



fig5
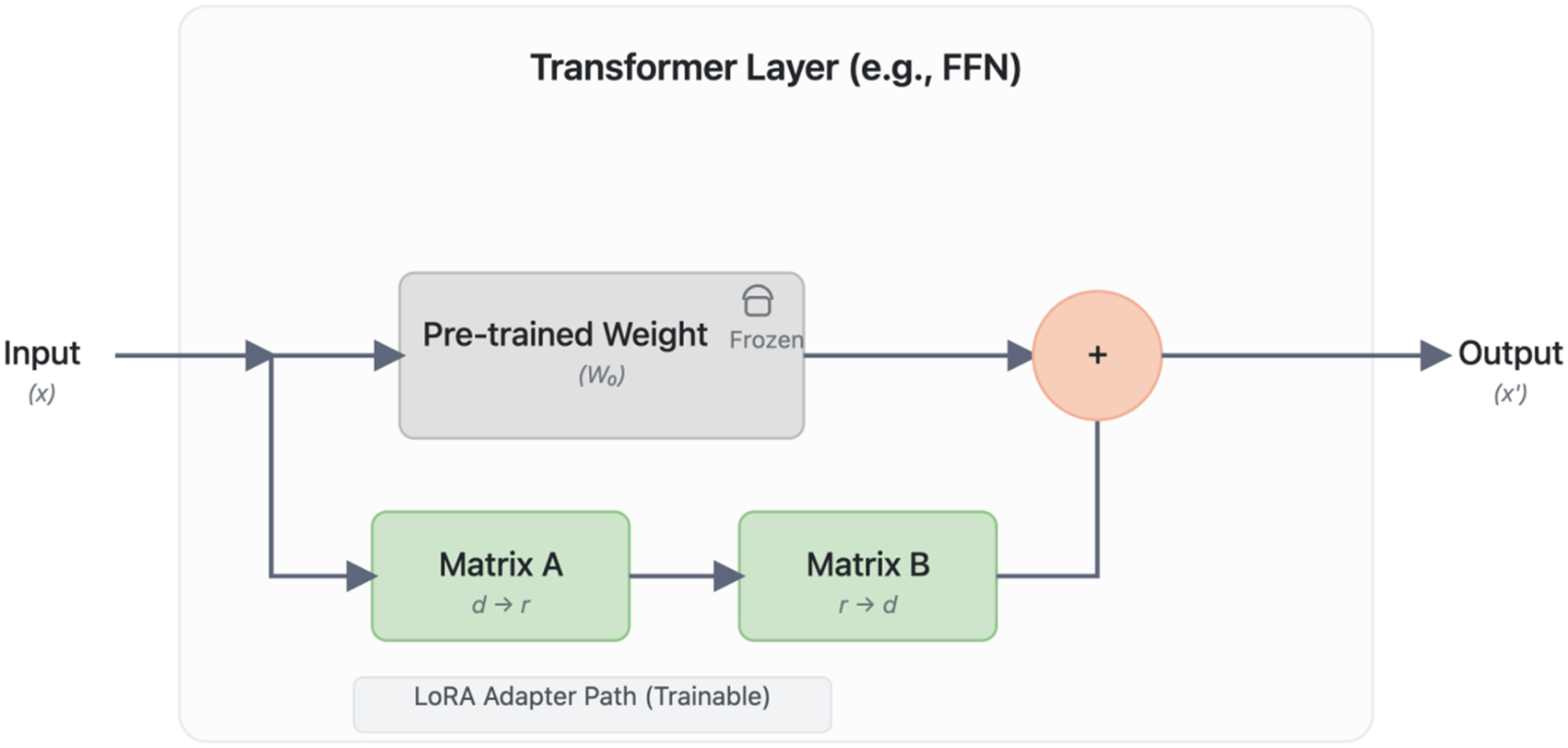
Figure 5. The LoRA (Low-Rank Adaptation) Fine-tuning Architecture. The diagram illustrates how LoRA efficiently adapts a pre-trained Transformer layer. The main data path (top) processes the input ‘(x)’ through the original, frozen pre-trained weights (‘W’), preserving foundational knowledge. In parallel, a trainable adapter path (bottom) is injected, consisting of a rank-decomposition operation with two low-rank matrices, ‘A’ (rank reduction, d → r) and ‘B’ (rank expansion, r → d). The outputs from both paths are aggregated through element-wise addition to produce the final output ‘(x’)’. This design drastically reduces the number of trainable parameters, enabling efficient specialization of large models with minimal computational overhead. FFN: Feed-forward neural network.




