



fig1
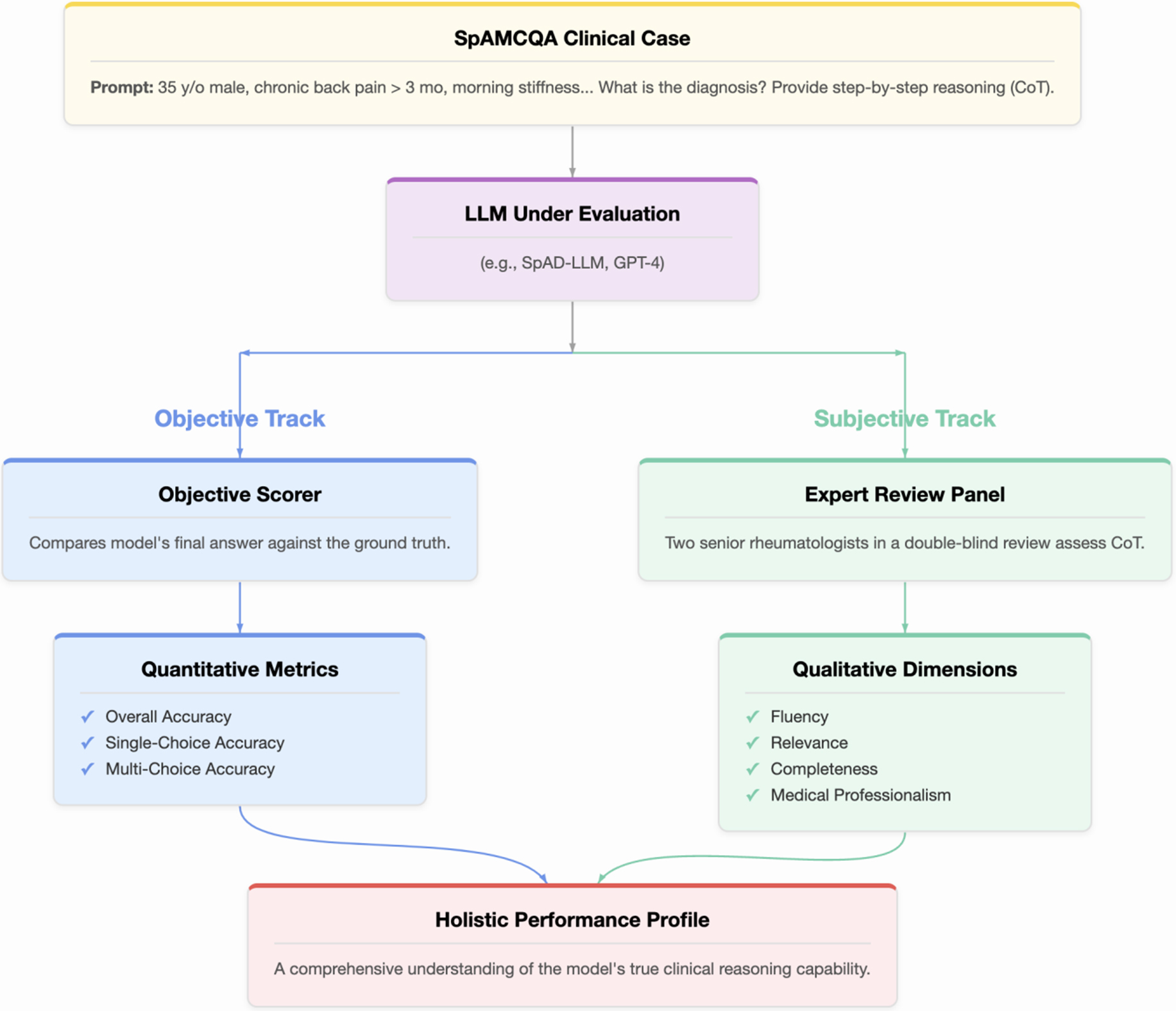
Figure 1. The SpAMCQA evaluation framework. A clinical case from the benchmark is presented to the Large Language Model (LLM) using a zero-shot Chain-of-Thought (CoT) prompt. The model’s performance is then assessed through two parallel tracks. The Objective Track (blue pathway) automatically scores the final answer for quantitative accuracy. Concurrently, the Subjective Track (green pathway) involves a double-blind review by two senior rheumatologists who evaluate the quality of the CoT reasoning process across four dimensions: Fluency, Relevance, Completeness, and Medical Professionalism. This dual-pronged approach yields a Holistic Performance Profile, providing a comprehensive and rigorous measure of the LLM’s clinical reasoning capabilities. SpAMCQA: Spondyloarthritis Multiple-Choice Question Answering Benchmark.




