



fig2
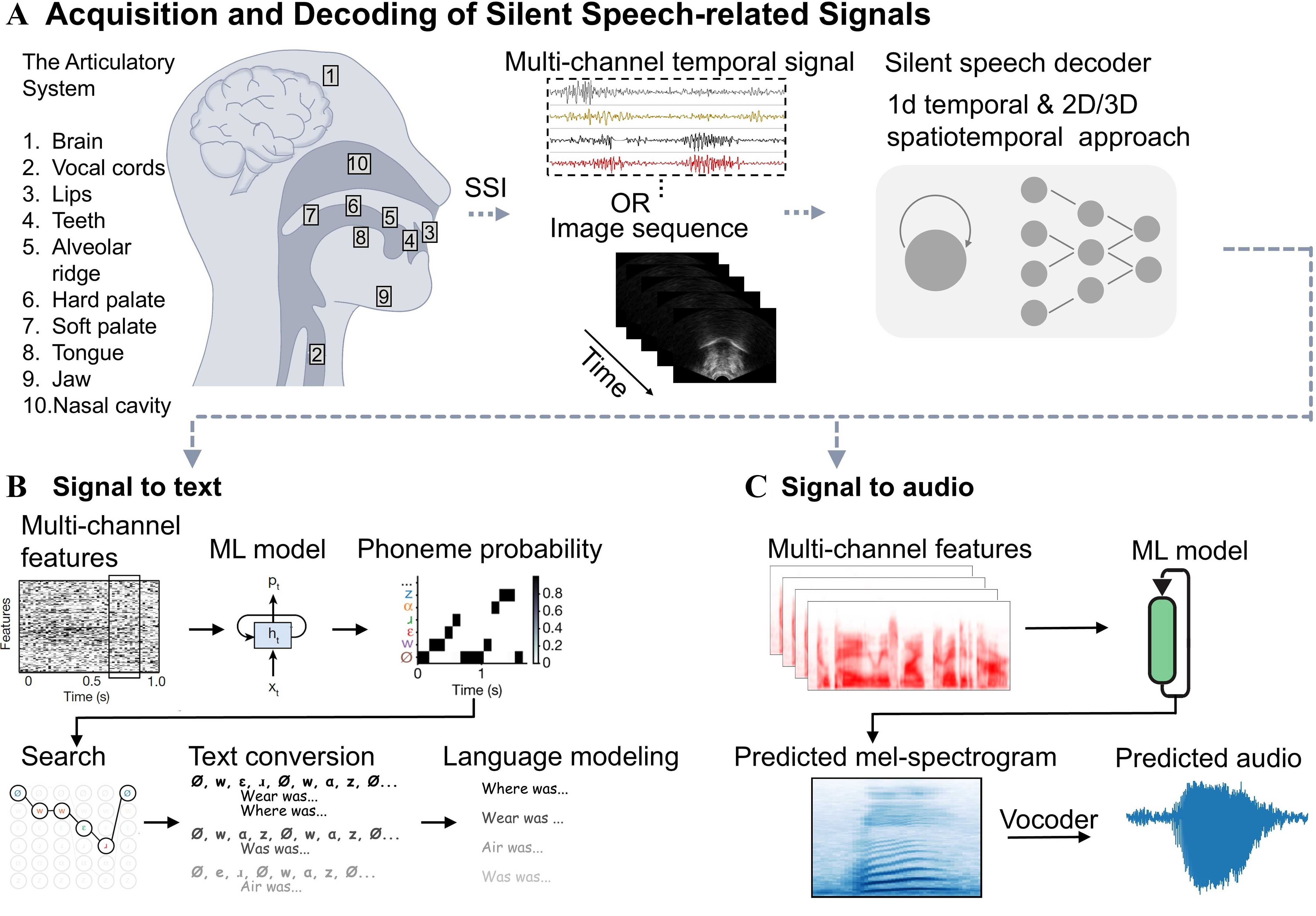
Figure 2. The representative recognition process of silent speech. (A) The sagittal view of the articulatory system and signal acquisition and decoding process for silent speech. This illustration details an algorithmic pipeline for SSIs that employ 1D temporal frameworks (e.g., time-series data like EMG) and/or 2D/3D spatiotemporal frameworks (e.g., image sequences or data from high-density spatial arrays). A representative process for converting silent speech signals into (B) text and (C) speech audio. The schematics in (B) and (C) represent multi-channel features in the time and frequency domains, respectively. Please note that features from both domains are widely utilized in signal-to-text and signal-to-audio conversions. A detailed discussion of decoding models is provided in Section 4. The image sequence in (A): Adapted from Ref. [55], under CC BY 4.0 license. Figure (B) is adapted from Ref. [38], under CC BY 4.0 license. Figure C is adapted from Ref. [56], under CC BY 4.0 license. 1D: One-dimensional; 2D: two-dimensional; 3D: three-dimensional; EMG: electromyography; SSIs: silent speech interfaces; ML: machine learning.





