

A probabilistic approach to drift estimation from stochastic data
 0
0 Abstract
Time series generated from a dynamical source can often be modeled as sample paths of a stochastic differential equation. The time series thus reflects the motion of a particle that flows along the direction provided by a drift/vector field, and is simultaneously scattered by the effect of white noise. The resulting motion can only be described as a random process instead of a solution curve. Due to the non-deterministic nature of this motion, the task of determining the drift from data is quite challenging, since the data does not directly represent the directional information of the flow. This paper describes an interpretation of a drift as a conditional expectation, which makes its estimation feasible via kernel-integral methods. In addition, some techniques are proposed to overcome the challenge of dimensionality if the stochastic differential equations carry some structure enabling sparsity. The technique is shown to be convergent, consistent and permits a wide choice of kernels.
Keywords
1. Introduction
The dynamics present in several physical phenomena are governed by both deterministic laws of motion and stochastic driving terms. Stochastic differential equations (SDEs) provide a common mathematical description for these phenomena. A general
in which the term
This article focuses on the data-driven discovery of SDEs. A convergent and consistent technique is presented for estimating the drift term
The Weiner process that drives an SDE of the form (1) can also be interpreted as a probability space, whose domain is the path-space
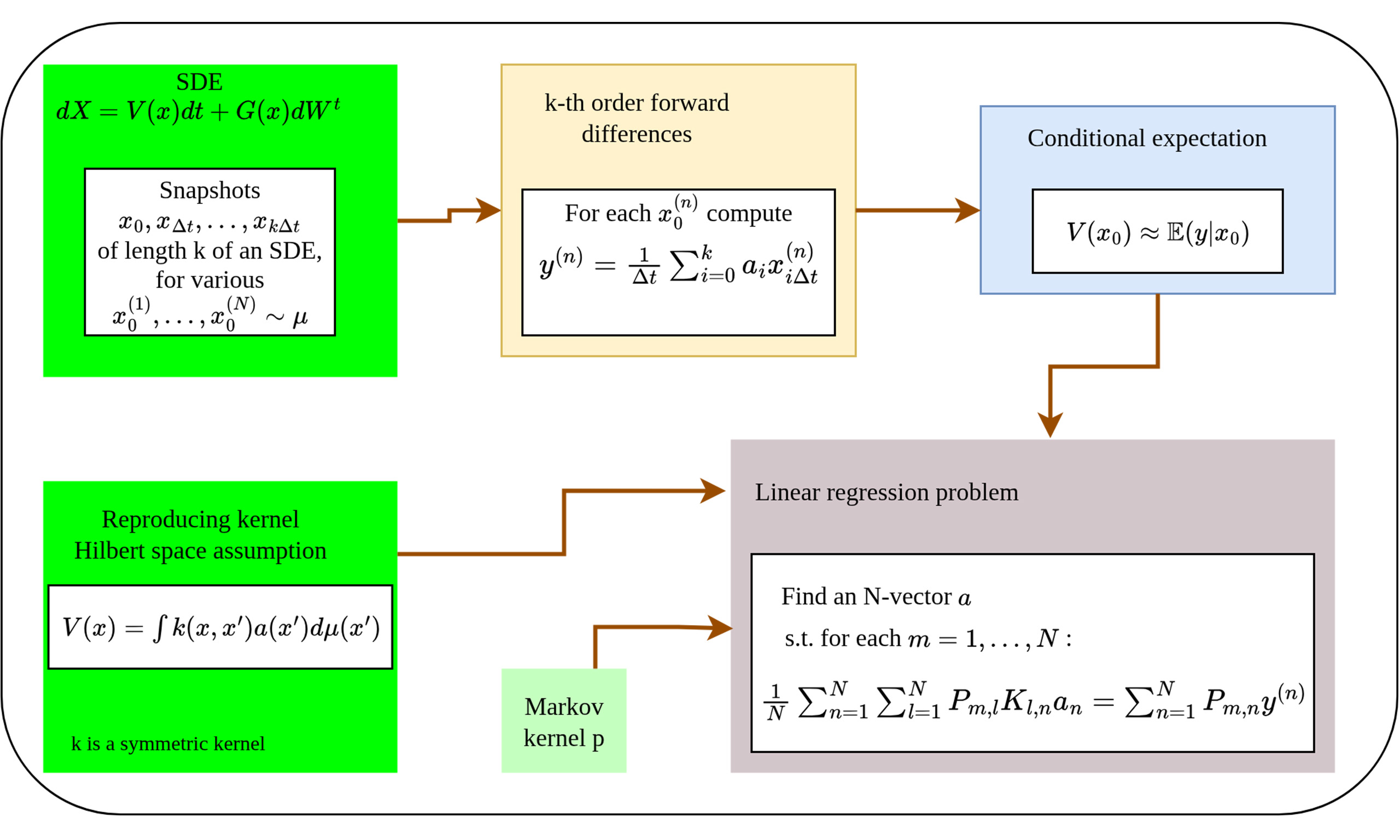
Drift estimation of SDE time series requires a treatment completely different from those used for numerical differentiation. Figure 1 provides an outline of the mathematical problem, and the proposed method of converting it into a task of conditional expectation. In the usual probabilistic approach to SDEs, the initial state
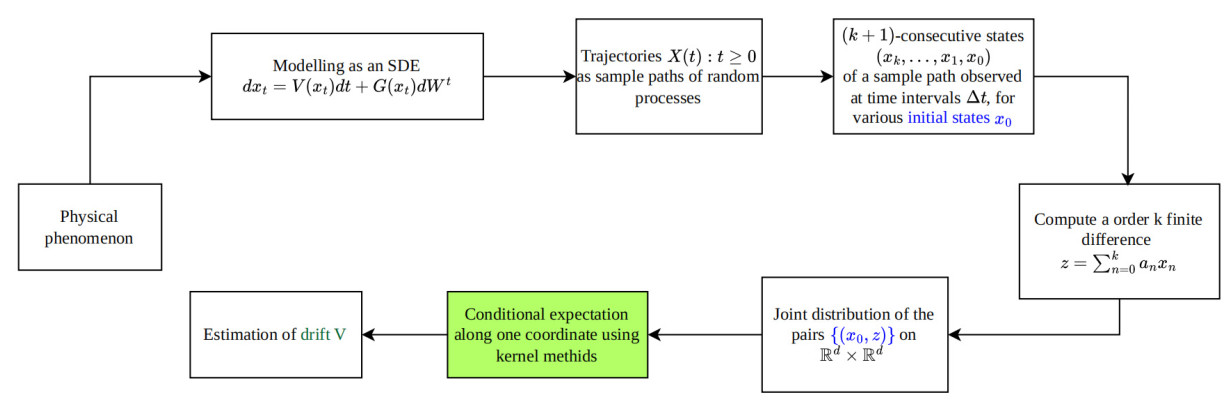
Figure 1. Outline of the theory. Many dynamical processes in nature can be modeled as an SDE, which has a drift and diffusion component. Unlike deterministic systems, the consecutive points on a trajectory are not related deterministically, but have a distribution. The flowchart shows how we can collect
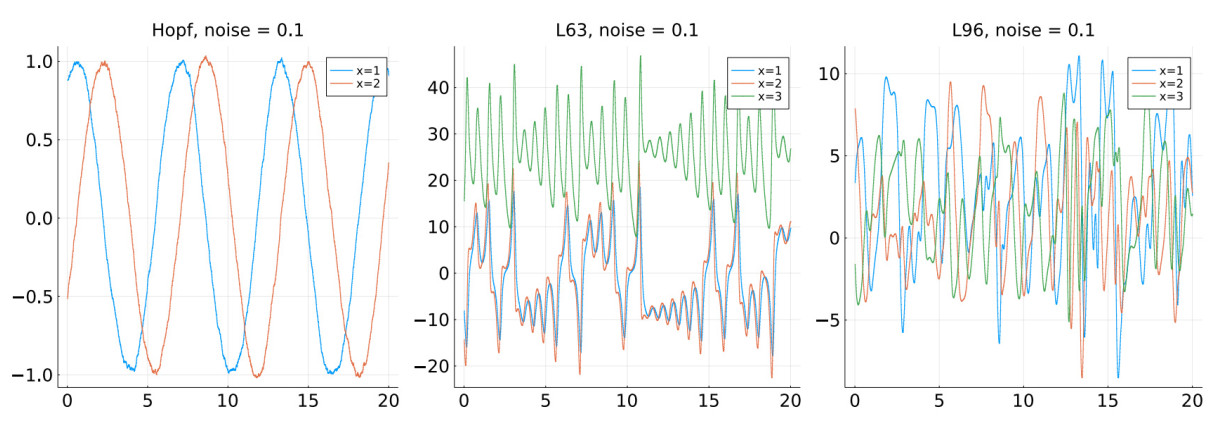
Figure 2. Orbits from SDEs. The three plots show sample paths of SDEs, in which the drifts are respectively the Hopf oscillator (27), Lorenz- 63 system (26) and the Lorenz 96 system (28). The SDEs have a diagonal diffusion term given by (29). The parameters of the experiments are provided in Table 1. The legends indicate the index of the coordinates being plotted. The paper presents a numerical method for extracting the drift from such time series generated by SDEs. The results of the reconstruction have been displayed in Figures 3, 4, 5, respectively.
Summary of parameters in experiments. In all these experiments, the number of …
| System | Properties | Figures | ODE parameters | Data samples |
| Lorenz 63 (26) | Chaotic system in | Figures 3 and 7 | ||
| Hopf oscillator (27) | Stable periodic cycle in | Figures 4 and 6 | ||
| Lorenz 96 (28) | Chaotic system of | Figures 5 and 8 |
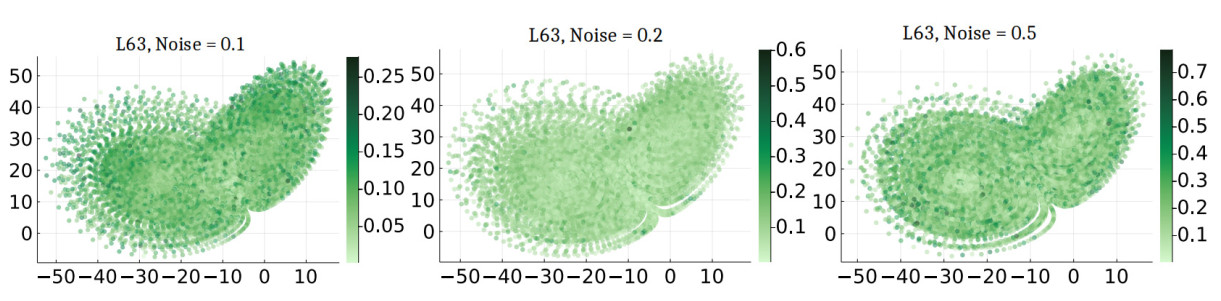
Figure 3. Estimating the drift in a stochastic Lorenz 63 model. The three figures present a heatmap of the pointwise error in computing the drift (26). The colored area of the phase space represents the support of the stationary measure of the underlying SDE.
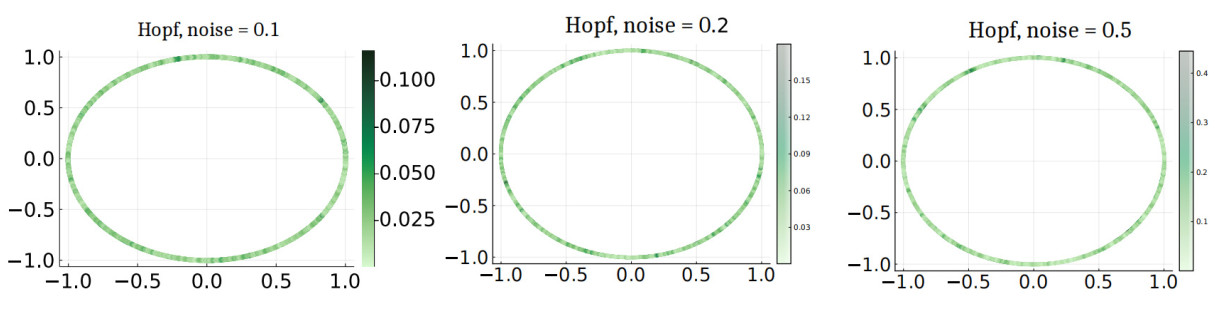
Figure 4. Estimating the drift in a stochastic version of the Hopf oscillator (27). The images carry the same interpretation as Figure 3.
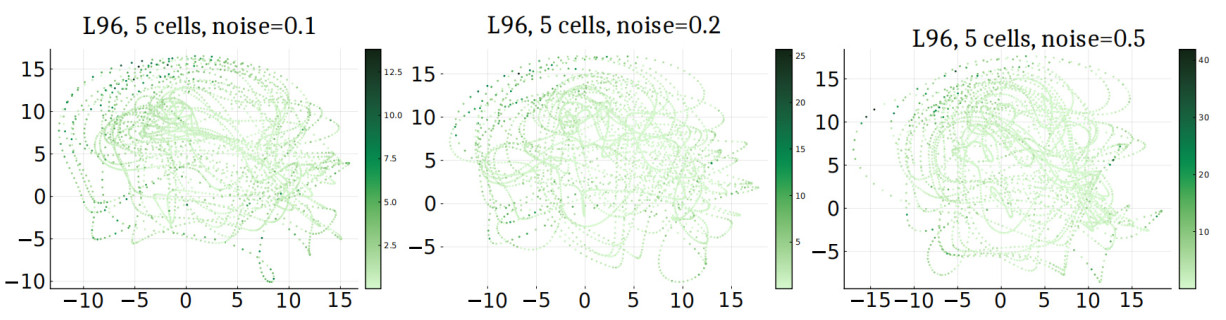
Figure 5. Estimating the drift in a stochastic version of the L96 system (28) with 5 oscillators. The images carry the same interpretation as Figure 3.
Assumption 1 The SDE (1) has a stationary probability measure
Stationarity of
A Markov process can be alternatively studied by the continuous transformation it induces on probability measures. Recall that the distribution of
where
Equation (3) is a combination of a second order differential operator, the measure theoretic operation of conditional expectation, and a time derivative. It provides a bridge between statistical properties (i.e., the distribution of the data), and differential properties (i.e., the drift). Of special interest to us is the particular instance of (3) when
Equation (4) is the core mathematical principle of our numerical technique. In fact, we use a third order version of (4) given by
This identity is based on a Taylor series expansion of operator
The precise nature of the convergence depends upon the regularity of
A careful design of a procedure for this task requires a careful understanding of the nature of the data. Formally, we assume the following about the data:
Assumption 2 There is sampling interval
Thus, our assumption on the data is that we have snapshots of sample trajectories of length at least
Our goal can now be precisely stated to be the estimation of the drift
(ⅰ) The technique is nonparametric; i.e., it does not assume a prescribed parametric format, such as Gaussian processes [20] or semi-parametric forms such as linear diffusion terms [21]
(ⅱ) The technique is convergent with data.
(ⅲ) The technique does not assume a prior distribution; such as Gaussian priors [22,23].
(ⅳ) The technique is adaptable to high dimensional systems.
Effective nonparametric techniques have been built [24,25] which are well suited to sparse sampling but rely on the assumption of prior distributions. Another important work [26] considers data collected from SDE sampled at uneven intervals. Besides the probabilistic approach presented in this article, four other notable and distinct techniques deserve special mention - a model reduction technique of Ye et al.[27]; the one based on the Magnus expansion [28]; a back-stepping technique that converts the nonlinear process into an Ornstein-Uhlenbeck (OU) process [29]; and the multi-level parameter estimation network for parametric SDEs with jump noises. Our technique achieves all of the first three objectives and overcomes the challenge of dimensionality in vector fields structured in a certain way, as explained later in Section 5.
Our method is based on a measure theoretic insight. Set two spaces
These two spaces
Due to the stationarity assumption from Assumption 1, there is a natural measure
Let
Thus, the task of estimating the drift has been transformed into the task of finding the conditional estimation of one projection function w.r.t. another. The conditional expectation is reconstructed or learnt using an operator theoretic tool from [30]. It will be a combination of kernel-based techniques and the third order approximation of (8). This completes a description of the problems we aim to solve, and the underlying mathematical principles.
Outline We next present in Section 2 a numerical recipe for implementing the conditional expectation route to drift estimation. Subsequently, in Section 3, we discuss the convergence of our methods, and identify the dependence of the convergence on factors such as data size and noise levels. Then, in Section 4, we apply the technique to some common examples from Dynamical systems theory. The examples reveal the challenges posed by high dimensional systems. We propose some adjustments to the algorithms to overcome this practical challenge in Section 5. We end with some discussions in Section 6, summarizing our results and discussing new challenges.
2. The technique
Our technique makes multiple and different uses of kernels and kernel integral methods. A kernel on a space
The bandwidth
The kernel
Thus, if the kernel
We next present a useful notation: Let
We now present our first algorithm from [30] for computing conditional expectation from data.
Algorithm 1 Kernel base estimation of conditional expectation.
● Input. A sequence of pairs
● Parameters.
1. Strictly positive definite kernel
2. Smoothing parameter
3. Sub-sampling parameter
4. Ridge regression parameter
● Output. A vector
which approximates the conditional expectation of the y-variable w.r.t. the x variable.
● Steps.
1. Compute a Gaussian Markov kernel matrix using (10):
2. Compute a Markov kernel
3. Compute the kernel matrix
4. Find a vector
Algorithm 1 has two components, the choice of a reconstruction kernel
Lemma 0.1 ([30, Thm 2]) Suppose there is a probability space
Algorithm 1 is a general algorithm for computing conditional expectation, and is at the core of our numerical procedure. We make an important note here that the application of the Gaussian smoothing
Algorithm 2 Drift estimation as a conditional expectation
● Input. Dataset
● Parameters. Same as Algorithm 1.
● Output. A matrix
● Steps.
1. Compute
2. For each
3. Store the result in a
4. Compute the
The convergence of Algorithm 2 is guaranteed by Lemma 0.1 and (8). We investigate this convergence more closely in the next section.
3. Convergence analysis
In this section, we conduct a precise analysis on the convergence of our results and its dependence on various algorithmic and data-source parameters. Throughout this section we assume that Assumptions 1 and 2 hold; the drift and diffusion terms in (1) are continuous functions; and that
Theorem 1 (Almost sure convergence) Suppose Assumptions 1 and 2 hold. If the drift
Theorem 1 will be shown to be a consequence of functional analytic results from the work by Das [30]. The convergence result does not reveal the dependence of the rate of convergence on the choice of parameters. It also relies on the assumption that
(ⅰ) the number of data-samples
(ⅱ) choice of the sub-sampling parameter
(ⅲ) a regularization parameter
The next theorem presents a more nuanced view of the convergence, in terms of error bounds:
Theorem 2 (Parameter selection within error bounds) Suppose Assumptions 1 and 2 hold. Fix error bounds
(ⅰ) For
Here,
(ⅱ) Given such a choice of
(ⅲ) Fix such a
such that for every
Theorem 2 also presents the order in which the parameters are to be tuned, starting with
The proofs of both theorems emerge from a careful comparison of the output of the algorithm against the true drift. Recall the spaces
Algorithm 1 implements the least-squares regression problem posed in (16). The measures
Similarly, given any measure
where we have set
Each of the matrices represented in square brackets above is also a kernel integral operator w.r.t. the finite empirical measures
Separating noise Since we have replaced
In the limit of infinite data,
The left-hand side (LHS) of (19) is the right-hand side (RHS) of the regression problem being solved in (16) and (17). Thus, (19) expresses the RHS of the regression problem as an integral transform
Recall that each datapoint can be represented as a pair
Equation (8) says that the expected value of the
Approximation 1. Henceforth, we shall assume a fixed number
Fix an error level
Thus,
We shall assume henceforth that the true image
Approximation 2 Equations (17), (18) and (19) together imply
Incorporating the assumption
Thus,
Approximation 3 Note that the limit in (15) holds irrespective of the nature of
Since we keep the sub-sampling parameter
One important property of the convergence in (25) is that
Approximation 4 The self adjoint operator
Then according to (19), we have
Equation (21) interprets the noise variable
The distribution of increments of a process defined by an SDE usually lacks an analytic formula. However, due to the continuity of
In other words, for positive
We have declared the quantity to be a random variable
So, to bound the uncertainty by
This concludes the description of our methods and the underlying theory. We next describe some numerical experiments to test our technique on.
4. Examples
In this section, we put our algorithms to the test. The systems that we investigate are as follows:
1. Lorenz 63. This is the benchmark problem for studying chaotic phenomena in three dimensions, which is the lowest dimension in which chaos is possible[37].
2. Hopf oscillator. The Hopf oscillator is used as a simple parametric model to study the phenomenon of Hopf bifurcations. Given a constant
3. Lorenz 96. The Lorenz 96 model is a dynamical system formulated by Edward Lorenz in 1996
This model mimics the time evolution of an unspecified weather measurement collected at
The steps in each experiment were as follows:
1. The parameters for the ODEs were set according to Table 1.
2. The ODEs were converted into an SDE with the help of a diagonal diffusion term
3. The constant
4. Algorithm 2 was applied to a sample path of the SDE. The parameters for the algorithm were auto-tuned as described in Table 2.
Parameters which remain constant in the experiments
| Variable | |||
| Interpretation | Parameter for selecting the bandwidth | Dimensions of the image | Ridge regression parameter, as described in (11) |
| Value |
5. The choice of kernel
6. Some of the algorithmic parameters were auto-tuned according to the hyper-parameters listed in Table 3.
Auto-tuned parameters in experiments. The strategy outlined in (32) is used to determine the three bandwidth parameters
| Ridge regression parameter | Bandwidth | Bandwidth | Bandwidth |
| 0.1 | Chosen to achieve sparsity | Chosen to achieve sparsity | Chosen to achieve sparsity |
The choice of noise levels does not follow any specific design, other than providing an increasing sequence. Recall that a higher noise level requires a larger number of data points to approximate the conditional expectation. The highest value of
Choice of kernel Our choice of kernel in all the experiments is the diffusion kernel [40,41]. There are many versions of the diffusion kernel. We choose the following:
Diffusion kernels have been shown to be good approximants of the local geometry in various situations [42,43,44], and are a natural choice for nonparametric learning. We go one step further and perform a symmetrization:
where
The kernel
Again, because of the properties of
Bandwidth selection The proposed algorithm depends on several choices of bandwidth parameters, which also play the role of a smoothing parameter. We now present our method of selecting a bandwidth
Thus
Evaluating the results There is no certain way of evaluating the efficacy of a reconstruction technique for chaotic systems, as argued in [45,46]. In any data-driven approach such as ours, the reconstruction is done in dimensions higher than the original system. As a result, new directions of instability are introduced, and even if the drift is reconstructed with good precision, the simulation results might be completely different. For that purpose, our primary means of evaluating the accuracy of our drift reconstruction is by a pointwise evaluation of the reconstruction error, as shown in Figures 3, 4 and 5. The average errors are tabulated in Table 4. Also see Figures 6, 7, 8 and 9 for a comparison of orbits from the true system and the reconstructed system. It can be noted in the last two figures that the orbits of the reconstructed system get stuck in a false fixed point. This is an artifact of the technique of making out of sample evaluations, which we discuss next.
Relative
| Experiment | Noise 0.1 | Noise 0.2 | Noise 0.5 |
| Hopf oscillator (27) | 0.02 | 0.03 | 0.06 |
| Lorenz 63 (26) | 0.08 | 0.1 | 0.14 |
| Lorenz 96 (28) - 5 cells | 0.31 | 0.27 | 0.265 |
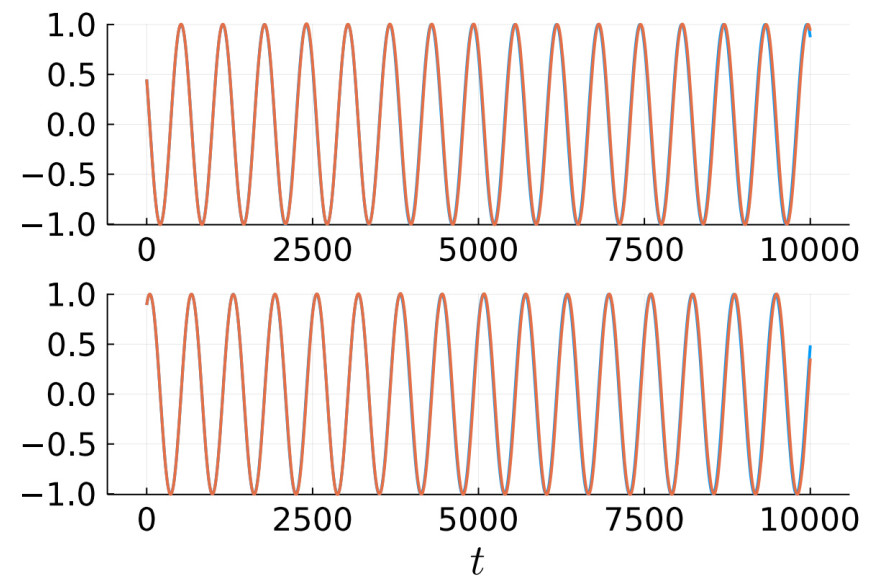
Figure 6. Reconstruction of the Hopf oscillator. The trajectories corresponding to the true and reconstructed drifts are in blue and orange, respectively. Due to a strong match in the reconstructed drifts, and the stability of rotational dynamics, the orbits overlap.
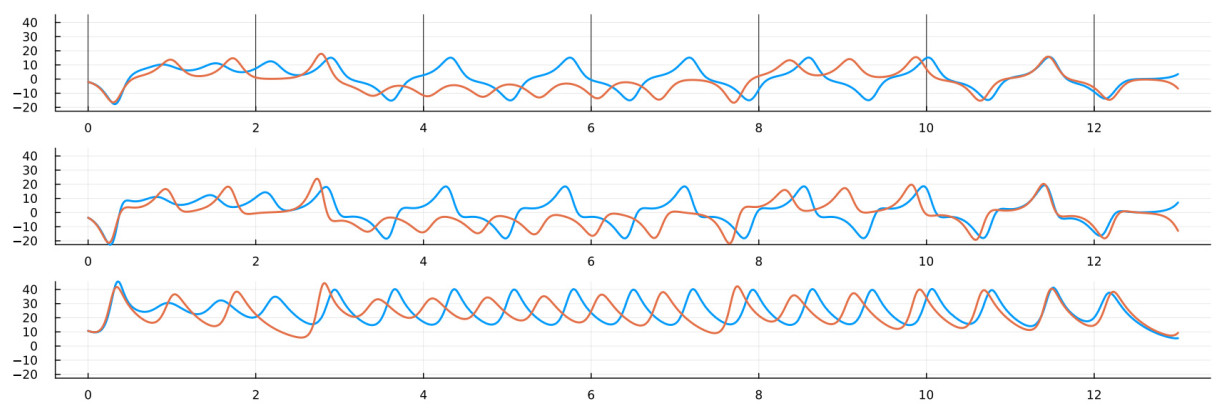
Figure 7. Reconstruction of the Lorenz 63 system. The trajectories corresponding to the true and reconstructed drifts are in blue and orange, respectively.
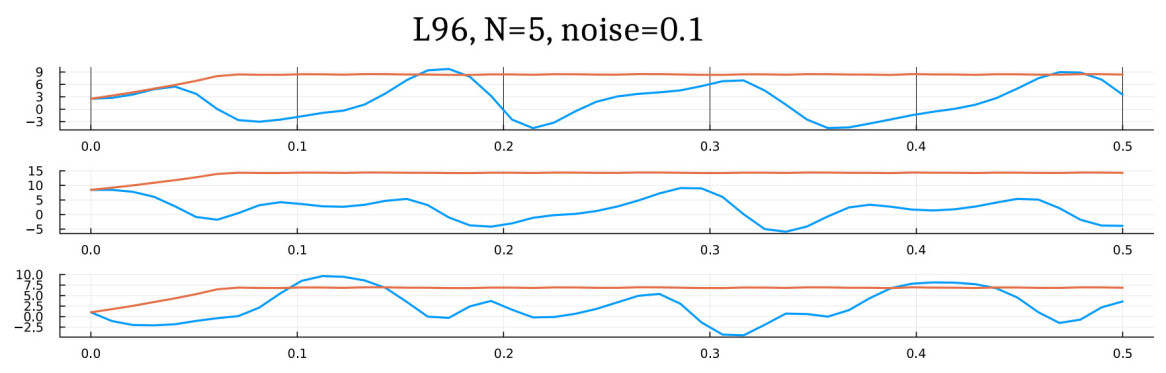
Figure 8. Reconstruction of the Lorenz 96 system with 5 cells. The orbits of the true and reconstructed systems diverge rapidly due to the presence of positive Lyapunov exponents in the L96 system. See Figure 9 for a closer look at the plots. The trajectories corresponding to the true and reconstructed drifts are in blue and orange, respectively.
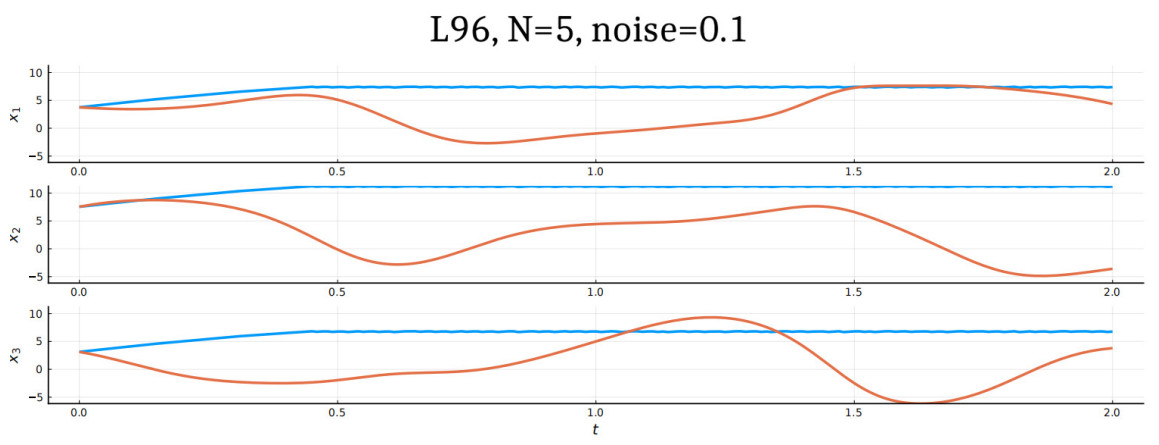
Figure 9. Reconstruction of the Lorenz 96 system with 5 cells. This figure offers a closer look at the graphs of Figure 8. The trajectories corresponding to the true and reconstructed drifts are in blue and orange, respectively.
Evaluating kernel functions Any kernel function
where the other terms are given by
Note that the vector
Summary of results Figure 2 represents some typical SDE orbits that were provided as input to the algorithms. The results of the reconstruction have been displayed in Figures 3, 4, and 5 respectively. The expected trend displayed is that data created out of higher noise levels lead to larger errors in reconstruction. While the plots present the pointwise comparisons, the root mean squared errors are summarized in Table 4. The trend can also be explained by the convergence analysis of the conditional expectation scheme.
An important test for drift reconstruction algorithms is their efficacy in reconstructing trajectories. To this end, we have compared the trajectories generated by the true drift, with trajectories generated by the simulated drift. The trajectories show excellent match for the periodic Hopf oscillator [Figure 6], and a close match for the Lorenz 63 model [Figure 7]. The Lorenz-63 model is a chaotic system, and the presence of positive Lyapunov exponents leads to an exponential divergence of trajectories. The gradual divergence of the trajectories in Figure 7 is indicative of a good reconstruction. It is also notable that the reconstructed orbit, even though divergent, remains topologically close to the true attractor
The 5-dimensional Lorenz-96 model presents a much steeper challenge, as evident from the trajectory comparison plots in Figures 8 and 9 respectively. As explained in Section 3 and Theorem 3.2, the rate of convergence depends on the number of data samples
5. Sparsity
The mechanism by which Algorithm 1 approximates the conditional expectations can be broadly described as computing averages w.r.t. various empirical measures. Empirical measure is the measure directly available to the algorithm. It is the discrete probability measure whose supports are the data points. The key principle behind the technique is that the empirical measure provides a weak approximation of the unknown measure
Assumption 3 Given the SDE (1), there is
(ⅰ) an integer
(ⅱ) a finite collection of functions
(ⅲ) and for each
such that
Assumption 3 says that effectively, each component of the drift
These projection maps create the following commutation with the coordinate projections
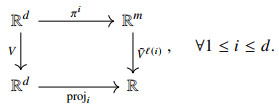
Taking
Recall the function
Equation (35) says that each component of the drift
To correctly utilize the strength of (35), we impose some restrictions on the data being used. A causally complete snapshot corresponding to an initial condition
Each initial condition
The conditional expectation scheme (35) can be numerically realized in a manner exactly analogous to Algorithm 2. The convergence rates undergo an analysis similar to Section 3. The scheme in (35) allows the components of the drift to be mined from high dimensional data, in which trajectories may be short, and partially missing in data. A numerical implementation of (35) to real-world high dimensional data is an important and promising project. These numerical investigations will be conducted in our forthcoming work.
6. Conclusions
Thus, we have demonstrated using theory and numerical examples that the drift component of an SDE can be extracted from data, using principles from Probability theory and the theory of Kernel integral operators. The drift can be expressed as a conditional expectation involving random variables, on a certain probability space. This conditional expectation in turn can be estimated as a linear regression problem using techniques from kernel integral operators. The algorithmic procedure that is created is completely data-driven. It receives as inputs snapshots of trajectories of the unknown SDE, and the only requirement is that the initial condition in each snapshot is equidistributed w.r.t. some stationary measure of the SDE. The numerical method worked well for the chaotic and quasiperiodic systems of dimensions less than 6 that we investigated. The performance deteriorates as the dimension increases.
Choice of parameters The three main tuning parameters in our algorithm are the Ridge regression
Choice of kernel Note that Algorithm 1 does not specify the kernel, and any RKHS-like kernel such as the diffusion kernel would be sufficient. The convergence laid down in Lemma 1 also does not depend on the choice of kernel. However, when finite data is used, the choice of kernel becomes important. The question of an optimal kernel is important and unsolved in machine learning [52,53,54]. Our framework for estimating drift provides a more objective setting for this question.
Out-of-sample extensions The technique that we presented provides a robust estimation technique for the drift. The reason it is well suited to a general nonlinear and data-driven technique is the use of kernel methods. The downside of kernel methods is the difficulty in extending the function beyond the compactly supported dataset. Thus, our technique provides a good phase-portrait, but it may not be reliable as a simulator or alternative model to the true system if the latter is chaotic and high dimensional. The issue of out of sample extensions [55,56] and topological containment [57,58] of simulation models is separate from the preliminary task of estimating the drift. This is yet another important area of development.
The present article reconstructs the drift as a sum of kernel sections, i.e., as a function. Kernel methods are just one of the many ways of representing a function. The next goal is to obtain a different representation that is more suitable for retaining the topology, but still aims to achieve the identity (8). A recent work by the author [59] presents a reconstruction strategy that preserves the topology of the targeted attractor, at the cost of replacing the deterministic dynamics law by a Markov process with arbitrarily low noise. The continuous time analog of this strategy is the idea of combinatorial drifts by Mrozek et al. [60,61]. Another promising technique directed towards preserving the attractor topology is the matrix-based approach [62]. A fourth option is the recent idea of representing vector fields as 1-forms [63]. A combination of any of these topologically motivated techniques, with the statistical methods presented in this article, offers an interesting avenue for further research.
DECLARATIONS
Acknowledgments
The author is grateful to the referees and editors for the detailed comments and reflections on the paper. They helped to improve the paper significantly.
Authors’ contributions
The author contributed solely to the article.
Availability of data and materials
All the raw dataandexperimental datasetsare sample trajectories of SDEs. The trajectoriesare simulated using the SDEProblem feature of DifferentialEquations.jl package in Julia language. The integration technique was the Euler-Maruyama method. The data may be regenerated using the parameters specified in Table 1.
Financial support and sponsorship
None.
Conflicts of interest
The author declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2025.
REFERENCES
1. Sun, J.; Wang, H. Stability analysis for highly nonlinear switched stochastic systems with time-varying delays. Complex. Eng. Syst. 2022, 2, 17.
2. Song, K.; Bonnin, M.; Traversa, F. L.; Bonani, F. Stochastic analysis of a bistable piezoelectric energy harvester with a matched electrical load. Nonlinear. Dyn. 2023, 111, 16991-7005.
3. Zhang, Y.; Duan, J.; Jin, Y.; Li, Y. Discovering governing equation from data for multi-stable energy harvester under white noise. Nonlinear. Dyn. 2021, 106, 2829-40.
4. Neves, W.; Olivera, C. Stochastic transport equations with unbounded divergence. J. Nonlinear. Sci. 2022, 32, 60.
6. Gay-Balmaz, F.; Holm, D. Stochastic geometric models with non-stationary spatial correlations in Lagrangian fluid flows. J. Nonlinear. Sci. 2018, 28, 873-904.
7. Arnold, L. Stochastic differential equations : theory and applications. Wiley Interscience; 1974. Available from: https://cir.nii.ac.jp/crid/1970867909896889156[Last accessed on 24 Oct 2025].
8. Philipp, F. ; Schaller, M. ; Worthmann, K. ; Peitz, S. ; Nüske, F. Error bounds for kernel-based approximations of the Koopman operator; 2023.
9. Doob, J. L. Stochastic processes. Wiley; 1953. Available from: https://www.wiley.com/en-us/Stochastic+Processes-p-9780471523697[Last accessed on 24 Oct 2025].
10. Huang, W.; Ji, M.; Liu, Z.; Yi, Y. Integral identity and measure estimates for stationary Fokker-Planck equations. Ann. Probab. 2015, 43, 1712-30.
11. Harris, T. The existence of stationary measures for certain Markov processes. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability. 1956; pp. 113-24. Available from: https://apps.dtic.mil/sti/html/tr/AD0604937/[Last accessed on 24 Oct 2025].
12. Huang, W.; Ji, M.; Liu, Z.; Yi, Y. Concentration and limit behaviors of stationary measures. Phys. D. 2018, 369, 1-17.
13. Shalizi, C.; Kontorovich, A. Almost none of the theory of stochastic processes. Lecture Notes; 2010. Available from: www.stat.cmu.edu/cshalizi/almost-none/[Last accessed on 24 Oct 2025].
14. Stanton, R. A nonparametric model of term structure dynamics and the market price of interest rate risk. J. Finance. 1997, 52, 1973-2002.
15. Gouesbet, G. Reconstruction of the vector fields of continuous dynamical systems from numerical scalar time series. Phys. Rev. A. 1991, 43, 5321.
16. Tsutsumi, N.; Nakai, K.; Saiki, Y. Constructing differential equations using only a scalar time-series about continuous time chaotic dynamics. Chaos. 2022, 32, 091101.
17. Gouesbet, G.; Letellier, C. Global vector-field reconstruction by using a multivariate polynomial L 2 approximation on nets. Phys. Rev. E. 1994, 49, 4955.
18. Cao, J.; Wang, L.; Xu, J. Robust estimation for ordinary differential equation models. Biometrics. 2011, 67, 1305-13.
19. Aït-Sahalia, Y.; Hansen, L. P.; Scheinkman, J. A. Chapter 1 - Operator methods for continuous-time Markov processes. In: Handbook of financial econometrics: tools and techniques. Elsevier; 2010. pp. 1-66.
20. Garcia, C.; Otero, A.; Félix, P.; Presedo, J.; Márquez, D. G. Nonparametric estimation of stochastic differential equations with sparse Gaussian processes. Phys. Rev. E. 2017, 96, 022104.
21. Devlin, J.; Husmeier, D.; Mackenzie, J. Optimal estimation of drift and diffusion coefficients in the presence of static localization error. Phys. Rev. E. 2019, 100, 022134.
22. Darcy, M.; Hamzi, B.; Livieri, G.; Owhadi, H.; Tavallali, P. One-shot learning of stochastic differential equations with data adapted kernels. Phys. D. 2023, 444, 133583.
23. Batz, P.; Ruttor, A.; Opper, M. Approximate Bayes learning of stochastic differential equations. Phys. Rev. E. 2018, 98, 022109.
24. Ruttor, A.; Batz, P.; Opper, M. Approximate Gaussian process inference for the drift of stochastic differential equations. 2013; Available from: https://proceedings.neurips.cc/paper_files/paper/2013/file/021bbc7ee20b71134d53e20206bd6feb-Paper.pdf[Last accessed on 24 Oct 2025].
25. Ella-Mintsa, E. Nonparametric estimation of the diffusion coefficient from i.i.d. S.D.E. paths. Stat. Inference. Stoch. Process. 2024, 27, 585.
26. Davis, W.; Buffett, B. Estimation of drift and diffusion functions from unevenly sampled time-series data. Phys. Rev. E. 2022, 106, 014140.
27. Ye, F.; Yang, S.; Maggioni, M. Nonlinear model reduction for slow-fast stochastic systems near unknown invariant manifolds. J. Nonlinear. Sci. 2024, 34, 22.
28. Wang, Z.; Ma, Q.; Yao, Z.; Ding, X. The magnus expansion for stochastic differential equations. J. Nonlinear. Sci. 2020, 30, 419-47.
29. Yin, X.; Zhang, Q. Backstepping-based state estimation for a class of stochastic nonlinear systems. Complex. Eng. Syst. 2022, 2, 1.
30. Das, S. Conditional expectation using compactification operators. Appl. Comput. Harmon. Anal. 2024, 71, 101638.
31. Das, S.; Giannakis, D. Delay-coordinate maps and the spectra of Koopman operators. J. Stat. Phys. 2019, 175, 1107-45.
32. Das, S.; Giannakis, D. Koopman spectra in reproducing kernel Hilbert spaces. Appl. Comput. Harmon. Anal. 2020, 49, 573-607.
33. Das, S.; Mustavee, S.; Agarwal, S. Data-driven discovery of quasiperiodically driven dynamics. Nonlinear. Dyn. 2025, 113, 4097.
34. Das, S.; Mustavee, S.; Agarwal, S.; Hassan, S. Koopman-theoretic modeling of quasiperiodically driven systems: example of signalized traffic corridor. IEEE. Trans. Syst. Man. Cyber. Syst. 2023, 53, 4466-76.
35. Giannakis, D.; Das, S.; Slawinska, J. Reproducing kernel Hilbert space compactification of unitary evolution groups. Appl. Comput. Harmon. Anal. 2021, 54, 75-136.
36. Marshall, A.; Olkin, I. Multivariate chebyshev inequalities. Anna. Math. Stat. 1960, 31, 1001-14.
37. Lorenz, E. Atmospheric predictability as revealed by naturally occurring analogues. J. Atmos. Sci. 1969, 26, 636-46.
38. Strogatz, S. Nonlinear dynamics and chaos with applications to physics, biology, chemistry, and engineering, 2nd ed.; CRC Press, 2015.
39. Lorenz, E.; Emanuel, K. Optimal sites for supplementary weather observations: simulation with a small model. J. Atmos. Sci. 1998, 55, 399-414.
40. Marshall, N.; Coifman, R. Manifold learning with bi-stochastic kernels. IMA. J. Appl. Math. 2019, 84, 455-82.
41. Wormell, C. L.; Reich, S. Spectral convergence of diffusion maps: Improved error bounds and an alternative normalization. SIAM. J. Numer. Anal. 2021, 59, 1687-734.
43. Hein, M.; Audibert, J. Y.; von Luxburg, U. From graphs to manifolds-weak and strong pointwise consistency of graph Laplacians. In: International Conference on Computational Learning Theory. Springer; 2005. pp. 470-85.
44. Vaughn, R.; Berry, T.; Antil, H. Diffusion maps for embedded manifolds with boundary with applications to PDEs. Appl. Comput. Harmonic. Anal. 2024, 68, 101593.
45. Berry, T.; Das, S. Learning theory for dynamical systems. SIAM. J. Appl. Dyn. 2023, 22, 2082-122.
47. Wang, S.; Blanchet, J.; Glynn, P. An efficient high-dimensional gradient estimator for stochastic differential equations. Adv. Neural. Inf. Proc. Syst. 2024, 37, 88045.
48. Chen, D.; Chen, J.; Zhang, X.; et al. Critical nodes identification in complex networks: a survey. Complex. Eng. Syst. 2025, 5, 11.
50. Guan, Y.; Subel, A.; Chattopadhyay, A.; Hassanzadeh, P. Learning physics-constrained subgrid-scale closures in the small-data regime for stable and accurate LES. Phys. D. 2023, 443, 133568.
51. Boutros, D.; Titi, E. Onsager's conjecture for subgrid scale α-models of turbulence. Phys. D. 2023, 443, 133553.
52. Narayan, A.; Yan, L.; Zhou, T. Optimal design for kernel interpolation: applications to uncertainty quantification. J. Comput. Phys. 2021, 430, 110094.
53. Baraniuk, R.; Jones, D. A signal-dependent time-frequency representation: optimal kernel design. IEEE. Trans. Signal. Process. 1993, 41, 1589-602.
54. Crammer, K.; Keshet, J.; Singer, Y. Kernel design using boosting. In Part of Advances in Neural Information Processing Systems 15 (NIPS 2002); 2002. Available from: https://papers.nips.cc/paper_files/paper/2002/hash/dd28e50635038e9cf3a648c2dd17ad0a-Abstract.html[Last accessed on 24 Oct 2025].
55. Vural, E.; Guillemot, C. Out-of-sample generalizations for supervised manifold learning for classification. IEEE. Trans. Image. Process. 2016, 25, 1410-24.
56. Pan, B.; Chen, W. S.; Chen, B.; Xu, C.; Lai, J. Out-of-sample extensions for non-parametric kernel methods. IEEE. Trans. Neural. Netw. Learn. Syst. 2016, 28, 334-45.
57. Kaczynski, T.; Mrozek, M.; Wanner, T. Towards aformal tie between combinatorial and classical vector field dynamics. J. Comput. Dyn. 2016, 3, 17-50.
58. Mrozek, M.; Wanner, T. Creating semiflows on simplicial complexes from combinatorial vector fields. J. Dif. Eq. 2021, 304, 375-434.
60. Mrozek, M. Topological invariants, mulitvalued maps and computer assisted proofs in dynamics. Comput. Math. Appl. 1996, 32, 83-104.
61. Mischaikow, K.; Mrozek, M. Isolating neighborhoods and chaos. Japan. J. Ind. Appl. Math. 1995, 12, 205-36.
62. Du, Q.; Yang, H. Computation of robust positively invariant set based on direct data-driven approach. Complex. Eng. Syst. 2024, 4, 24.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Data & Comments
Data
0












Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].