCH. SSIs: Silent speech interfaces; AR: augmented reality.
Communication in challenging environments beyond acoustics
SSIs allow spoken communications in all-environment applications. They enable voiceless conversations that maintain confidentiality and minimize disturbance in libraries, hospitals, or other quiet zones. They also remain intelligible in high-noise and low-light settings, such as disaster scenes or factory floors, where acoustic speech recognition quickly breaks down. Figure 11A presents several examples that feature versatile all-environment applications of wireless EMG-based SSIs[63]. This setup enables users to communicate silently and naturally across various daily scenarios. Whether greeting a friend, exercising, dining out, operating machinery in noisy environments, or expressing emotions in complete darkness, the system maintains reliable signal quality and communication capabilities. Because the system does not rely on sound or visible facial cues, it works effectively in quiet zones, noisy industrial areas, and during nighttime. These examples show that SSIs can serve as hands-free, intuitive alternatives to traditional voice- or gesture-based systems, suitable for both public and private settings.
Assistive technology for restoring voice
As an effective alternative to voice-based communication interfaces, SSIs are being pursued over the long term to help people with voice disorders, for instance, people with ALS, who may not be able to produce speech sounds[186]. Recent ECoG-based systems have helped these individuals produce clear words at a steady pace and even control a talking facial avatar[34,37]. As shown in Figure 11B, brain signals are captured during silent speech attempts using a high-density ECoG array implanted in the speech-motor cortex (detailed in Section 3.3.1). These signals are further decoded into articulatory gestures to animate a realistic 3D facial avatar[37]. The avatar reflects lip movements, jaw motions, and other facial expressions, allowing users to communicate in a way that includes both verbal content and non-verbal cues such as emotions or intentions. The ability to convey facial expressions during speech makes communication more natural and personal, beyond what can be provided by eye-tracking. This approach supports more natural and expressive communication, particularly in digital or virtual settings. Building upon current SSIs, recent advancements in Mandarin-based BCIs have further expanded these capabilities by integrating LLMs to facilitate complex interactions [Figure 11B, communicate with LLM]. Beyond animating facial avatars, these systems allow users to communicate decoded speech intentions directly to LLM applications for real-time interactive tasks and external device control.
Silent biometrics and authentication
The unique physiological and behavioral signals inherent in silent speech make SSIs a promising innovation for user authentication systems. Compared to traditional methods that rely on audible speech, fingerprints, or facial recognition, capturing subtle movements and vibrations associated with speech production through SSIs provides enhanced security and private identity verification[117]. This is particularly beneficial in environments where privacy is critical, such as hospitals, workplaces, or public spaces. Researchers applied the system that uses an IMU placed near the ear to capture jaw movements during silent speech for authentication[278]. Unlike microphone-based systems, it offers secure and private identity verification in various environments. A similar approach, called SilentKey, employs a smartphone-based sonar system for detecting unique echo patterns generated when users silently articulate a passcode[279]. The system demonstrates that even when the same phrase is used, the reflected signals vary due to each person’s unique anatomy and articulation patterns, thereby enabling personalized authentication. Recent research reveals a distinct trend toward integrating these technologies into more compact form factors, such as earphones[277]. Such devices are capable of detecting deformations in the ear canal caused by facial movements, thereby enabling user identification [Figure 12A].
Hands-free human-machine interactions
SSIs provide several silent features that facilitate interactions between human users and machines, including cellphones, robots, computers, and virtual/augmented reality systems[5,64,115,280]. First, SSIs eliminate the need for physical buttons or screens, enabling users to issue hands-free, spoken commands without needing to stop or look away from their tasks. Second, since the signals come directly from human biopotentials or facial/neck motions, SSIs remain reliable even in a noisy environment where ambient noise hinders voice-based control. Most importantly, SSIs allow people with voice impairments to participate in collaborative settings, providing them with a robust alternative to spoken communication. As one example, the EMG-based system was demonstrated for real-time control of an AR character [Figure 12B, AR Character Control][5]. The user silently spoke different commands, which were captured by EMG sensors and decoded using ML algorithms. The decoded commands were then mapped to control the motion of a virtual character in an AR environment, enabling immersive, non-verbal human-machine interaction. In addition, SSIs based on magnetic skin for facial movement tracking have been used to control a smartphone assistant and a drone via silent speech commands [Figure 12B, Phone or Drone Control][115]. The SSI incorporates a single piece of soft magnetic skin placed behind the ear and a Bluetooth magnetometer. By tracking and interpreting TMJ movements, the system enables wireless, non-acoustic control of cellphones and drones.
Figure 12B demonstrates the integration of EMG-based SSIs into human-robot collaboration[64]. In this scenario, transparent EMG electrode arrays were attached to the facial skin of two human users, which allowed them to control one robotic arm using silent speech commands. This HMI is especially useful in noisy environments where voice recognition systems fail. The SSIs perform two both speaker identification and speech content identification tasks during the collaborative assembly and disassembly processes: (1) The SSIs first identify which user issues the commands based on each user’s specific characteristic of silent speech signals; and (2) the SSIs translate the silent signals from the identified user into real-time robot commands (e.g., screwdriver, keyboard) that are subsequently transmitted to the robot to execute the corresponding actions. Additional control is provided through an optical hand-tracking system that recognizes the users’ hand motions to facilitate the handover task between humans and robots. Demonstrated tasks include one person assembling or disassembling a computer and a collaborative setting where two users work alongside a single robot. This setup not only improves workflow efficiency in noisy manufacturing environments but also opens new opportunities for individuals with voice impairments to participate in collaborative manufacturing.
CONCLUSION AND OUTLOOK
In summary, SSIs are a rapidly growing technology that provides a natural and intuitive spoken communication interface without audible speech. By examining diverse bio-integrated systems, from skin-mounted and oral sensors to implanted neural devices, this review highlights the trade-offs among portability, invasiveness, signal fidelity, and robustness. Continued innovation in functional materials, sensing modalities, and signal processing is essential to developing long-term, accurate, and socially acceptable solutions for communication in both clinical and daily settings.
The development of future bio-integrated hardware for SSIs presents distinct challenges and opportunities that must be addressed separately for each system type, as each operates under different constraints and applications. Epidermal systems represent the most promising avenue for widespread adoption in daily settings due to their non-invasive nature. Two key challenges remain: long-term comfort and social acceptance. Among epidermal approaches, EMG systems, one of the most promising sensing modalities for SSIs, require high-density electrode arrays to ensure adequate data for recognition. However, integrating these arrays into a single, relatively large patch may introduce discomfort and skin irritation over extended periods due to the large skin area covered. Future work should focus on developing gas-permeable and biocompatible sensors[73,281] that allow the patch to conform to the skin while remaining breathable and unobtrusive during long-term wear. Furthermore, to improve social acceptance, the development of transparent and thin electrodes should be prioritized, particularly for facial movement sensing. Recent studies highlight this aesthetic barrier, indicating that users frequently reject highly visible facial wearables due to social stigma and discomfort[282]. Consequently, making devices truly invisible is just as critical as ensuring their functionality. Integrating sensors into daily wear[16] or utilizing transparent and compliant materials[5] is essential for widespread adoption and user comfort.
For IMUs, despite their high efficiency in capturing three-axis motions, further improvements are needed to enhance sensitivity to subtle facial or jaw movements. This may be achieved by minimizing the size of circuit boards or by transitioning to circuit boards employing soft substrates[89] that conform better to the skin surface. Placing sensors in socially acceptable and low-visibility regions is also crucial for improving user acceptance. Strain sensors, while useful for capturing skin deformations, face integration challenges. Increasing their channel density and integrating multiple sensors into a single patch without adding bulk represents a promising research direction.
Moving beyond skin surface-based approaches, intraoral systems offer closer access to articulation sources but introduce new constraints. The main barriers are hardware bulkiness and reliance on external data acquisition. Advancements in signal acquisition techniques are essential to eliminate cables and achieve a fully wireless configuration[152]. If realized, these systems could serve as practical alternatives to epidermal systems. EPG currently cannot detect tongue movements without direct contact, whereas EOS systems comprising optical distance sensors can detect such changes. However, both require further simplification and miniaturization. A key direction is developing bimodal soft sensors that can detect both contact and proximity in a compact form and wirelessly. Among wireless approaches, future efforts on PMA systems should focus on designing specialized permanent magnets that can safely interface with the tongue without causing discomfort or posing health risks due to long-term exposure or accidental detachment. In contrast, EMA remains suitable primarily for laboratory and clinical research due to its complexity and bulky hardware setup.
For surgically embedded systems, long-term stability is limited by the mechanical mismatch between rigid electrodes and soft neural tissues. Systems such as ECoG and MEA often trigger chronic inflammation and gliosis due to micromotion at the electrode-tissue interface[283,284]. This foreign-body response gradually encapsulates the implant in a dense glial scar, which acts as an insulator and drastically increases electrical impedance. Consequently, neural signals degrade over months or years[285]. The combination of this ongoing foreign-body response and the lack of fully implantable wireless systems severely limits long-term signal stability and broader clinical deployment[16]. Addressing this biocompatibility issue, future designs should adopt ultra-flexible and biocompatible materials that can adapt to brain movements while maintaining recording fidelity[283]. Beyond material improvements, another key direction is reducing surgical invasiveness. Approaches such as the Stentrode, which enables access to neural signals via the vasculature without opening the skull, offer a less invasive alternative[286,287]. However, a thorough investigation is needed to make these approaches better suited for SSIs, including improving signal resolution, safety, and compatibility with portable data acquisition systems. While SEEG provides an invasive alternative, it faces limitations for continuous speech decoding. This technique inherently suffers from sparse sampling and limited coverage of key speech-related cortical areas[200,204]. Because highly informative speech signals primarily reside on the cortex, this sparse coverage hinders accurate speech reconstruction and requires future solutions.
In the realm of modeling and algorithm development for SSR, several key challenges must be addressed to enable reliable deployment. A major barrier to widespread deployment is the high inter-subject variability in physiological signals caused by differences in articulation habits, anatomy, and sensor placement. Historically, SSR models have relied on relatively small datasets, often involving fewer than 10 participants or even just one participant[44], which limits cross-user scalability. While recent multi-modal benchmarks have successfully scaled up to 100 subjects[288], cross-subject generalizability remains a pressing issue. Models trained in a user-specific paradigm frequently suffer from substantial drops in recognition accuracy when evaluated on unseen users, as physiological variations severely disrupt feature distributions[288]. Addressing this bottleneck requires frameworks that can operate effectively in data-scarce environments. As detailed in Section 4.3.3, researchers are increasingly adopting transfer learning and domain adaptation techniques to dynamically recalibrate models for new users without the need for extensive re-training data[289]. Another primary challenge is the limited availability of large-scale, high-quality datasets. Most current models rely on user-specific training, which reduces the model generalizability across users and limits scalability. Addressing this issue requires developing learning frameworks that can operate effectively in data-scarce environments. Transfer learning and self-supervised learning offer promising solutions, but their full potential has not yet been fully realized in SSR. Model robustness is another pressing issue. Variations in sensor location, signal quality, and user physiology can lead to performance degradation. Algorithms must be more tolerant of these variations via better calibration methods and adaptive modeling. Incorporating domain adaptation techniques to adjust models in real time without extensive re-training would be a valuable direction.
Real-time processing remains a technical bottleneck, especially for wearable devices. Deep models typically require substantial computational resources, which are incompatible with the low-power requirements of portable wearable devices. Future work should prioritize the development of lightweight models with low latency and minimal memory consumption. Multimodal fusion introduces additional complexity. Fusion of signals from EMG, IMU, or magnetic sensors can improve recognition accuracy but requires careful time synchronization and calibration. Inconsistent sampling rates and signal drift between modalities remain unresolved. Robust multimodal fusion algorithms that maintain performance in the presence of asynchronous or partially missing data are essential for reliable system integration.
Finally, current systems often lack model interpretability. Understanding how physiological signals map to semantic content is essential for clinical and assistive applications. Future algorithms should aim to improve transparency while maintaining accuracy, enabling users and clinicians to better trust the system and adapt it to their individual needs. By addressing these challenges, future SSR models can become more adaptable, efficient, and user-friendly, facilitating the development of silent speech technology toward widespread real-world adoption.
DECLARATIONS
Authors’ contributions
Conceptualization: Dong, P.; Yao, S.; Djurić, P. M.
Writing - original draft: Dong, P.; Song, Y.; Li, Y.
Writing - review and editing: Yao, S.; Djurić, P. M.
Supervision: Yao, S.; Djurić P. M.
Availability of data and materials
Not applicable.
AI and AI-assisted tools statement
During the preparation of this manuscript, the AI tool Gemini (version 3.1, released 2026-02-19) was used solely for language editing. The tool did not influence the study design, data collection, analysis, interpretation, or the scientific content of the work. All authors take full responsibility for the accuracy, integrity, and final content of the manuscript.
Financial support and sponsorship
This material is based upon work supported by the National Science Foundation under Award (No. ECCS-2335863).
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Yang, Q.; Jin, W.; Zhang, Q.; et al. Mixed-modality speech recognition and interaction using a wearable artificial throat. Nat. Mach. Intell. 2023, 5, 169-80.
2. Brown, S.; Laird, A. R.; Pfordresher, P. Q.; Thelen, S. M.; Turkeltaub, P.; Liotti, M. The somatotopy of speech: phonation and articulation in the human motor cortex. Brain. Cogn. 2009, 70, 31-41.
3. Khanna, P.; Srivastava, T.; Pan, S.; Jain, S.; Nguyen, P. JawSense: recognizing unvoiced sound using a low-cost ear-worn system. In Proceedings of the Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications, Virtual, February 24-26, 2021; ACM: New York, NY, USA, 2021; pp 44-9.
4. Gonzalez-Lopez, J. A.; Gomez-Alanis, A.; Martín-Doñas, J. M.; Pérez-Córdoba, J. L.; Gomez, A. M. Silent speech interfaces for speech restoration: a review. IEEE. Access. 2020, 8, 177995-8021.
5. Dong, P.; Song, Y.; Yu, S.; et al. Electromyogram-based lip-reading via unobtrusive dry electrodes and machine learning methods. Small 2023, 19, 2205058.
6. Betts, B. J.; Binsted, K.; Jorgensen, C. Small-vocabulary speech recognition using surface electromyography. Interact. Comput. 2006, 18, 1242-59.
7. Beukelman, D. R.; Mirenda, P. Augmentative and alternative communication; P.H. Brookes Pub., 1998. https://books.google.com/books/about/Augmentative_and_Alternative_Communicati.html?id=LPraAAAAMAAJ (accessed 2026-06-16).
8. Cheok, M. J.; Omar, Z.; Jaward, M. H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cyber. 2017, 10, 131-53.
9. Bulling, A.; Ward, J. A.; Gellersen, H.; Tröster, G. Eye movement analysis for activity recognition using electrooculography. IEEE. Trans. Pattern. Anal. Mach. Intell. 2011, 33, 741-53.
10. Lee, W.; Seong, J. J.; Ozlu, B.; Shim, B. S.; Marakhimov, A.; Lee, S. Biosignal sensors and deep learning-based speech recognition: a review. Sensors 2021, 21, 1399.
11. Lu, Y.; Tian, H.; Cheng, J.; et al. Decoding lip language using triboelectric sensors with deep learning. Nat. Commun. 2022, 13, 1401.
12. Meltzner, G. S.; Heaton, J. T.; Deng, Y.; De Luca, G.; Roy, S. H.; Kline, J. C. Development of sEMG sensors and algorithms for silent speech recognition. J. Neural. Eng. 2018, 15, 046031.
13. Zhang, Q.; Wang, D.; Zhao, R.; Yu, Y. SoundLip: enabling word and sentence-level lip interaction for smart devices. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2021, 5, 1-28.
14. Gohel, V.; Mehendale, N. Review on electromyography signal acquisition and processing. Biophys. Rev. 2020, 12, 1361-7.
15. Schultz, T.; Wand, M.; Hueber, T.; Krusienski, D. J.; Herff, C.; Brumberg, J. S. Biosignal-based spoken communication: a survey. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2017, 25, 2257-71.
16. Tang, C.; Qi, L.; Gao, S.; et al. Sensing technologies for silent speech interfaces. Nat. Sens. 2026, 1, 16-26.
17. Boufidis, D.; Garg, R.; Angelopoulos, E.; Cullen, D. K.; Vitale, F. Bio-inspired electronics: soft, biohybrid, and “living” neural interfaces. Nat. Commun. 2025, 16, 1861.
18. Lin, K.; Hong, W.; Huang, C.; et al. Stretchable high-density surface electromyography electrode patch assisted with machine learning for silent speech recognition. Eur. Phys. J. Spec. Top. 2025, 234, 7541-9.
19. Sahni, H.; Bedri, A.; Reyes, G.; et al. The tongue and ear interface: a wearable system for silent speech recognition. In Proceedings of the 2014 ACM International Symposium on Wearable Computers, Seattle, USA, September 13-17, 2014; ACM: New York, NY, USA, 2014; pp 47-54.
20. Wang, K.; Li, Z.; Cai, Z.; et al. The applications of flexible electronics in dental, oral, and craniofacial medicine. npj. Flex. Electron. 2024, 8, 33.
21. Silva, A. B.; Littlejohn, K. T.; Liu, J. R.; Moses, D. A.; Chang, E. F. The speech neuroprosthesis. Nat. Rev. Neurosci. 2024, 25, 473-92.
22. Tankisi, H.; Burke, D.; Cui, L.; et al. Standards of instrumentation of EMG. Clin. Neurophysiol. 2020, 131, 243-58.
23. Daniel, Ţ. D.; Neagu, M. Cancelling harmonic power line interference in biopotentials. In Compendium of New Techniques in Harmonic Analysis; IntechOpen, 2018; pp 19-37.
24. Zhang, Q.; Lan, Y.; Guo, K.; Wang, D. Lipwatch: enabling silent speech recognition on smartwatches using acoustic sensing. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2024, 8, 1-29.
25. Kaifosh, P.; Reardon, T. R.; CTRL-labs at Reality Labs. A generic non-invasive neuromotor interface for human-computer interaction. Nature 2025, 645, 702-11.
26. Liu, L.; Ji, Y.; Wang, H.; Denby, B. Comparison of DCT and autoencoder-based features for DNN-HMM multimodal silent speech recognition. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, October 17-20, 2016; IEEE, 2016.
27. Rabiner, L. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE. 1989, 77, 257-86.
28. Baum, L. E.; Petrie, T.; Soules, G.; Weiss, N. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. Ann. Math. Statist. 1970, 41, 164-71.
29. Song, R.; Zhang, X.; Chen, X.; et al. Decoding silent speech from high-density surface electromyographic data using transformer. Biomed. Signal. Process. Control. 2023, 80, 104298.
30. Gaddy, D.; Klein, D. An improved model for voicing silent speech. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual, August 1-6, 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp 175-81.
31. Freitas, J.; Teixeira, A.; Sales Dias, M.; Silva, S. An introduction to silent speech interfaces; Springer Cham, 2017.
32. CNX Anatomy. Side views of the muscles of facial expressions. https://commons.wikimedia.org/wiki/File:1106_Side_Views_of_the_Muscles_of_Facial_Expressions.jpg (accessed 2026-06-16).
33. Wikipedia. Silent Speech Interface. https://en.wikipedia.org/wiki/Silent_speech_interface (accessed 2026-06-16).
34. Moses, D. A.; Metzger, S. L.; Liu, J. R.; et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. N. Engl. J. Med. 2021, 385, 217-27.
35. Metzger, S. L.; Liu, J. R.; Moses, D. A.; et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 2022, 13, 6510.
36. Simonyan, K.; Horwitz, B. Laryngeal motor cortex and control of speech in humans. Neuroscientist 2011, 17, 197-208.
37. Metzger, S. L.; Littlejohn, K. T.; Silva, A. B.; et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature 2023, 620, 1037-46.
38. Willett, F. R.; Kunz, E. M.; Fan, C.; et al. A high-performance speech neuroprosthesis. Nature 2023, 620, 1031-6.
39. Chen, X.; Wang, R.; Khalilian-gourtani, A.; et al. A neural speech decoding framework leveraging deep learning and speech synthesis. Nat. Mach. Intell. 2024, 6, 467-80.
40. Macdonald, D. B.; Skinner, S.; Shils, J. Yingling, C; American Society of Neurophysiological Monitoring. Intraoperative motor evoked potential monitoring - a position statement by the American Society of Neurophysiological Monitoring. Clin. Neurophysiol. 2013, 124, 2291-316.
42. Zhang, Y.; Cai, H.; Wu, J.; et al. EMG-based cross-subject silent speech recognition using conditional domain adversarial network. IEEE. Trans. Cogn. Dev. Syst. 2023, 15, 2282-90.
43. Janke, M.; Diener, L. EMG-to-speech: direct generation of speech from facial electromyographic signals. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2017, 25, 2375-85.
44. Gaddy, D.; Klein, D. Digital voicing of silent speech. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, November 16-20, 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp 5521-30.
45. Cleveland Clinic. Temporomandibular joint (TMJ) disorders. https://my.clevelandclinic.org/health/diseases/15066-temporomandibular-disorders-tmd-overview (accessed 2026-06-16).
46. Srivastava, T.; Khanna, P.; Pan, S.; Nguyen, P.; Jain, S. MuteIt: Jaw motion based unvoiced command recognition using earable. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2022, 6, 1-26.
47. Rekimoto, J.; Nishimura, Y. Derma: silent speech interaction using transcutaneous motion sensing. In Proceedings of the Augmented Humans Conference 2021, Rovaniemi, Finland, February 22-24, 2021; ACM: New York, NY, USA, 2021; pp 91-100.
48. Bedri, A.; Sahni, H.; Thukral, P.; et al. Toward silent-speech control of consumer wearables. Computer 2015, 48, 54-62.
49. Huo, X.; Park, H.; Kim, J.; Ghovanloo, M. A dual-mode human computer interface combining speech and tongue motion for people with severe disabilities. IEEE. Trans. Neural. Syst. Rehabil. Eng. 2013, 21, 979-91.
50. Hofe, R.; Ell, S. R.; Fagan, M. J.; et al. Small-vocabulary speech recognition using a silent speech interface based on magnetic sensing. Speech. Commun. 2013, 55, 22-32.
51. Heracleous, P.; Badin, P.; Bailly, G.; Hagita, N. A pilot study on augmented speech communication based on Electro-Magnetic Articulography. Pattern. Recogn. Lett. 2011, 32, 1119-25.
52. Kimura, N.; Gemicioglu, T.; Womack, J.; et al. SilentSpeller: Towards mobile, hands-free, silent speech text entry using electropalatography. In CHI '22: CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, April 29-May 5, 2022; ACM: New York, NY, USA, 2022; pp 1-19.
53. Wei, Y.; Qiao, Y.; Jiang, G.; et al. A wearable skinlike ultra-sensitive artificial graphene throat. ACS. Nano. 2019, 13, 8639-47.
54. Che, Z.; Wan, X.; Xu, J.; Duan, C.; Zheng, T.; Chen, J. Speaking without vocal folds using a machine-learning-assisted wearable sensing-actuation system. Nat. Commun. 2024, 15, 1873.
55. Sugden, E.; Cleland, J. Using ultrasound tongue imaging to support the phonetic transcription of childhood speech sound disorders. Clin. Linguist. Phon. 2021, 36, 1047-66.
56. Liu, Y.; Zhao, Z.; Xu, M.; et al. Decoding and synthesizing tonal language speech from brain activity. Sci. Adv. 2023, 9, eadh0478.
57. Mallat, S. G. A theory for multiresolution signal decomposition: the wavelet representation. IEEE. Trans. Pattern. Anal. Machine. Intell. 1989, 11, 674-93.
58. Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE. Trans. Signal. Process. 1997, 45, 2673-81.
59. Vaswani, A.; Shazeer, N.; Parmar, N.; et al. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, December 4-9, 2017; ACM: New York, NY, USA, 2017; pp 6000-10.
60. Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE. 1998, 86, 2278-324.
61. Van Den Oord, A.; Dieleman, S.; Zen, H.; et al. WaveNet: a generative model for raw audio. arXiv 2016, arXiv:1609.03499. Available online: https://doi.org/10.48550/arXiv.1609.03499 (accessed 16 June 2026).
62. Kong, J.; Kim, J.; Bae, J. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, December 6-12, 2020; ACM: New York, NY, USA, 2020; pp 17022-33.
63. Wang, Y.; Tang, T.; Xu, Y.; et al. All-weather, natural silent speech recognition via machine-learning-assisted tattoo-like electronics. npj. Flex. Electron. 2021, 5, 20.
64. Dong, P.; Tian, S.; Chen, S.; et al. Decoding silent speech cues from muscular biopotential signals for efficient human-robot collaborations. Adv. Mater. Technol. 2024, 10, 2400990.
65. Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.; Brumberg, J. Silent speech interfaces. Speech. Commun. 2010, 52, 270-87.
66. Beck, T. W.; Housh, T. J.; Cramer, J. T.; et al. A comparison of monopolar and bipolar recording techniques for examining the patterns of responses for electromyographic amplitude and mean power frequency versus isometric torque for the vastus lateralis muscle. J. Neurosci. Methods. 2007, 166, 159-67.
67. Stepp, C. E. Surface electromyography for speech and swallowing systems: measurement, analysis, and interpretation. J. Speech. Lang. Hear. Res. 2012, 55, 1232-46.
68. De Luca, C. J. The use of surface electromyography in biomechanics. J. Appl. Biomech. 1997, 13, 135-63.
69. Meltzner, G. S.; Heaton, J. T.; Deng, Y.; De Luca, G.; Roy, S. H.; Kline, J. C. Silent speech recognition as an alternative communication device for persons with laryngectomy. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2017, 25, 2386-98.
70. Bio-medical. Silver-Silver Chloride EEG/ECG/EMG Electrodes - 6 pack. https://bio-medical.com/silver-silver-chloride-eeg-ecg-emg-electrodes-6-pack.html?gclid=Cj0KCQjw6auyBhDzARIsALIo6v9vEmZic2JdDesJlj94CqziGqhBReVs9kl72TBiusniSyRpyEyv4rEaAj_0EALw_wcB (accessed 2024-05).
71. Bio-medical. Kendall Disposable Surface EMG/ECG/EKG Electrodes 1” (24mm) 50pkg. https://bio-medical.com/covidien-kendall-disposable-surface-emg-ecg-ekg-electrodes-1-24mm-50pkg.html?gclid=Cj0KCQjw6auyBhDzARIsALIo6v82RA28LQxjTsIdC_r32s-l0PQ3o5S9e2t8EyiGe1uXXtacuTcOuKwaApOCEALw_wcB (accessed 2024-05).
72. Yao, S.; Zhu, Y. Nanomaterial-enabled dry electrodes for electrophysiological sensing: a review. JOM 2016, 68, 1145-55.
73. Zhou, W.; Yao, S.; Wang, H.; Du, Q.; Ma, Y.; Zhu, Y. Gas-permeable, ultrathin, stretchable epidermal electronics with porous electrodes. ACS. Nano. 2020, 14, 5798-805.
74. Yao, S.; Yang, J.; Poblete, F. R.; Hu, X.; Zhu, Y. Multifunctional electronic textiles using silver nanowire composites. ACS. Appl. Mater. Interfaces. 2019, 11, 31028-37.
75. Qin, Q.; Li, J.; Yao, S.; Liu, C.; Huang, H.; Zhu, Y. Electrocardiogram of a silver nanowire based dry electrode: quantitative comparison with the standard Ag/AgCl gel electrode. IEEE. Access. 2019, 7, 20789-800.
76. Prasad, S.; Farella, M.; Paulin, M.; Yao, S.; Zhu, Y.; Van Vuuren, L. J. Effect of electrode characteristics on electromyographic activity of the masseter muscle. J. Electromyogr. Kinesiol. 2021, 56, 102492.
77. Ariati, R.; Sales, F.; Souza, A.; Lima, R. A.; Ribeiro, J. Polydimethylsiloxane composites characterization and its applications: a review. Polymers 2021, 13, 4258.
78. Luo, Y.; Abidian, M. R.; Ahn, J.; et al. Technology roadmap for flexible sensors. ACS. Nano. 2023, 17, 5211-95.
79. Wang, S.; Li, M.; Wu, J.; et al. Mechanics of epidermal electronics. J. Appl. Mech. 2012, 79, 031022.
80. Dong, P.; Ives, J.; Garcia, E.; et al. Unobtrusive swallow monitoring enabled by conformal IONOGEL biopotential electrodes and machine learning. Adv. Mater. Technol. 2025, 10, e00229.
81. Wang, J.; Fan, J.; Wan, T.; Hu, L.; Li, Z.; Chu, D. Recent progress in silver nanowire-based transparent conductive electrodes. Adv. Energy. Sustain. Res. 2025, 6, 2500033.
82. Wang, J.; Zhang, S.; Li, L.; et al. Glassy ionogels with high compressibility and strength for impact protection. Proc. Natl. Acad. Sci. U.S.A. 2025, 122, e2417978122.
83. Tang, C.; Mallah, J.; Kazieczko, D.; et al. Wireless silent speech interface using multichannel textile EMG sensors integrated into headphones. IEEE. Trans. Instrum. Meas. 2025, 74, 1-10.
84. ADInstrument. EMG. https://www.adinstruments.com/signal/emg-electromyography (accessed 2026-06-16).
85. OpenBCI. Cyton getting started guide. https://docs.openbci.com/GettingStarted/Boards/CytonGS/ (accessed 2026-06-16).
86. Delsys. Trigno Quattro sensor. https://delsys.com/trigno-quattro/#design (accessed 2026-06-16).
88. Wikipedia. Nyquist-Shannon sampling theorem. https://en.wikipedia.org/wiki/Nyquist%E2%80%93Shannon_sampling_theorem (accessed 2026-06-16).
89. Woodman, S. J.; Shah, D. S.; Landesberg, M.; Agrawala, A.; Kramer-bottiglio, R. Stretchable Arduinos embedded in soft robots. Sci. Robot. 2024, 9, eadn6844.
90. Chung, H. U.; Kim, B. H.; Lee, J. Y.; et al. Binodal, wireless epidermal electronic systems with in-sensor analytics for neonatal intensive care. Science 2019, 363, eaau0780.
91. Kalogeropoulos, C.; Theofilatos, K.; Mavroudi, S. From neurons to networks: a holistic review of electroencephalography (EEG) from neurophysiological foundations to AI techniques. Signals 2026, 7, 17.
93. Min, B.; Kim, J.; Park, H.; Lee, B. Vowel imagery decoding toward silent speech BCI using extreme learning machine with electroencephalogram. Biomed. Res. Int. 2016, 2016, 1-11.
94. Inoue, M.; Hatakeyama, E.; Kita, Y.; Sasai, S. Large-scale training data enhances silent speech decoding with around-ear EEG. J. Neural. Eng. 2026, 23, 026027.
95. American Clinical Neurophysiology Society. Guideline 5: Guidelines for standard electrode position nomenclature. J. Clin. Neurophysiol. 2006, 23, 107-10.
96. Jackson, A. F.; Bolger, D. J. The neurophysiological bases of EEG and EEG measurement: a review for the rest of us. Psychophysiology 2014, 51, 1061-71.
98. Jain, A.; Raja, R.; Srivastava, S.; Sharma, P. C.; Gangrade, J.; R, M. Analysis of EEG signals and data acquisition methods: a review. Comput. Methods. Biomech. Biomed. Eng. Imaging. Vis. 2024, 12, 2304574.
99. Malmivuo, J.; Plonsey, R. Electroencephalography. In Principles and Applications of Bioelectric and Biomagnetic Fields; Oxford University Press, 1995; pp 257-64.
100. Etard, O.; Reichenbach, T. Neural speech tracking in the theta and in the delta frequency band differentially encode clarity and comprehension of speech in noise. J. Neurosci. 2019, 39, 5750-9.
101. Synigal, S. R.; Teoh, E. S.; Lalor, E. C. Including measures of high gamma power can improve the decoding of natural speech from EEG. Front. Hum. Neurosci. 2020, 14, 130.
102. Bröhl, F.; Kayser, C. Delta/theta band EEG differentially tracks low and high frequency speech-derived envelopes. Neuroimage 2021, 233, 117958.
103. Zhou, J.; Cao, Z.; Duan, Y.; et al. Pretraining large brain language model for active BCI: silent speech. In Proceedings of the 33rd ACM International Conference on Multimedia, Dublin, Ireland, October 27-31, 2025; ACM: New York, NY, USA, 2025, pp 5883-92.
104. Panachakel, J. T.; Ramakrishnan, A. G. Decoding covert speech from EEG - a comprehensive review. Front. Neurosci. 2021, 15, 642251.
105. Brownlee, A.; Bruening, L. Living with ALS: changes in speech and communication solutions. https://www.als.org/sites/default/files/2022-10/Resource-Guide-9.pdf (accessed 2022-06).
106. Brigham, K.; Kumar, B. V. K. V. Imagined speech classification with eeg signals for silent communication: a preliminary investigation into synthetic telepathy. In Proceedings of the 2010 4th International Conference on Bioinformatics and Biomedical Engineering, Chengdu, China, June 18-20, 2010; IEEE, 2010, pp 1-4.
107. Suppes, P.; Lu, Z.; Han, B. Brain wave recognition of words. Proc. Natl. Acad. Sci. U.S.A. 1997, 94, 14965-9.
108. Tseghai, G. B.; Malengier, B.; Fante, K. A.; Van Langenhove, L. Hook fabric electroencephalography electrode for brain activity measurement without shaving the head. Polymers 2023, 15, 3673.
109. Tian, Q.; Zhao, H.; Wang, X.; et al. Hairy-skin-adaptive viscoelastic dry electrodes for long-term electrophysiological monitoring. Adv. Mater. 2023, 35, 2211236.
110. Wang, C.; Wang, H.; Wang, B.; et al. On-skin paintable biogel for long-term high-fidelity electroencephalogram recording. Sci. Adv. 2022, 8, eabo1396.
111. Scalco De Vasconcelos, L.; Yan, Y.; Maharjan, P.; et al. On-scalp printing of personalized electroencephalography e-tattoos. Cell. Biomater. 2025, 1, 100004.
112. Mahmood, M.; Mzurikwao, D.; Kim, Y.; et al. Fully portable and wireless universal brain-machine interfaces enabled by flexible scalp electronics and deep learning algorithm. Nat. Mach. Intell. 2019, 1, 412-22.
113. Shin, J. H.; Kwon, J.; Kim, J. U.; et al. Wearable EEG electronics for a Brain-AI Closed-Loop System to enhance autonomous machine decision-making. npj. Flex. Electron. 2022, 6, 32.
114. Liu, S.; Fawden, T.; Zhu, R.; Malliaras, G. G.; Bance, M. A data-efficient and easy-to-use lip language interface based on wearable motion capture and speech movement reconstruction. Sci. Adv. 2024, 10, eado9576.
115. Dong, P.; Li, Y.; Chen, S.; Grafstein, J. T.; Khan, I.; Yao, S. Decoding silent speech commands from articulatory movements through soft magnetic skin and machine learning. Mater. Horiz. 2023, 10, 5607-20.
116. MBIENTLAB. METAMOTIONS. https://mbientlab.com/metamotions/ (accessed 2026-06-16).
117. Srivastava, T.; Pan, S.; Nguyen, P.; Jain, S. Jawthenticate: microphone-free speech-based authentication using jaw motion and facial vibrations. In Proceedings of the 21st ACM Conference on Embedded Networked Sensor Systems, Istanbul, Turkiye, November 12-17, 2023; ACM: New York, NY, USA, 2023; pp 209-22.
118. Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, June 25-29, 2006; ACM: New York, NY, USA, 2006; pp 369-76.
119. Wang, Y.; Lee, S.; Yokota, T.; et al. A durable nanomesh on-skin strain gauge for natural skin motion monitoring with minimum mechanical constraints. Sci. Adv. 2020, 6, eabb7043.
120. Kim, T.; Shin, Y.; Kang, K.; et al. Ultrathin crystalline-silicon-based strain gauges with deep learning algorithms for silent speech interfaces. Nat. Commun. 2022, 13, 5815.
121. Yoo, H.; Kim, E.; Chung, J. W.; et al. Silent speech recognition with strain sensors and deep learning analysis of directional facial muscle movement. ACS. Appl. Mater. Interfaces. 2022, 14, 54157-69.
122. Sun, T.; Tasnim, F.; Mcintosh, R. T.; et al. Decoding of facial strains via conformable piezoelectric interfaces. Nat. Biomed. Eng. 2020, 4, 954-72.
123. Yao, S.; Zhu, Y. Wearable multifunctional sensors using printed stretchable conductors made of silver nanowires. Nanoscale 2014, 6, 2345.
124. Yao, S.; Swetha, P.; Zhu, Y. Nanomaterial-enabled wearable sensors for healthcare. Adv. Healthc. Mater. 2017, 7, 1700889.
125. Yao, S.; Vargas, L.; Hu, X.; Zhu, Y. A novel finger kinematic tracking method based on skin-like wearable strain sensors. IEEE. Sensors. J. 2018, 18, 3010-5.
126. Li, Y.; Liu, Y.; Bhuiyan, S. R. A.; Zhu, Y.; Yao, S. Printed strain sensors for on-skin electronics. Small. Struct. 2021, 3, 2100131.
127. Yao, S.; Lee, J. S.; James, K. E.; et al. Silver nanowire strain sensors for wearable body motion tracking. In Proceedings of the 2015 IEEE Sensors, Busan, South Korea, November 1-4, 2015; IEEE, 2015.
128. Xu, S.; Yu, J. X.; Guo, H.; et al. Force-induced ion generation in zwitterionic hydrogels for a sensitive silent-speech sensor. Nat. Commun. 2023, 14, 219.
129. Jin, Y.; Wen, B.; Gu, Z.; et al. Deep-learning-enabled MXene-based artificial throat: toward sound detection and speech recognition. Adv. Mater. Technol. 2020, 5, 2000262.
130. Gong, S.; Zhang, X.; Nguyen, X. A.; et al. Hierarchically resistive skins as specific and multimetric on-throat wearable biosensors. Nat. Nanotechnol. 2023, 18, 889-97.
131. Liu, T.; Zhang, M.; Li, Z.; et al. Machine learning-assisted wearable sensing systems for speech recognition and interaction. Nat. Commun. 2025, 16, 2363.
132. Benster, T.; Wilson, G.; Elisha, R.; Willett, F. R.; Druckmann, S. A cross-modal approach to silent speech with LLM-enhanced recognition. arXiv 2024, arXiv:2403.05583. Available online: https://arxiv.org/abs/2403.05583 (accessed 16 June 2026).
133. Nguyen, C. H.; Karavas, G. K.; Artemiadis, P. Inferring imagined speech using EEG signals: a new approach using Riemannian manifold features. J. Neural. Eng. 2017, 15, 016002.
134. Lee, Y.; Lee, S.; Kim, S.; Lee, S. Towards voice reconstruction from EEG during imagined speech. AAAI 2023, 37, 6030-8.
135. Kamble, A.; Ghare, P. H.; Kumar, V.; Kothari, A.; Keskar, A. G. Spectral analysis of EEG signals for automatic imagined speech recognition. IEEE. Trans. Instrum. Meas. 2023, 72, 1-9.
136. Kunimi, Y.; Ogata, M.; Hiraki, H.; Itagaki, M.; Kanazawa, S.; Mochimaru, M. E-MASK: a mask-shaped interface for silent speech interaction with flexible strain sensors. In Proceedings of Augmented Humans 2022, Kashiwa, Japan, March 13-15, 2022; ACM: New York, NY, USA, 2022; pp 26-34.
137. Tang, C.; Xu, M.; Yi, W.; et al. Ultrasensitive textile strain sensors redefine wearable silent speech interfaces with high machine learning efficiency. npj. Flex. Electron. 2024, 8, 27.
138. Yin, J.; Wang, S.; Tat, T.; Chen, J. Motion artefact management for soft bioelectronics. Nat. Rev. Bioeng. 2024, 2, 541-58.
139. Tian, G.; Yang, D.; Liang, C.; et al. A nonswelling hydrogel with regenerable high wet tissue adhesion for bioelectronics. Adv. Mater. 2023, 35, 2212302.
140. Yang, Q.; Hu, Z.; Rogers, J. A. Functional hydrogel interface materials for advanced bioelectronic devices. Acc. Mater. Res. 2021, 2, 1010-23.
141. Kim, J.; Oh, J.; Park, Y.; Kim, J. J.; Jeong, U. Soft conductive interfacing for bioelectrical uses: adhesion mechanisms and structural approaches. Macromolecules 2023, 56, 4431-46.
142. Park, B.; Shin, J. H.; Ok, J.; et al. Cuticular pad-inspired selective frequency damper for nearly dynamic noise-free bioelectronics. Science 2022, 376, 624-9.
143. Jeong, H. Lee, J.Y.; Lee, K.; et al. Differential cardiopulmonary monitoring system for artifact-canceled physiological tracking of athletes, workers, and COVID-19 patients. Sci. Adv. 2021, 7, eabg3092.
144. Wang, Y.; Yin, L.; Bai, Y.; et al. Electrically compensated, tattoo-like electrodes for epidermal electrophysiology at scale. Sci. Adv. 2020, 6, eabd0996.
145. Lin, C. F.; Zhu, J. D. Hilbert-Huang transformation-based time-frequency analysis methods in biomedical signal applications. Proc. Inst. Mech. Eng. Part. H. J. Eng. Med. 2012, 226, 208-16.
146. Challis, R. E.; Kitney, R. I. Biomedical signal processing (in four parts) Part 2 The frequency transforms and their inter-relationships. Med. Biol. Eng. Comput. 1991, 29, 1-17.
147. Xiong, D.; Zhang, D.; Zhao, X.; Zhao, Y. Deep learning for EMG-based human-machine interaction: a review. IEEE. CAA. J. Autom. Sinica. 2021, 8, 512-33.
148. Ding, S.; Saha, T.; Yin, L.; et al. A fingertip-wearable microgrid system for autonomous energy management and metabolic monitoring. Nat. Electron. 2024, 7, 788-99.
149. Ding, S.; Bian, Y.; Saha, T.; et al. Artificial intelligence-enabled wearable microgrids for self-sustained energy management. Nat. Rev. Electr. Eng. 2025, 2, 683-93.
150. Woo, S. T.; Ha, J. W.; Na, S.; Choi, H.; Pyun, S. B. Design and evaluation of Korean electropalatography (K-EPG). Sensors 2021, 21, 3802.
151. Stone, S. A silent-speech interface using electro-optical stomatography; TUD press, 2021. https://www.gbv.de/dms/tib-ub-hannover/1777588154.pdf (accessed 2026-06-16).
152. Pastore, G. Tongue position tracking device (TPTD): a discreet wireless electropalatography and glossometry device. University of Illinois at Chicago, 2018. https://hdl.handle.net/10027/23029 (accessed 2026-06-16).
153. icSpeech. Portable electropalatography (EPG) system. https://icspeech.com/electropalatography.html (accessed 2026-06-16).
154. Kelly, S.; Main, A.; Manley, G.; Mclean, C. Electropalatography and the Linguagraph system. Med. Eng. Phys. 2000, 22, 47-58.
155. Mat Zin, S.; Md Rasib, S. Z.; Suhaimi, F. M.; Mariatti, M. The technology of tongue and hard palate contact detection: a review. Biomed. Eng. Online. 2021, 20, 17.
156. Cleveland Clinic. Dental impressions. https://my.clevelandclinic.org/health/diagnostics/22671-dental-impressions (accessed 2026-06-16).
157. Jain, A. R.; Venkat Prasad, M. K.; Ariga, P. Palatogram revisited. Contemp. Clin. Dent. 2014, 5, 138-41.
158. Cao, B.; Sebkhi, N.; Mau, T.; Inan, O. T.; Wang, J. Permanent magnetic articulograph (PMA) vs. electromagnetic articulograph (EMA) in articulation-to-speech synthesis for silent speech interface. In Proceedings of the Eighth Workshop on Speech and Language Processing for Assistive Technologies, Minneapolis, MN, USA, June 7, 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp 17-23.
159. Rebernik, T.; Jacobi, J.; Jonkers, R.; Noiray, A.; Wieling, M. A review of data collection practices using electromagnetic articulography. Lab. Phonol. 2021, 12, 6.
160. Marinelli, F.; Venegas, C.; Alarcón, J.; Navarro, P.; Fuentes, R. Chewing analysis by means of electromagnetic articulography: current developments and new possibilities. Sensors 2023, 23, 9511.
161. Gonzalez, J. A.; Cheah, L. A.; Gilbert, J. M.; et al. A silent speech system based on permanent magnet articulography and direct synthesis. Comput. Speech. Lang. 2016, 39, 67-87.
162. Gonzalez, J. A.; Cheah, L. A.; Gomez, A. M.; et al. Direct speech reconstruction from articulatory sensor data by machine learning. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2017, 25, 2362-74.
163. Kroos, C. Evaluation of the measurement precision in three-dimensional Electromagnetic Articulography (Carstens AG500). J. Phon. 2012, 40, 453-65.
164. Stella, M.; Bernardini, P.; Sigona, F.; Stella, A.; Grimaldi, M.; Gili Fivela, B. Numerical instabilities and three-dimensional electromagnetic articulography. J. Acoust. Soc. Am. 2012, 132, 3941-9.
165. Ferrat, K.; Guerti, M. An experimental study of the gemination in Arabic language. Arch. Acoust. 2017, 42, 571-8.
166. Carstens-Medizinelektronik-GmbH. Sensor Coil. https://www.articulograph.de/wp-content/uploads/2018/01/sensor_18.pdf (accessed 2026-06-16).
167. Yunusova, Y.; Green, J. R.; Mefferd, A. Accuracy assessment for AG500, Electromagnetic articulograph. J. Speech. Lang. Hear. Res. 2009, 52, 547-55.
168. Stella, M.; Stella, A.; Sigona, F.; Bernardini, P.; Grimaldi, M.; Fivela, B. G. Electromagnetic articulography with AG500 and AG501. In Proceedings of the Interspeech, Lyon, France, August 25-29, 2013; ISCA, 2013; pp 1316-20.
169. Chen, L.; Chen, P.; Tsai, R. T.; Tsao, Y. EPG2S: speech generation and speech enhancement based on electropalatography and audio signals using multimodal learning. IEEE. Signal. Process. Lett. 2022, 29, 2582-6.
170. Stone, S.; Birkholz, P. Cross-speaker silent-speech command word recognition using electro-optical stomatography. In Proceedings of ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, May 4-8, 2020; IEEE, 2020; pp 7849-53.
171. Sebkhi, N.; Santus, N.; Bhavsar, A.; Siahpoushan, S.; Inan, O. T. Evaluation of a wireless tongue tracking system on the identification of phoneme landmarks. IEEE. Trans. Biomed. Eng. 2021, 68, 1190-7.
172. Chen, Y.; Hung, K.; Chuang, S.; et al. EMA2S: an end-to-end multimodal articulatory-to-speech system. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, May 22-28, 2021; IEEE, 2021; pp 1-5.
173. Cao, B.; Ravi, S.; Sebkhi, N.; et al. MagTrack: a wearable tongue motion tracking system for silent speech interfaces. J. Speech. Lang. Hear. Res. 2023, 66, 3206-21.
174. Hou, B.; Yang, D.; Ren, X.; Yi, L.; Liu, X. A tactile oral pad based on carbon nanotubes for multimodal haptic interaction. Nat. Electron. 2024, 7, 777-87.
175. Tang, J.; Lebel, A.; Jain, S.; Huth, A. G. Semantic reconstruction of continuous language from non-invasive brain recordings. Nat. Neurosci. 2023, 26, 858-66.
176. Leuthardt, E. C.; Schalk, G.; Roland, J.; Rouse, A.; Moran, D. W. Evolution of brain-computer interfaces: going beyond classic motor physiology. Neurosurg. Focus. 2009, 27, E4.
177. Lago, N.; Cester, A. Flexible and organic neural interfaces: a review. Appl. Sci. 2017, 7, 1292.
178. Duraivel, S.; Rahimpour, S.; Chiang, C.; et al. High-resolution neural recordings improve the accuracy of speech decoding. Nat. Commun. 2023, 14, 6938.
179. Fattahi, P.; Yang, G.; Kim, G.; Abidian, M. R. A review of organic and inorganic biomaterials for neural interfaces. Adv. Mater. 2014, 26, 1846-85.
180. Blackrock Neurotech. Utah Array. https://blackrockneurotech.com/products/utah-array/ (accessed 2026-06-16).
181. Hu, M.; Li, M.; Li, W.; Liang, H. Joint analysis of spikes and local field potentials using copula. Neuroimage 2016, 133, 457-67.
182. Kluin, K. J.; Gilman, S.; Markel, D. S.; Koeppe, R. A.; Rosenthal, G.; Junck, L. Speech disorders in olivopontocerebellar atrophy correlate with positron emission tomography findings. Ann. Neurol. 2004, 23, 547-54.
183. Cleveland Clinic. Dysarthria. https://my.clevelandclinic.org/health/diseases/17653-dysarthria (accessed 2026-06-16).
184. Zhao, M.; Marino, M.; Samogin, J.; Swinnen, S. P.; Mantini, D. Hand, foot and lip representations in primary sensorimotor cortex: a high-density electroencephalography study. Sci. Rep. 2019, 9, 19464.
185. Littlejohn, K. T.; Cho, C. J.; Liu, J. R.; et al. A streaming brain-to-voice neuroprosthesis to restore naturalistic communication. Nat. Neurosci. 2025, 28, 902-12.
186. Angrick, M.; Luo, S.; Rabbani, Q.; et al. Online speech synthesis using a chronically implanted brain-computer interface in an individual with ALS. Sci. Rep. 2024, 14, 9617.
187. Glasser, M. F.; Coalson, T. S.; Robinson, E. C.; et al. A multi-modal parcellation of human cerebral cortex. Nature 2016, 536, 171-8.
188. Andrews, J. P.; Cahn, N.; Speidel, B. A.; et al. Dissociation of Broca’s area from Broca’s aphasia in patients undergoing neurosurgical resections. J. Neurosurg. 2023, 138, 847-57.
189. Liu, Y.; Xu, S.; Yang, Y.; et al. Nanomaterial-based microelectrode arrays for in vitro bidirectional brain-computer interfaces: a review. Microsyst. Nanoeng. 2023, 9, 13.
190. Wandelt, S. K.; Bjånes, D. A.; Pejsa, K.; Lee, B.; Liu, C.; Andersen, R. A. Representation of internal speech by single neurons in human supramarginal gyrus. Nat. Hum. Behav. 2024, 8, 1136-49.
191. Wairagkar, M.; Card, N. S.; Singer-clark, T.; et al. An instantaneous voice-synthesis neuroprosthesis. Nature 2025, 644, 145-52.
192. Card, N. S.; Wairagkar, M.; Iacobacci, C.; et al. An accurate and rapidly calibrating speech neuroprosthesis. N. Engl. J. Med. 2024, 391, 609-18.
193. Cleveland Clinic. Stereoelectroencephalography (SEEG). https://my.clevelandclinic.org/health/diagnostics/17457-seeg-test (accessed 2026-06-16).
194. Kimura, N.; Hayashi, K.; Rekimoto, J. TieLent. In Proceedings of the International Conference on Advanced Visual Interfaces, Salerno, Italy, September 28-October 2, 2020; ACM: New York, NY, USA, 2020, pp 1-8.
195. Jensen, M. A.; Fine, A.; Kerezoudis, P.; et al. Functional mapping of movement and speech using task-based electrophysiological changes in stereoelectroencephalography. J. Neurosurg. 2025, 142, 311-23.
196. Young, J. J.; Coulehan, K.; Fields, M. C.; et al. Language mapping using electrocorticography versus stereoelectroencephalography: a case series. Epilepsy. Behav. 2018, 84, 148-51.
197. Mullin, J. P.; Shriver, M.; Alomar, S.; et al. Is SEEG safe? A systematic review and meta-analysis of stereo-electroencephalography-related complications. Epilepsia 2016, 57, 386-401.
198. McGovern, R. A.; Ruggieri, P.; Bulacio, J.; Najm, I.; Bingaman, W. E.; Gonzalez-Martinez, J. A. Risk analysis of hemorrhage in stereo-electroencephalography procedures. Epilepsia 2019, 60, 571-80.
199. He, T.; Wei, M.; Wang, R.; et al. VocalMind: a stereotactic EEG dataset for vocalized, mimed, and imagined speech in tonal language. Sci. Data. 2025, 12, 657.
200. Ivucic, D.; Bayer, T.; Ivucic, G.; et al. Speech envelope reconstruction from stereo EEG in a speech production task. In 2025 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Copenhagen, Denmark, July 14-18, 2025; IEEE, 2025; pp 1-5.
201. Luo, S.; Angrick, M.; Coogan, C.; et al. Stable decoding from a speech BCI enables control for an individual with ALS without recalibration for 3 months. Adv. Sci. 2023, 10, 2304853.
202. Angrick, M.; Herff, C.; Mugler, E.; et al. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural. Eng. 2019, 16, 036019.
203. Wandelt, S. K.; Bjånes, D. A.; Pejsa, K.; Lee, B.; Liu, C.; Andersen, R. A. Online internal speech decoding from single neurons in a human participant. medRxiv 2022, 2022.11.02.22281775. Available online: https://www.medrxiv.org/content/10.1101/2022.11.02.22281775v1 (accessed 16 June 2026).
204. Wu, X.; Wellington, S.; Fu, Z.; Zhang, D. Speech decoding from stereo-electroencephalography (sEEG) signals using advanced deep learning methods. J. Neural. Eng. 2024, 21, 036055.
205. Petrosyan, A.; Voskoboinikov, A.; Sukhinin, D.; et al. Speech decoding from a small set of spatially segregated minimally invasive intracranial EEG electrodes with a compact and interpretable neural network. J. Neural. Eng. 2022, 19, 066016.
206. Wilson, G. H.; Stavisky, S. D.; Willett, F. R.; et al. Decoding spoken English from intracortical electrode arrays in dorsal precentral gyrus. J. Neural. Eng. 2020, 17, 066007.
207. Wang, C.; Cai, M.; Hao, Z.; et al. Stretchable, multifunctional epidermal sensor patch for surface electromyography and strain measurements. Adv. Intell. Syst. 2021, 3, 2100031.
208. Liu, H.; Dong, W.; Li, Y.; et al. An epidermal sEMG tattoo-like patch as a new human-machine interface for patients with loss of voice. Microsyst. Nanoeng. 2020, 6, 16.
209. Stone, S.; Birkholz, P. Silent-speech command word recognition using electro-optical stomatography. In Interspeech 2016, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, September 8-12, 2016; ISCA, 2016; pp 2350-1. https://www.isca-archive.org/interspeech_2016/stone16_interspeech.pdf (accessed 2026-06-16).
210. Bouten, C. V.; Koekkoek, K. T.; Verduin, M.; Kodde, R.; Janssen, J. D. A triaxial accelerometer and portable data processing unit for the assessment of daily physical activity. IEEE. Trans. Biomed. Eng. 1997, 44, 136-47.
211. Karantonis, D. M.; Narayanan, M. R.; Mathie, M.; Lovell, N. H.; Celler, B. G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE. Trans. Inf. Technol. Biomed. 2006, 10, 156-67.
212. Makin, J. G.; Moses, D. A.; Chang, E. F. Machine translation of cortical activity to text with an encoder-decoder framework. Nat. Neurosci. 2020, 23, 575-82.
213. Chen, X.; Zhang, X.; Chen, X.; Chen, X. Decoding silent speech based on high-density surface electromyogram using spatiotemporal neural network. IEEE. Trans. Neural. Syst. Rehabil. Eng. 2023, 31, 2069-78.
214. Ang, K. K.; Chin, Z. Y.; Zhang, H.; Guan, C. Filter Bank Common Spatial Pattern (FBCSP) in brain-computer interface. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, June 1-8, 2008; IEEE, 2008; pp 2390-7.
215. Delorme, A.; Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods. 2004, 134, 9-21.
216. Addison, P.; Walker, J.; Guido, R. Time--frequency analysis of biosignals. IEEE. Eng. Med. Biol. Mag. 2009, 28, 14-29.
217. Patro, S. G. K.; Sahu, K. K. Normalization: a preprocessing stage. arXiv 2015, arXiv:1503.06462. Available online: https://arxiv.org/abs/1503.06462 (accessed 16 June 2026).
218. Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, December 3-8, 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp 2488-98.
219. Kim, T.; Kim, J.; Tae, Y.; Park, C.; Choi, J. H.; Choo, J. Reversible instance normalization for accurate time-series forecasting against distribution shift. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, May 4-8, 2021; ICLR, 2021. https://openreview.net/pdf?id=cGDAkQo1C0p (accessed 2026-06-16).
220. Ba, J. L.; Kiros, J. R.; Hinton, G. E. Layer normalization. arXiv 2016, arXiv:1607.06450. Available online: https://arxiv.org/abs/1607.06450 (accessed 16 June 2026).
221. Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: the missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. Available online: https://arxiv.org/abs/1607.08022 (accessed 16 June 2026).
222. Freitas, J.; Teixeira, A. Dias, M.S. Multimodal silent speech interface based on video, depth, surface electromyography and ultrasonic doppler: data collection and first recognition results. In Proceedings of the Workshop on Speech Production in Automatic Speech Recognition (SPASR-2013), Lyon, France, August 30, 2013; ISCA, 2013; pp 44-9. https://www.isca-archive.org/spasr_2013/freitas13_spasr.html (accessed 2026-06-16).
223. Leonard, M. K.; Gwilliams, L.; Sellers, K. K.; et al. Large-scale single-neuron speech sound encoding across the depth of human cortex. Nature 2023, 626, 593-602.
224. Senin, P. Dynamic time warping algorithm review. Information and Computer Science Department, University of Hawaii at Manoa Honolulu. 2008. https://csdl.ics.hawaii.edu/techreports/2008/08-04/08-04.pdf (accessed 2026-06-16).
225. Li, W.; Yuan, J.; Zhang, L.; Cui, J.; Wang, X.; Li, H. sEMG-based technology for silent voice recognition. Comput. Biol. Med. 2023, 152, 106336.
226. Janke, M.; Wand, M.; Schultz, T. A spectral mapping method for EMG-based recognition of silent speech. In Proceedings of the International Workshop on Bio-inspired Human-Machine Interfaces and Healthcare Applications, Valencia, Spain, January 20-23, 2010; SciTePress - Science and and Technology Publications, 2010; pp 22-31.
227. Lu, Y.; Jiang, H.; Liu, W. Classification of EEG signal by STFT-CNN framework: identification of right-/left-hand motor imagination in BCI systems. In Proceedings of the The 7th International Conference on Computer Engineering and Networks, Shanghai, China, July 22-27, 2017; Sissa Medialab, 2017.
228. Burhan, N.; Kasno, M.; Ghazali, R. Feature extraction of surface electromyography (sEMG) and signal processing technique in wavelet transform: a review. In Proceedings of the 2016 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Selangor, Malaysia, October 22-22, 2016; IEEE, 2016, pp 141-6.
229. Abdul, Z. K.; Al-talabani, A. K. Mel frequency cepstral coefficient and its applications: a review. IEEE. Access. 2022, 10, 122136-58.
230. Yu, C.; Wang, X.; Qian, Z. Silent speech recognition using visual cascading fusion of tongue-lip movements based on pre-trained and fine-tuned model. J. Audio. Speech. Music. Proc. 2025, 2025, 16.
231. Chandrabanshi, V.; Domnic, S. Leveraging 3D-CNN and graph neural network with attention mechanism for visual speech recognition. SIViP. 2025, 19, 844.
232. Wu, J.; Zhang, Y.; Xie, L.; et al. A novel silent speech recognition approach based on parallel inception convolutional neural network and Mel frequency spectral coefficient. Front. Neurorobot. 2022, 16, 971446.
233. Park, D. S.; Chan, W.; Zhang, Y.; et al. SpecAugment: a simple data augmentation method for automatic speech recognition. In Proceedings of the Interspeech 2019, Graz, Austria, September 15-19, 2019; ISCA, 2019; pp. 391-5.
234. Cao, B.; Teplansky, K.; Sebkhi, N.; Bhavsar, A. Inan, O.T.; Samlan, R.; Mau, T.; Wang, J. Data augmentation for end-to-end silent speech recognition for laryngectomees. In Proceedings of the Interspeech 2022, Incheon, Korea, September 18-22; ISCA, 2022; pp 3653-7.
235. Deng, Y.; Heaton, J. T.; Meltzner, G. S. Towards a practical silent speech recognition system. In Interspeech 2014, Singapore, September 14-18, 2014; ISCA, 2014; pp 1164-8.
236. Hahm, S.; Wang, J.; Friedman, J. Silent speech recognition from articulatory movements using deep neural network. In Proceedings of the ICPhS 2015 Proceedings, Glasgow, UK, August 10-14, 2015; IPA, 2015. https://www.internationalphoneticassociation.org/icphs-proceedings/ICPhS2015/Papers/ICPHS0524.pdf (accessed 2026-06-16).
237. Janke, M.; Wand, M.; Schultz, T. Impact of lack of acoustic feedback in EMG-based silent speech recognition. In Interspeech 2010, Chiba, Japan, September 26-30, 2010; ISCA, 2010; pp 2686-9.
238. Wand, M.; Janke, M.; Schultz, T. The EMG-UKA corpus for electromyographic speech processing. In Interspeech 2014, Singapore, September 14-18, 2014; ISCA, 2014; pp 1593-7.
239. Dietrich, M. The effects of stress reactivity on extralaryngeal muscle tension in vocally normal participants as a function of personality. Ph.D. Dissertation, University of Pittsburgh, Pittsburgh, PA, USA, 2009. https://d-scholarship.pitt.edu/concern/etds/96f5b541-089e-446d-9fdf-5dd673fef5b8 (accessed 2026-06-16).
240. Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE. Trans. Inform. Theory. 1967, 13, 260-9.
241. Kimura, N.; Su, Z.; Saeki, T. End-to-end deep learning speech recognition model for silent speech challenge. In Proceedings of the Interspeech 2020, Shanghai, China, October 25-29, 2020; ISCA, 2020; pp 1025-6. https://www.isca-archive.org/interspeech_2020/kimura20_interspeech.pdf (accessed 2026-06-16).
242. Ferreira, D.; Silva, S.; Curado, F.; Teixeira, A. RaSSpeR: Radar-Based Silent Speech Recognition. In Interspeech 2021, Brno, Czechia, August 30-September 3, 2021; ISCA, 2021; pp 646-50.
243. Cai, H.; Zhang, Y.; Xie, L.; et al. A facial electromyography activity detection method in silent speech recognition. In Proceedings of the 2021 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Macau, China, December 5-7, 2021; IEEE, 2021; pp 246-51.
244. El-bialy, R.; Chen, D.; Fenghour, S.; et al. Developing phoneme-based lip-reading sentences system for silent speech recognition. CAAI. Trans. on. Intel. Tech. 2022, 8, 129-38.
245. Chen, X.; Zhang, X.; Chen, X.; Chen, X. Encoder-decoder architectures for silent speech recognition based on high-density surface electromyogram. In Proceedings of the 2022 International Conference on Advanced Robotics and Mechatronics (ICARM), Guilin, China, July 9-11, 2022; IEEE, 2022; pp 760-3.
246. Vorontsova, D.; Menshikov, I.; Zubov, A.; et al. Silent EEG-speech recognition using convolutional and recurrent neural network with 85% accuracy of 9 words classification. Sensors 2021, 21, 6744.
247. Wang, X.; Su, Z.; Rekimoto, J.; Zhang, Y. Watch your mouth: silent speech recognition with depth sensing. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, May 11-16, 2024; ACM: New York, NY, USA, 2024; pp 1-15.
248. Sun, X.; Xiong, J.; Feng, C.; et al. EarSSR: silent speech recognition via earphones. IEEE. Trans. on. Mobile. Comput. 2024, 23, 8493-507.
249. Amini Digehsara, P.; Possamai De Menezes, J. V.; Wagner, C.; et al. A user-friendly headset for radar-based silent speech recognition. In Proceedings of the Interspeech 2022, Incheon, Korea, September 18-22; ISCA, 2022; pp 4835-9.
250. Wagner, C.; Schaffer, P.; Amini Digehsara, P.; Bärhold, M.; Plettemeier, D.; Birkholz, P. Silent speech command word recognition using stepped frequency continuous wave radar. Sci. Rep. 2022, 12, 4192.
251. Lee, K. Ultrasonic doppler based silent speech interface using perceptual distance. Appl. Sci. 2022, 12, 827.
252. Luo, J.; Wang, J.; Cheng, N.; Jiang, G.; Xiao, J. End-to-end silent speech recognition with acoustic sensing. In Proceedings of the Proceedings of the 2021 IEEE Spoken Language Technology Workshop, Shenzhen, China, January 19-22, 2021; IEEE, 2021; pp 606-12.
253. Yi, C.; Wei, B.; Zhu, J.; Rho, S.; Chen, Z.; Jiang, F. Mordo: silent command recognition through lightweight around-ear biosensors. IEEE. Internet. Things. J. 2023, 10, 763-73.
254. Yi, C.; Wei, B.; Zhu, J.; et al. Mordo2: a personalization framework for silent command recognition. IEEE. Trans. Neural. Syst. Rehabil. Eng. 2024, 32, 133-43.
255. Zeng, S.; Wan, H.; Shi, S.; Wang, W. mSilent: towards general corpus silent speech recognition using COTS mmWave radar. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2023, 7, 1-28.
256. Yeo, J. H.; Kim, M.; Choi, J.; Kim, D. H.; Ro, Y. M. AKVSR: audio knowledge empowered visual speech recognition by compressing audio knowledge of a pretrained model. IEEE. Trans. Multimedia. 2024, 26, 6462-74.
257. Li, H.; Liang, Y.; Gao, H.; et al. Silent speech interface with vocal speaker assistance based on convolution-augmented transformer. IEEE. Trans. Instrum. Meas. 2023, 72, 1-11.
258. Tóth, L.; Shandiz, A. H.; Gosztolya, G.; Gábor, C. T. Adaptation of tongue ultrasound-based silent speech interfaces using spatial transformer networks. arXiv 2023, arXiv:2305.19130. Available online: https://arxiv.org/abs/2305.19130 (accessed 16 June 2026).
259. Li, H.; Lin, H.; Wang, Y.; et al. Sequence-to-sequence voice reconstruction for silent speech in a tonal language. Brain. Sci. 2022, 12, 818.
260. Li, Z.; Ma, B.; Mao, W.; Zhang, J.; Yu, Z.; Lu, Y. SVIT-SSR: A sEMG-based vision transformer approach for silent speech recognition. Electron. Lett. 2024, 60, e13285.
261. Frey, S.; Spacone, G.; Cossettini, A.; et al. BioGAP-Ultra: a modular edge-AI platform for wearable multimodal biosignal acquisition and processing. IEEE. Trans. Biomed. Circuits. Syst. 2026, 20, 399-415.
262. Xu, J.; Yu, J.; Hu, S.; Liu, X.; Meng, H. Mixed precision low-bit quantization of neural network language models for speech recognition. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2021, 29, 3679-93.
263. Spacone, G.; Frey, S.; Pollo, G.; et al. SilentWear: an ultra-low power wearable system for EMG-based silent speech recognition. arXiv 2026, arXiv:2603.02847. Available online: https://arxiv.org/abs/2603.02847 (accessed 16 June 2026).
264. Ota, K. Data augmentation method based on three-dimensional measurement for silent speech recognition. Acoust. Sci. Technol. 2024, 45, 329-32.
265. Jin, Y.; Gao, Y.; Xu, X.; et al. EarCommand: "Hearing" your silent speech commands in ear. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2022, 6, 1-28.
266. Su, Z.; Fang, S.; Rekimoto, J. Multimodal silent speech-based text entry with word-initials conditioned LLM. In Proceedings of the Proceedings of the 7th ACM Conference on Conversational User Interfaces, Waterloo, Canada, July 8-10, 2025; ACM: New York, NY, USA, 2025; pp 1-14.
267. Shuzo, M.; Hiramoto, R.; Ishigaki, R.; Ando, S.; Sakai, M. Development of an EEG-based silent speech recognition model on the native arabic silent speech dataset using light BERT architecture. Int. J. Act. Behav. Comput. 2025, 2025, 1-16.
268. Benster, T.; Wilson, G.; Elisha, R.; Willett, F. R.; Druckmann, S. A cross-modal approach to silent speech with LLM-enhanced recognition. arXiv 2024, arXiv:2403.05583. Available online: https://arxiv.org/abs/2403.05583 (accessed 16 June 2026).
269. Cote-allard, U.; Gagnon-turcotte, G.; Phinyomark, A.; et al. A transferable adaptive domain adversarial neural network for virtual reality augmented EMG-based gesture recognition. IEEE. Trans. Neural. Syst. Rehabil. Eng. 2021, 29, 546-55.
270. Cui, Q.; Zhang, X.; Zhang, Y.; et al. A simplified adversarial architecture for cross-subject silent speech recognition using electromyography. J. Neural. Eng. 2024, 21, 056001.
271. Makhoul, J.; Kubala, F.; Schwartz, R.; Weischedel, R. Performance measures for information extraction. In Proceedings of the Proceedings of the DARPA Broadcast News Workshop, Herndon, VA, February 28-March 3, 1999; Morgan Kaufmann: San Mateo, CA, USA, 1999. https://ccc.inaoep.mx/~villasen/bib/slot%20error%20rate.pdf (accessed 2026-06-16).
272. Rix, A. W.; Beerends, J. G.; Hollier, M. P.; Hekstra, A. P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, May 7-11, 2001; IEEE, 2001; pp 749-52.
273. Zheng, R. C.; Ai, Y.; Ling, Z. H. Incorporating ultrasound tongue images for audio-visual speech enhancement. IEEE/ACM. Trans. Audio. Speech. Lang. Process. 2024, 32, 1430-44.
274. Powers, D. M. W. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. Available online: https://arxiv.org/abs/2010.16061 (accessed 16 June 2026).
275. Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, Canada, May 19-21, 1993; IEEE, 1993; pp 125-8.[DOI: 10.1109/PACRIM.1993.407206].
276. Qian, Y.; Liu, C.; Yu, P.; et al. Real-time decoding of full-spectrum Chinese using brain-computer interface. Sci. Adv. 2025, 11, eadz9968.
277. Röddiger, T.; Küttner, M.; Lepold, P.; et al. OpenEarable 2.0: open-source earphone platform for physiological ear sensing. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2025, 9, 1-33.
278. Chang, Z.; Wang, L.; Li, B.; Liu, W. MetaEar: imperceptible acoustic side channel continuous authentication based on ERTF. Electronics 2022, 11, 3401.
279. Tan, J.; Wang, X.; Nguyen, C.; Shi, Y. SilentKey: a new authentication framework through ultrasonic-based lip reading. Proc. ACM. Interact. Mob. Wearable. Ubiquitous. Technol. 2018, 2, 1-18.
280. Yao, S.; Zhou, W.; Hinson, R.; et al. Ultrasoft porous 3D conductive dry electrodes for electrophysiological sensing and myoelectric control. Adv. Mater. Technol. 2022, 7, 2101637.
281. Sun, B.; Mccay, R. N.; Goswami, S.; et al. Gas-permeable, multifunctional on-skin electronics based on laser-induced porous graphene and sugar-templated elastomer sponges. Adv. Mater. 2018, 30, 1804327.
282. Koelle, M.; Boll, S.; Olsson, T.; et al. (Un)Acceptable!?!: Re-thinking the social acceptability of emerging technologies. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, Canada, April 21-26, 2018; ACM: New York, NY, USA, 2018; pp 1-8.
283. Yang, D.; Tian, G.; Chen, J.; et al. Neural electrodes for brain-computer interface system: from rigid to soft. BMEMat 2025, 3, e12130.
284. Wu, N.; Wan, S.; Su, S.; Huang, H.; Dou, G.; Sun, L. Electrode materials for brain-machine interface: a review. InfoMat 2021, 3, 1174-94.
285. Polikov, V.S.; Tresco, P.A.; Reichert, W. M. Response of brain tissue to chronically implanted neural electrodes. J. Neurosci. Methods. 2005, 148, 1-18.
286. Oxley, T. J.; Opie, N. L.; John, S. E.; et al. Minimally invasive endovascular stent-electrode array for high-fidelity, chronic recordings of cortical neural activity. Nat. Biotechnol. 2016, 34, 320-7.
287. Kacker, K.; Chetty, N.; Feldman, A. K.; et al. Motor activity in gamma and high gamma bands recorded with a Stentrode from the human motor cortex in two people with ALS. J. Neural. Eng. 2025, 22, 026036.
288. Zhou, D.; Zhang, Y.; Wu, J.; Zhang, X.; Xie, L.; Yin, E. AVE Speech Dataset: a comprehensive benchmark for multi-modal speech recognition integrating audio, visual, and electromyographic signals. arXiv 2025, arXiv:2501.16780. Available online: https://arxiv.org/abs/2501.16780 (accessed 16 June 2026).
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Special Topic
Copyright

Data & Comments
Data
0













Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].