


fig14
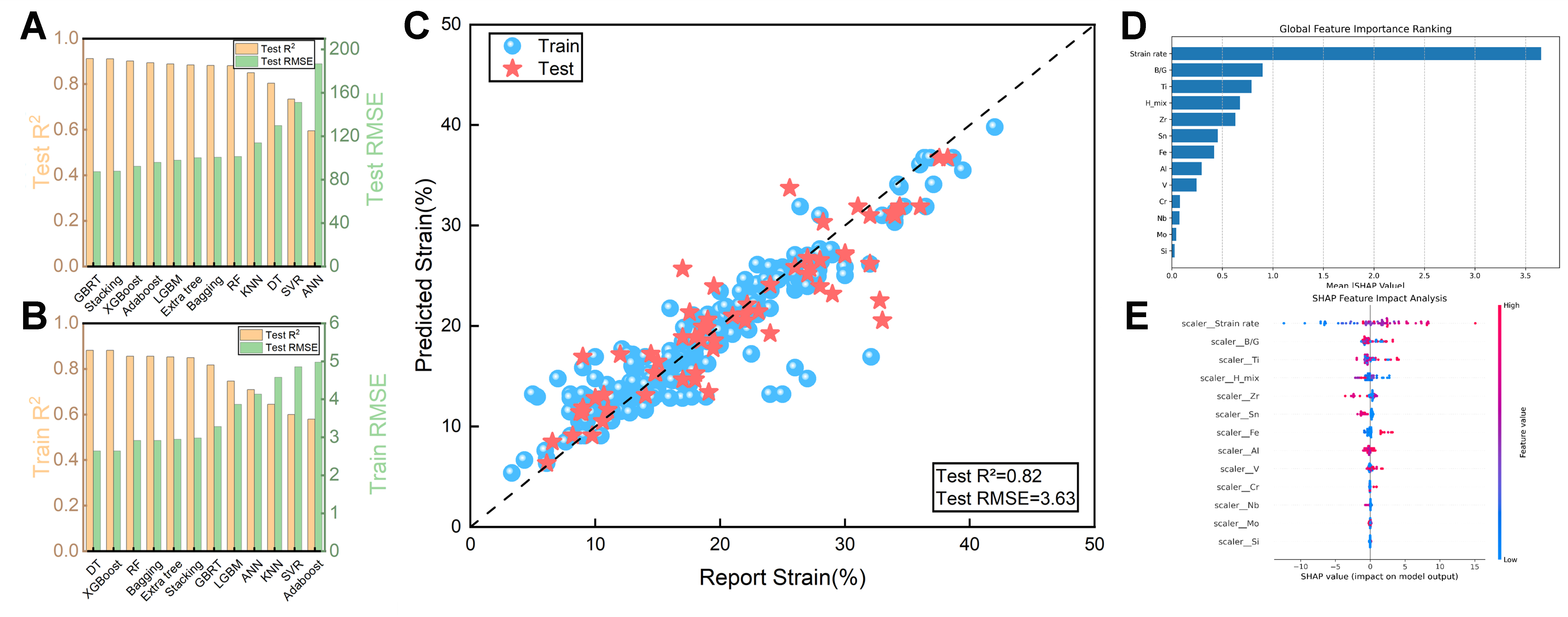
Figure 14. Performance comparison of 12 feature models in a new plastic strain dataset constructed based on “components + domain knowledge” and analysis of the importance of SHAP values of the features. (A and B) are respectively the training set results and test set results of the 12 fitted machine learning models; (C) The optimal RF model fitting graph of the new plastic dataset constructed based on “components + domain knowledge”; (D and E) are the bar charts and bee colony plots for the SHAP importance analysis of the new plastic strain dataset constructed based on “component + domain knowledge”. SHAP: SHapley Additive exPlanations; RF: random forest; R2: the coefficient of determination; RMSE: root mean square error; GBRT: gradient boosting regression tree; XGBoost: eXtreme gradient boosting; AdaBoost: adaptive boosting; LGBM: light gradient boosting machine; ExtraTree: extremely randomized tree; Bagging: bootstrap aggregating; KNN: K-nearest neighbor; DT: decision tree; SVR: support vector regression; ANN: artificial neural network.




