



Exploring chatbot applications in pancreatic disease treatment: potential and pitfalls
 0
0 Abstract
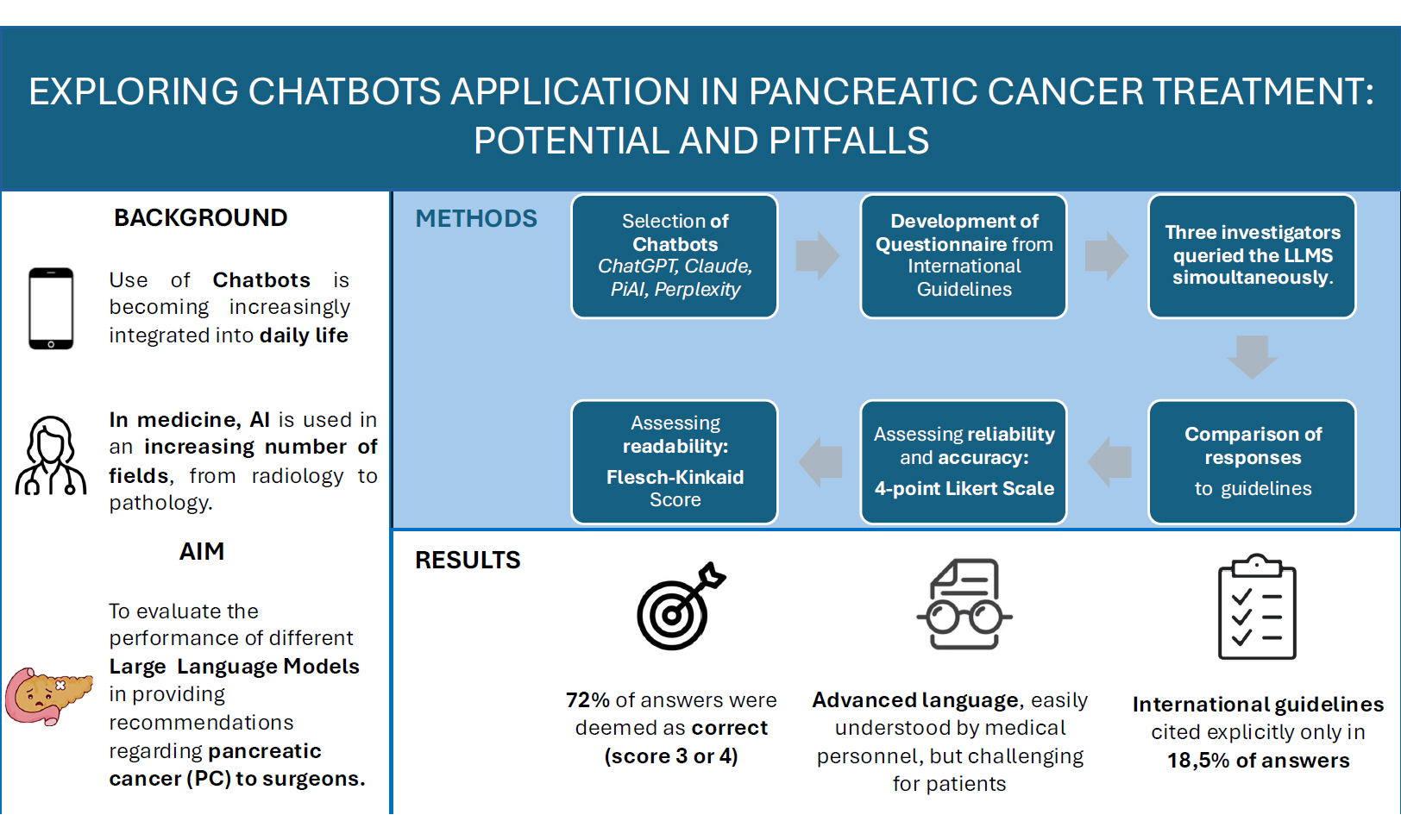
Aim: The use of chatbots to respond across various domains is becoming more integrated into daily life, potentially replacing traditional search engines. The study aimed to investigate the performance of different large language models (LLMs) in providing recommendations regarding pancreatic cancer (PC) to surgeons.
Methods: Standardized prompts were engineered to query four freely accessible LLMs (ChatGPT-4, Personal Intelligence by Inflection AI, Anthropic Claude 3 Haiku Version 3.5, Perplexity AI) on October 9th, 2024. Fourteen questions included the incidence, diagnosis, and treatment for radiologically resectable, borderline resectable, locally advanced, and metastatic PC. Three different investigators queried the LLMS simultaneously. The reliability and accuracy of the responses were evaluated using a 4-point Likert scale and then compared to the international guidelines. Descriptive statistics were used to report outcomes as counts and percentages.
Results: Overall, 72% of the responses were deemed correct (scored 3 or 4). Claude provided the most accurate responses (32%), followed by ChatGPT (28%). ChatGPT-4 and Anthropic Claude 3 Haiku Version 3.5 achieved the overall highest score rate (4-point) at 50% and 52%, respectively. Regarding the quality and accuracy of the responses, ChatGPT cited guidelines most frequently (29%). However, only 19% of all evaluated responses included guideline citations.
Conclusion: The LLMs are still not suitable for safe, standalone use in the medical field, but their rapid learning capabilities suggest they may become indispensable tools for medical professionals in the future.
Keywords
INTRODUCTION
Over recent decades, advancements in artificial intelligence (AI) have revolutionized various domains, including the development of conversational agents known as chatbots. These systems utilize AI and natural language processing (NLP) to interpret user queries and generate automated responses, mimicking human dialogue[1]. Chatbots are primarily built on two components: a general-purpose AI framework and a user-friendly chat interface[2]. By leveraging large language models (LLMs), chatbots demonstrate conversational reasoning, producing contextually appropriate responses[3].
The public release of Chat Generative Pretrained Transformer (ChatGPT) in November 2022 marked a significant milestone, accelerating the proliferation of similar AI-driven tools across industries[4]. However, most LLMs, including ChatGPT, are trained predominantly on non-medical datasets[5].
This limitation has sparked widespread discussions regarding the use of such tools in sensitive fields such as medicine, raising ethical concerns about bias reinforcement, potential plagiarism, misinformation, and the reliability of AI-generated content[6,7].
Despite these challenges, researchers have begun investigating the quality and reliability of chatbot-generated medical information[8]. Preliminary studies have compared the accuracy and readability of responses from various chatbots across general medical topics and specific specialties[9].
Recent efforts include evaluations of chatbots’ performance on topics such as cancer care, ophthalmology, and other specialized domains[10-14].
Despite extensive research on AI-generated information in medical fields, there is a lack of data evaluating the performance of Large Language Models (LLMs) specifically addressing pancreatic cancer treatment. Pancreatic cancer is burdened by a poor prognosis related to the almost always advanced stage of the disease at diagnosis. The chances of cure are primarily linked to the timeliness of surgical intervention - which is, however, associated with a high morbidity rate - and to perioperative chemotherapy, whose protocols are continuously evolving due to advances in oncological research. This underscores the importance of strictly adhering to clinical guidelines to ensure that each patient receives the best possible access to treatment[15]. This study aims to bridge that gap by evaluating the accuracy and reliability of chatbot-generated information on pancreatic cancer, comparing multiple LLMs under standardized clinical conditions. Specifically, we analyzed chatbot responses to queries posed by specialized clinicians on topics including risk factors, diagnosis, and management of resectable, borderline resectable, locally advanced, and metastatic pancreatic cancer. Our primary objectives were to assess the accuracy of AI-provided medical information, evaluate its concordance with international guidelines, and determine the comprehensiveness of the content delivered.
MATERIALS AND METHODS
LLM selection and objectives
The study team selected four free online chatbots (ChatGPT-4, Personal Intelligence by Inflection AI, Anthropic Claude 3 Haiku Version 3.5, Perplexity AI) based on their widespread usage among the general population and the experience of the surgeons involved in the study.
To reflect real-world clinical practice, we included one paid version of ChatGPT and compared it with the other two free versions. All three versions used the same underlying large language model (GPT-4). The primary objective of the study was to determine the accuracy of chatbots in providing clinicians with recommendations on pancreatic cancer diagnosis and treatments. This was achieved by querying the four chatbots and comparing the responses to the guidelines. To minimize the risk of confusion arising from the vast body of literature on pancreatic cancer, we chose to compare chatbot responses exclusively with the most recently published clinical guidelines, from which the questions were derived.
Ethical approval was not required for this study as it involved non-sensitive survey responses, in line with the Verona Pancreas Institute's ethical policy.
Questionnaire selection & testing
A panel of pancreatic surgeons meticulously developed the questionnaire. The questionnaire consisted of 14 questions evenly distributed across seven topics: epidemiology (n = 2), diagnosis (n = 2), treatment options for radiologically resectable disease (n = 2), borderline resectable disease (n = 2), locally advanced disease (n = 2), metastatic pancreatic cancer (n = 2), and best supportive care (n = 2) [Figure 1]. The process began with a thorough review of the most widely used clinical guidelines for pancreatic cancer:
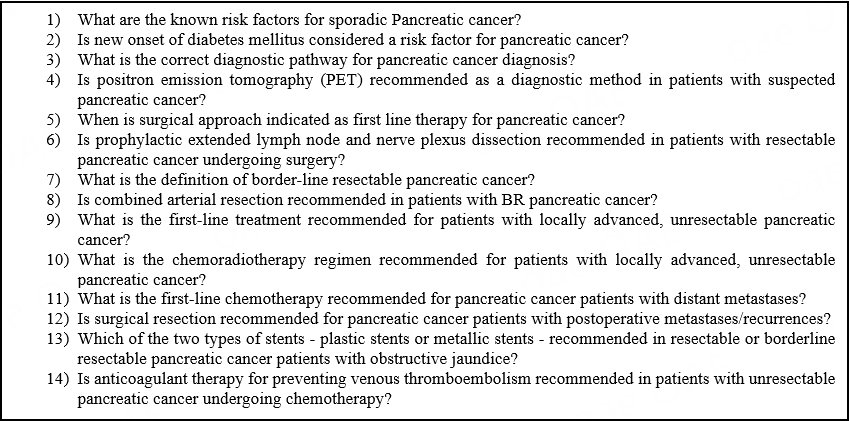
Figure 1. Questionnaire performed by chatbots.
(1) Clinical Practice Guidelines in Oncology (NCCN guidelines®) for Pancreatic Adenocarcinoma[16].
(2) ESMO Clinical Practice Guideline for diagnosis, treatment, and follow-up for pancreatic cancer[17].
(3) Pancreatic cancer in adults: diagnosis and management from the National Institute for Health and Care Excellence[18].
(4) Clinical Practice Guidelines for Pancreatic Cancer 2022 from the Japan Pancreas Society: a synopsis[19].
Each question was derived directly from the clinical guidelines, and phrased using conventional medical terminology appropriate for a surgeon. Before querying, all chatbots were given the same introductory prompt: “I am a pancreatic surgeon, and I’d like to know more about pancreatic cancer”. This was designed to stimulate the perspective of a specialist and trigger the chatbot to provide a precise recommendation rather than generic or broad information related to pancreatic cancer. Follow-up prompts were not used.
Query strategy
ChatGPT-4, Personal Intelligence by Inflection AI, Anthropic Claude 3 Haiku Version 3.5, and Perplexity AI were queried on October 9th, 2024, by three study authors.
These co-investigators performed the queries in Verona, Italy. Each AI chatbot was queried through its respective user interface. The questions were posed simultaneously under identical conditions to ensure comparability of the data collected. Outputs along with their citations were extracted without modification. We did not make post-hoc changes to study prompts. The study team queried the chatbots in English.
Performance evaluation
The study team applied a standardized data collection form to collate response data [Supplementary Materials]. We defined accurate performance by the LLM as alignment with clinical practice guideline recommendations. When a response contained a guideline citation, its accuracy was verified against the most recent version of the respective guideline. When there was no clear reference to guidelines, the response was assessed based on the normal clinical practice of the reference Pancreatic Institute (Verona, Italy). The quality and accuracy of each response were evaluated using a composite measure of factual correctness, guideline adherence, and comprehensiveness, as determined by a four-point Likert scale, scoring as follows: (4) correct and comprehensive; (3) correct but not comprehensive; (2) some correct with disinformation; and (1) completely incorrect. Two general surgery residents independently scored the responses. In cases of disagreement, a third senior reviewer served as an adjudicator to reach a consensus. After the initial evaluation of the responses, the two team members jointly re-evaluated each response and provided an overall score. The consistency of chatbot responses to identical questions was evaluated to assess variability. Responses that received a score of 3 or 4 were considered correct. Responses were considered misaligned with society guidelines if they conflicted with recommendations or failed to provide meaningful answers.
The Flesch-Kincaid reading grade level score was used to assess readability. Notably, the National Institutes of Health recommends an eighth-grade reading level for materials intended for the general population[20].
Statistical analysis
Descriptive statistics were performed. One member of the study team performed data analysis using descriptive statistics to report dichotomous outcomes, including counts and percentages. The statistical analysis was performed using the statistical software Jamovi (Version 2.6, 2024) and GraphPad Prism 10 (San Diego, USA). ANOVA identified differences in rater evaluation and readability, with significance determined at P < 0.05. To assess the reliability of the scoring system, we calculated the inter-rater agreement between the two surgical residents using Cohen’s Kappa. Data are presented as mean and standard deviation. The chatbot Assessment Reporting Tool is currently under development[21].
RESULTS
A total of 168 questions were posed to the chatbots. All chatbots answered every question.
Inter-rater agreement in the Likert-scale ratings was substantial, with a Cohen’s kappa of 0.659 (Z = 12.5, P < 0.001), and a simple percentage agreement of 76.8%, indicating a high degree of consistency between the two evaluators.
Table 1 summarizes the distribution of correct answers, with 71.5% of responses scored as either 3 or 4. The most accurate chatbot was Anthropic Claude 3 Haiku Version 3.5, which provided 38/120 (31.6%) correct answers, followed by ChatGPT-4 with 33/120 (27.5%). Of the 54 answers receiving the highest score of 4, Anthropic Claude 3 Haiku Version 3.5 provided the majority (22/54, 40.7%), followed closely by ChatGPT-4 (21/54, 38.9%).
Distribution of correct answers in the four chatbots
| chatGPT | Claude | PiAI | Perplexity | All 4 | |
| Likert score 4 | 21 | 22 | 0 | 11 | 54 |
| Total answers | 42 | 42 | 42 | 42 | 168 |
| % | 50 | 52.3809524 | 0 | 26.1904762 | 32 |
| Likert score 3 + 4 | 33 | 38 | 23 | 26 | 120 |
| Total answers | 42 | 42 | 42 | 42 | 168 |
| % | 78.5714286 | 90.4761905 | 54.7619048 | 61.9047619 | 71.50 |
Table 2 highlights the best of the three answers to each question. ChatGPT-4 achieved the highest number of correct and comprehensive responses (11/14, 78.6%), followed by Anthropic Claude 3 Haiku Version 3.5 (10/14, 71.4%) and Perplexity AI (6/14, 42.9%). However, ChatGPT-4 exhibited the greatest variability in responses, with 10/14 (71.4%) answers rated inconsistently by evaluators. Surgical treatment options and systemic therapies received the lowest average scores, with most responses scoring below 3. ChatGPT-4 produced the longest responses on average, while Anthropic Claude 3 Haiku Version 3.5 offered the highest proportion of precise recommendations.
Distribution of correct answers when considering only the best of three answers
| chatGPT | Claude | piAI | Perplexity | |
| Likert score 4 | 11 | 10 | 0 | 6 |
| tot | 14 | 14 | 14 | 14 |
| % | 78.57143 | 71.42857 | 0 | 42.85714 |
ChatGPT-4 provided the highest number of guideline-cited answers (12/42, 28.6%), followed by Anthropic Claude 3 Haiku Version 3.5 (10/42, 23.8%) and Personal Intelligence by Inflection AI (7/42, 16.7%). Overall, only 18.5% of responses referenced guidelines, indicating room for improvement in evidence-based citations.
All LLMs delivered responses exceeding the Flesch-Kincaid reading level of 6 recommended by the National Institute of Health (NIH) and the average American reading level of 8[22]. The reading levels of the LLMs’ answers ranged from 9,4 (Claude, most accessible) to 20 (PiAI, least accessible). On average, all four LLMs demonstrated an average reading score exceeding 12, indicative of advanced (college-level) reading proficiency. The most accessible LLM was Perplexity (Flesch-Kinkaid grade level 12,3), while the least accessible was PIAI (15,6, P < 0,007) [Table 3].
Measure of accuracy and readability of each LLM. Flesch-Kincaid scores represent readability. “References produced by search” quantifies the number of references cited in the average output for each model
DISCUSSION
The rapid adoption of chatbots worldwide has positioned them as potentially transformative tools across various domains, including medicine. Their user-friendly interfaces and ability to synthesize vast amounts of knowledge have generated significant interest in their application for research and clinical decision making. However, as their role in healthcare expands, concerns about their accuracy, reliability, and safety become increasingly pertinent. This study aimed to evaluate the safety and reliability of chatbot-generated responses in addressing pancreatic cancer, a highly specialized and critical medical field.
Consistent with prior research, our findings indicate that although chatbots frequently provide accurate and reliable responses, a significant proportion of their outputs remain incomplete or inaccurate. The apparent discrepancy between the overall correctness rate (71.5%) and the distribution of errors across individual LLMs reflects the substantial variability in performance among different models. While some LLMs demonstrated relatively high accuracy, others generated a markedly higher number of incorrect or incomplete responses. These limitations render chatbots unsuitable for independent medical consultation without expert oversight. For example, our results are consistent with those of Hermann et al., who demonstrated ChatGPT's ability to accurately discuss cervical cancer prevention but highlighted shortcomings in areas requiring nuanced understanding, such as diagnosis and treatment[23]. Similar trends have been observed in other medical specialties, including head and neck surgery, bariatric surgery, and oncology, further underscoring the variability in chatbot performance across different domains[24-26].
A notable observation in this study was the variability in chatbot responses, even when identical queries were posed. This inconsistency was particularly evident in ChatGPT, likely due to differences in the specific versions used. Although all researchers employed the same underlying model (LLM Model 4), disparities were observed between the paid version, the free 4.0 version, and the free 4.0 Mini version. The paid version consistently outperformed its free counterparts, providing superior responses in 10 out of 14 cases. However, overlapping response quality occurred in 8 of these cases, demonstrating that free versions occasionally match the performance of paid versions in certain contexts. The decision to include both the free and paid versions of ChatGPT was made to reflect real-world usage scenarios, where clinicians may access different platforms with varying levels of availability and performance. For this reason, the analysis was not restricted to the most advanced version of a single model, nor was it standardized based on subscription level. The readability scores highlighted that LLMs use advanced language, well above the comprehension level of the general population. In this context, the responses may be easily understood by medical personnel, such as the pancreatic surgeons asking the questions, but could be challenging for patients seeking information about pancreatic cancer. The complexity of the language may, however, be influenced by the initial context, as the chatbot was consistently informed at the start of the questionnaire that the user was a pancreatic surgeon. Therefore, further evaluations are needed to assess the feasibility of using chatbots as an information source for the general population.
Another key finding was the inconsistency in the sources utilized by chatbots. Despite having access to publicly available guidelines, such data was incorporated in only 18.5% of responses. Another critical finding was the inconsistency in the sources utilized by chatbots. Despite having access to publicly available guidelines, such sources were explicitly referenced in only 18.5% of responses. Moreover, chatbots occasionally incorporate information from less authoritative platforms, such as patient blogs or general online content, which lack the rigor of peer-reviewed scientific literature. This limitation underscores a key challenge for current-generation LLMs: their inability to transparently assess or prioritize the reliability of their training data. Such shortcomings raise concerns about their suitability for specialized medical applications, where adherence to evidence-based guidelines and credible sources is paramount[27].
Previous studies have documented inaccuracies and fabrications in chatbot-generated responses, a phenomenon referred to as “hallucination”[28]. This issue arises when chatbots generate plausible-sounding but factually incorrect responses, making errors less apparent to users. Our study found this issue to be more pronounced in responses to highly specialized queries, where chatbots deviated from established guidelines and relied on less authoritative sources. These compromises in source selection and accuracy can pose significant risks, particularly in high-stakes fields like oncology care. In clinical settings, such errors could lead to misinformation with serious consequences. Therefore, we suggest future work should focus on domain-specific fine-tuning and integration with up-to-date clinical databases to mitigate hallucination risk.
Our findings emphasize the need for caution in integrating chatbots into clinical practice. While the potential of these tools to revolutionize healthcare is undeniable, substantial advancements are required to ensure their safety and reliability. At present, chatbot responses are useful for providing a general and superficial overview of a scientific topic, but they are not yet sufficiently trained to deliver in-depth answers to precise or highly specific questions. Training LLMs with domain-specific datasets curated by medical experts could significantly enhance their performance and address existing limitations. Although current LLMs are not yet ready for autonomous clinical decision making, they could be integrated as decision-support tools. With expert oversight, these systems might assist in synthesizing clinical data, guiding diagnostic pathways, and recommending treatment strategies according to the most updated guidelines and resources. Such improvements would enable chatbots to serve as valuable tools for disseminating medical knowledge, supporting healthcare professionals, and enhancing patient education[20]. Soon, LLMs might play a crucial role in enhancing, rather than replacing, the clinician’s expertise[29]. In any case, especially in light of the results obtained in the present study, it is mandatory to use chatbots with a critical perspective - avoiding the assumption that their answers are definitive truths, and instead placing them within a broader context of research, guidelines evaluation, and the latest scientific evidence.
This study is not without limitations. First, inter-reviewer variability may have influenced the evaluation of chatbot responses, as subjective judgment was inherent to the assessment process. Second, in prompting, different user identities (e.g., general physicians or patients) might elicit different responses that would benefit from further research. Furthermore, we employed standardized and concise questions, without resorting to advanced prompt engineering techniques. It is plausible that the use of more elaborate prompts could have improved the quality and completeness of the responses. We also did not explore multi-turn interactions or follow-up questioning, which may positively influence the accuracy and clinical usefulness of chatbot outputs. We believe that, to ensure the safe use of chatbots in the medical field, the initial response should already be accurate and based on reliable sources, without the need for repeated prompting to obtain an acceptable answer. Third, given the qualitative variability of chatbot outputs, we opted for a descriptive approach to provide a preliminary overview of performance differences. Fourth, the main use of free chatbot versions, which are known to have reduced data processing capabilities compared to paid versions, may have impacted our findings. Future research should include a broader range of chatbot models and focus on developing objective evaluation criteria to provide more robust and reproducible insights.
While the rapid evolution of artificial intelligence presents exciting possibilities for healthcare, our findings underscore the need for continued scrutiny and refinement of chatbot technologies. Ensuring their safety, reliability, and adherence to evidence-based practices is essential before their widespread adoption in clinical settings.
In conclusion, chatbots are emerging as increasingly efficient tools for answering queries rapidly, offering a convenient alternative to the time-consuming process of searching through traditional literature. However, the extensive and often non-curated datasets used by LLMs pose significant risks, as unchecked outputs can lead to misinformation and errors.
The rapid advancements in LLM technology are promising, but their successful integration into clinical practice will require significant improvements in reliability, transparency, and adherence to evidence-based guidelines. If these challenges are addressed, LLMs could transform from supplementary tools into essential assets in the surgical field.
DECLARATIONS
Authors’ contributions
Conceptualization & Methodology: Balduzzi A, De Pastena M
Statistical analysis: Tondato S
Writing - original draft: Tondato S, Gronchi F
Writing - review & editing: Balduzzi A, De Pastena M, Tondato S, Gronchi F, Dall’Olio T, Malleo G, Pea A, Paiella S, Salvia R
Availability of data and materials
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request.
Financial support and sponsorship
The research was funded by the European Union – NextGenerationEU, through the Italian Ministry of University and Research under the PNRR - M4C2-I1.3 Project PE 00000019 “HEAL ITALIA” (CUP B33C22001030006). The views and opinions expressed are solely those of the authors and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the European Commission can be held responsible for them.
Conflicts of interest
The authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Ethical approval was not required for this study as it involved non-sensitive survey responses, in line with the Verona Pancreas Institute’s ethical policy.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2025.
Supplementary Materials
REFERENCES
1. Roumeliotis KI, Tselikas ND. ChatGPT and Open-AI models: a preliminary review. Future Internet. 2023;15:192.
2. Lee P, Bubeck S, Petro J. Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine. N Engl J Med. 2023;388:1233-9.
3. Olszewski R, Watros K, Mańczak M, Owoc J, Jeziorski K, Brzeziński J. Assessing the response quality and readability of chatbots in cardiovascular health, oncology, and psoriasis: a comparative study. Int J Med Inform. 2024;190:105562.
4. Nirala KK, Singh NK, Purani VS. A survey on providing customer and public administration based services using AI: chatbot. Multimed Tools Appl. 2022;81:22215-46.
5. Gallifant J, Fiske A, Levites Strekalova YA, et al. Peer review of GPT-4 technical report and systems card. PLOS Digit Health. 2024;3:e0000417.
6. Liebrenz M, Schleifer R, Buadze A, Bhugra D, Smith A. Generating scholarly content with ChatGPT: ethical challenges for medical publishing. Lancet Digit Health. 2023;5:e105-6.
8. Haug CJ, Drazen JM. Artificial intelligence and machine learning in clinical medicine, 2023. N Engl J Med. 2023;388:1201-8.
9. Wagner MW, Ertl-Wagner BB. Accuracy of information and references using ChatGPT-3 for retrieval of clinical radiological information. Can Assoc Radiol J. 2024;75:69-73.
10. Walker HL, Ghani S, Kuemmerli C, et al. Reliability of medical information provided by ChatGPT: assessment against clinical guidelines and patient information quality instrument. J Med Internet Res. 2023;25:e47479.
11. Johnson D, Goodman R, Patrinely J, et al. Assessing the accuracy and reliability of AI-generated medical responses: an evaluation of the Chat-GPT model. Res Sq. ;2023:rs.
12. Lee JW, Yoo IS, Kim JH, et al. Development of AI-generated medical responses using the ChatGPT for cancer patients. Comput Methods Programs Biomed. 2024;254:108302.
13. Emile SH, Horesh N, Freund M, et al. How appropriate are answers of online chat-based artificial intelligence (ChatGPT) to common questions on colon cancer? Surgery. 2023;174:1273-5.
14. Mihalache A, Popovic MM, Muni RH. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 2023;141:589-97.
15. Mackay TM, Latenstein AEJ, Augustinus S, et al; Dutch Pancreatic Cancer Group. Implementation of best practices in pancreatic cancer care in the Netherlands: a stepped-wedge randomized clinical trial. JAMA Surg. 2024;159:429-37.
16. NCCN Clinical Practice Guidelines in Oncology (NCCN Guidelines®) Pancreatic Adenocarcinoma version 3.2024. Available from: https://www.nccn.org/guidelines/guidelines-detail?category=1&id=1455 (accessed on 2025-7-30).
17. Conroy T, Pfeiffer P, Vilgrain V, et al; ESMO Guidelines Committee. Electronic address: [email protected]. Pancreatic cancer: ESMO clinical practice guideline for diagnosis, treatment and follow-up. Ann Oncol. 2023;34:987-1002.
18. O’Reilly D, Fou L, Hasler E, et al. Diagnosis and management of pancreatic cancer in adults: A summary of guidelines from the UK National Institute for Health and Care Excellence. Pancreatology. 2018;18:962-70.
19. Okusaka T, Nakamura M, Yoshida M, et al; Committee for Revision of Clinical Guidelines for Pancreatic Cancer of the Japan Pancreas Society. Clinical practice guidelines for pancreatic cancer 2022 from the Japan pancreas society: a synopsis. Int J Clin Oncol. 2023;28:493-511.
20. Rooney MK, Santiago G, Perni S, et al. Readability of patient education materials from high-impact medical journals: a 20-year analysis. J Patient Exp. 2021;8:2374373521998847.
21. Huo B, Cacciamani GE, Collins GS, McKechnie T, Lee Y, Guyatt G. Reporting standards for the use of large language model-linked chatbots for health advice. Nat Med. 2023;29:2988.
22. Cotugna N, Vickery CE, Carpenter-Haefele KM. Evaluation of literacy level of patient education pages in health-related journals. J Community Health. 2005;30:213-9.
23. Hermann CE, Patel JM, Boyd L, Growdon WB, Aviki E, Stasenko M. Let’s chat about cervical cancer: assessing the accuracy of ChatGPT responses to cervical cancer questions. Gynecol Oncol. 2023;179:164-8.
24. Lee Y, Tessier L, Brar K, et al; ASMBS Artificial Intelligence and Digital Surgery Taskforce. Performance of artificial intelligence in bariatric surgery: comparative analysis of ChatGPT-4, Bing, and Bard in the American society for metabolic and bariatric surgery textbook of bariatric surgery questions. Surg Obes Relat Dis. 2024;20:609-13.
25. Carl N, Schramm F, Haggenmüller S, et al. Large language model use in clinical oncology. NPJ Precis Oncol. 2024;8:240.
26. Kuşcu O, Pamuk AE, Sütay Süslü N, Hosal S. Is ChatGPT accurate and reliable in answering questions regarding head and neck cancer? Front Oncol. 2023;13:1256459.
27. Goodman RS, Patrinely JR, Stone CA Jr, et al. Accuracy and reliability of chatbot responses to physician questions. JAMA Netw Open. 2023;6:e2336483.
28. Bhattacharyya M, Miller VM, Bhattacharyya D, Miller LE. High rates of fabricated and inaccurate references in ChatGPT-generated medical content. Cureus. 2023;15:e39238.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Special Issue
Copyright

Data & Comments
Data
0











Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].