

Figure2
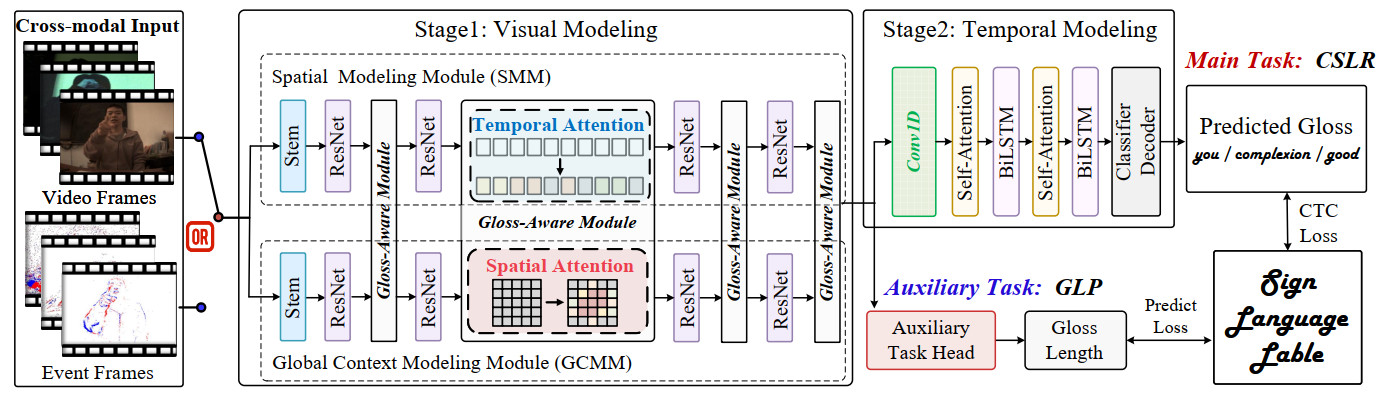
Figure 2. An overview of the proposed GANet. GANet processes multi-modal inputs (RGB or event-based data). It extracts features through a two-stage network and ultimately predicts the gloss sequence and its length. Additionally, an auxiliary task is designed to explicitly guide the network in learning global contextual information. The data used in this figure is obtained from the EvCSLR open-source dataset, which is available at https://github.com/diamondxx/EvCSLR.




