





fig3
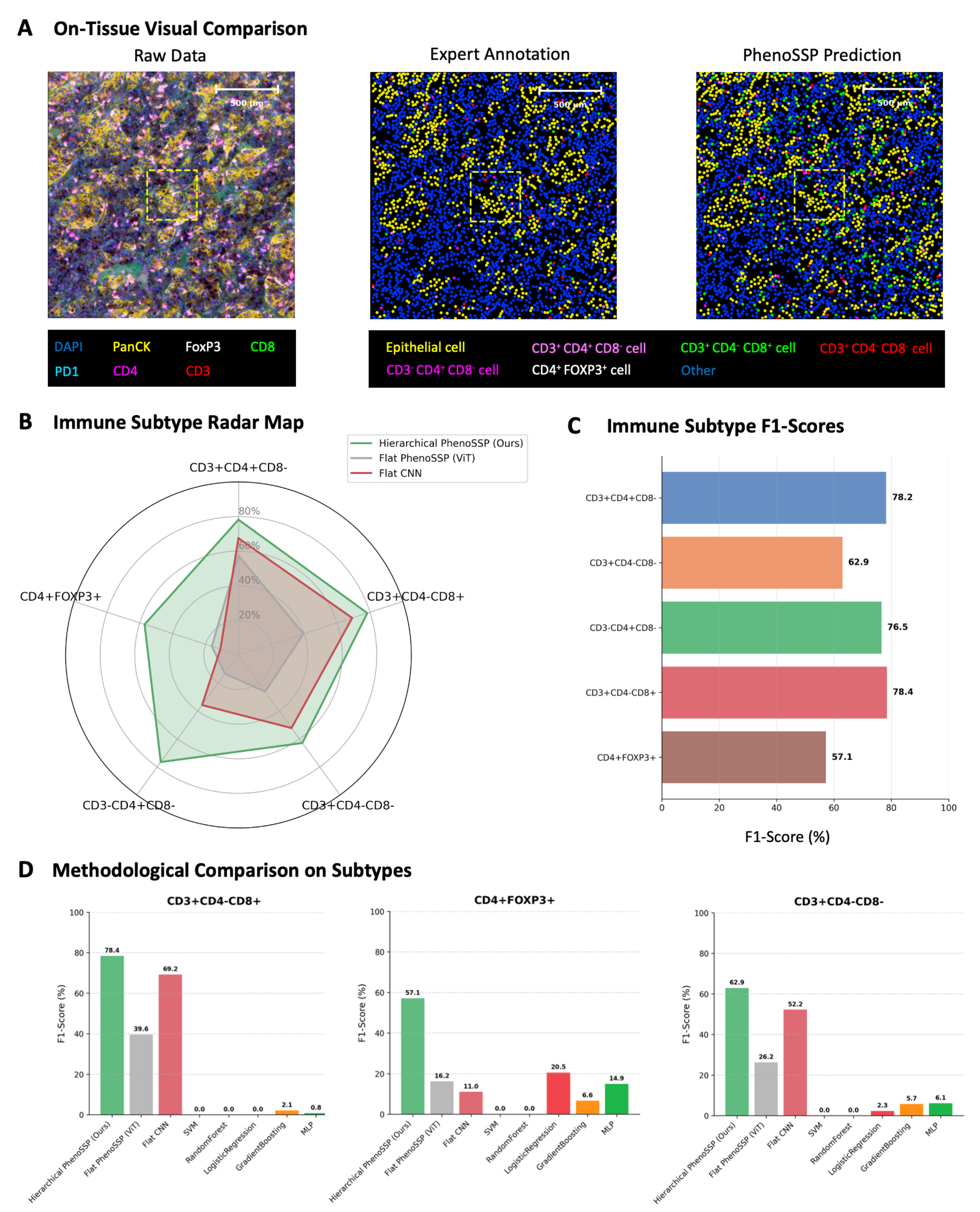
Figure 3. Visual and quantitative validation of model robustness. (A) On-tissue visual comparison. Phenotype maps generated by PhenoSSP (right) demonstrate high morphological fidelity and spatial concordance with Expert Annotations (center) compared to the noisy Raw Data (left). The zoomed-in regions highlight the precise localization of individual immune cells within the TME; (B) Immune Subtype Radar Map. A holistic comparison of F1-scores across five immune subtypes. The Hierarchical PhenoSSP (green area) consistently encompasses the Flat ViT and Flat CNN baselines, indicating superior performance across all categories; (C) Immune Subtype F1-scores. Bar chart detailing the specific F1-scores achieved by PhenoSSP on the held-out test set, showing strong performance (> 76%) on major T cell subsets and robust detection (> 57%) on rare Tregs; (D) Methodological Comparison on Subtypes. Comparative analysis against traditional machine learning methods (SVM, random forest, etc.) and flat deep learning baselines. PhenoSSP significantly outperforms traditional methods (which fail on complex multi-marker phenotypes) and shows marked improvement over Flat ViT/CNN architectures. TME: Tumor microenvironment; ViT: Vision Transformer; CNN: convolutional neural network; Tregs: regulatory T cells; SVM: support vector machine; DAPI: 4′,6-diamidino-2-phenylindole; MLP: multi-layer perceptron.





