



fig2
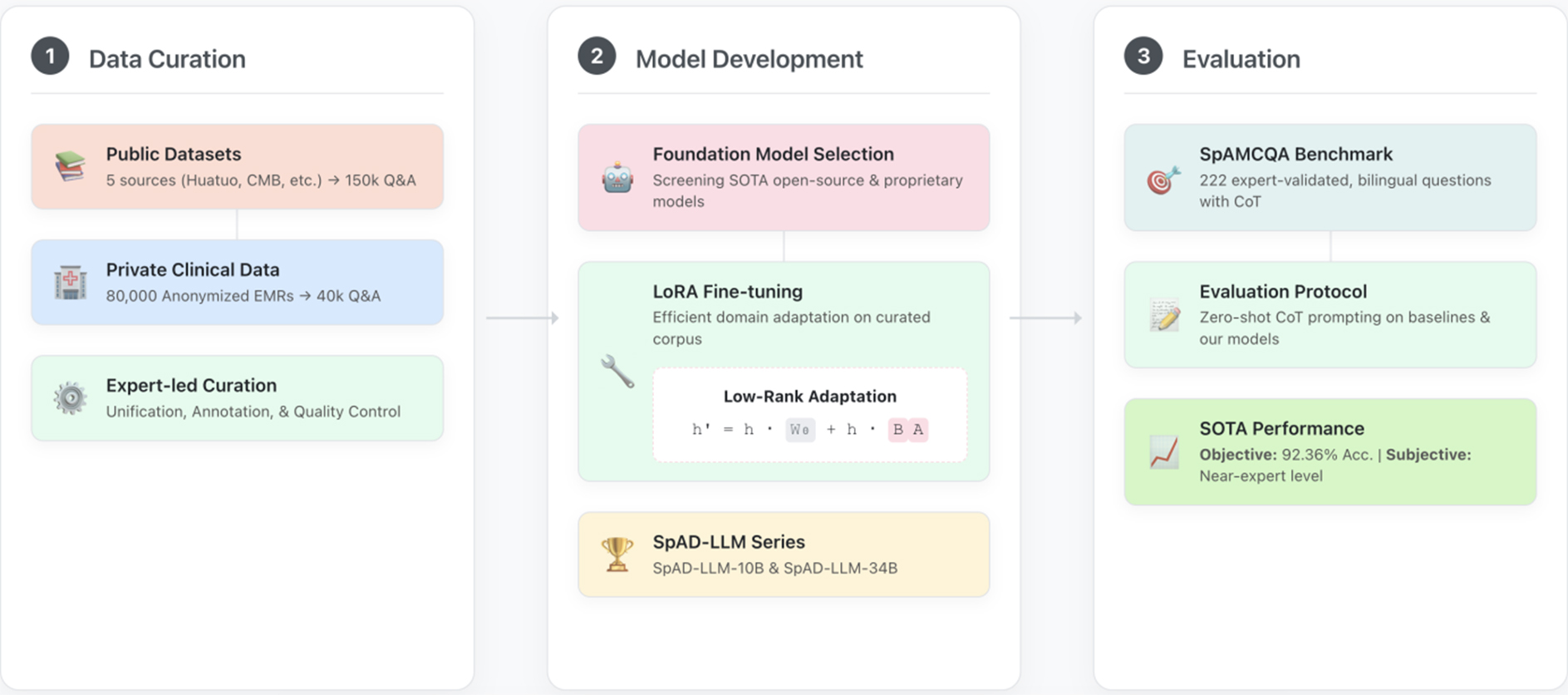
Figure 2. The end-to-end workflow for developing and evaluating SpAD-LLM. The process is structured into three main stages. (1) Data Curation: We compile a comprehensive fine-tuning corpus by integrating large-scale public medical datasets with a private, expert-annotated dataset derived from 80,000 anonymized electronic medical records (EMRs). This curated corpus contains 150,000 general medical Q&A pairs and 40,000 high-quality Q&A pairs specific to spondyloarthritis (SpA); (2) Model Development: We select promising foundation models from both public and proprietary sources. These models are then efficiently adapted to the rheumatology domain using Low-Rank Adaptation (LoRA) on the curated dataset, resulting in our specialized SpAD-LLM series; (3) Evaluation: The performance of the SpAD-LLM series and baseline models (e.g., GPT-4) is rigorously assessed on our novel SpAMCQA benchmark using a zero-shot Chain-of-Thought (CoT) prompting strategy. The evaluation combines objective metrics (accuracy) and subjective scores from clinical experts to provide a holistic measure of diagnostic reasoning capability. SpAD-LLM: Spondyloarthritis Diagnosis Large Language Model; SpAMCQA: Spondyloarthritis Multiple-Choice Question Answering Benchmark; CMB: Comprehensive Medical Benchmark.




