

fig4
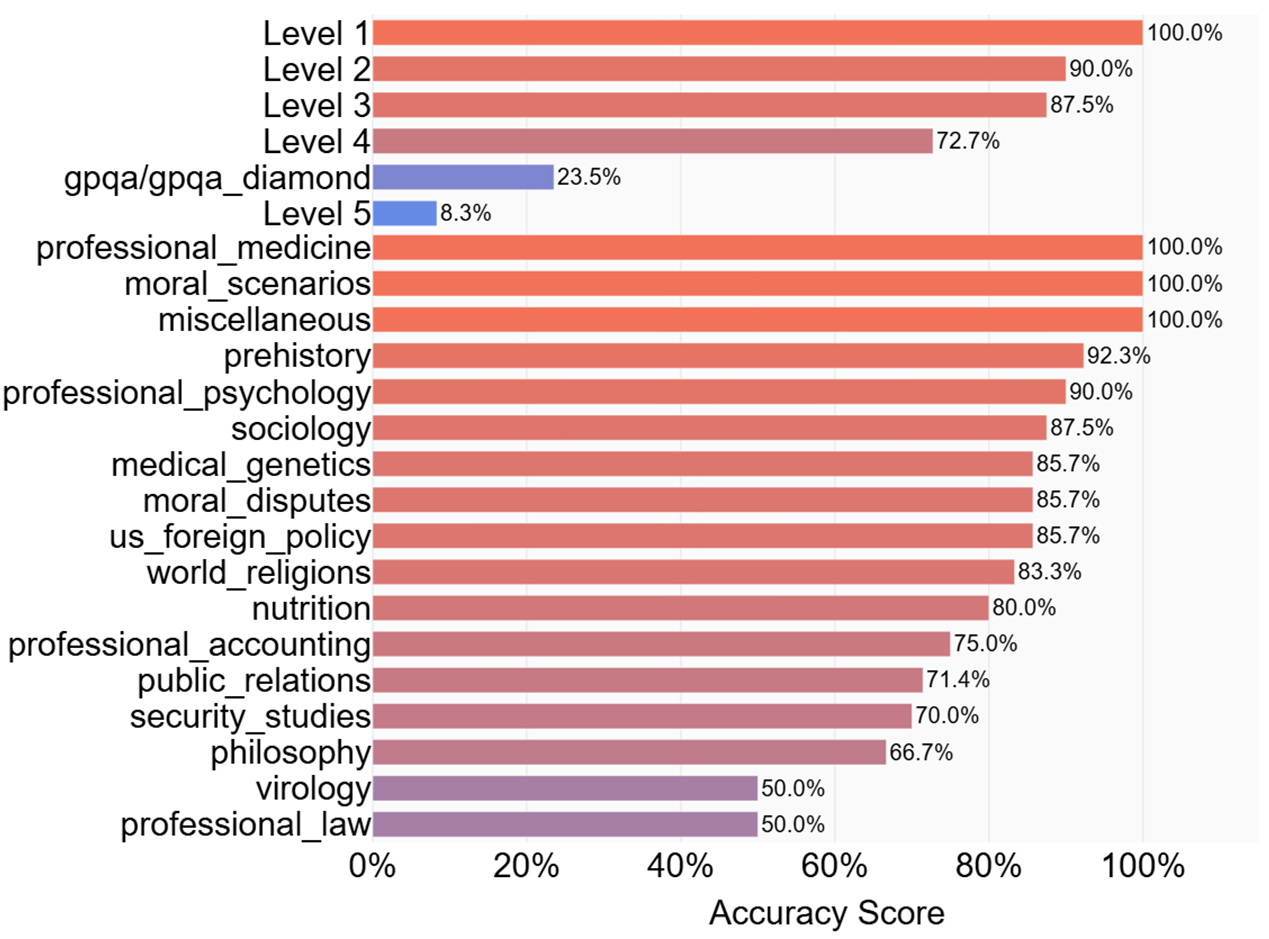
Figure 4. Fine-grained performance breakdown of the Qwen3-8B-fine-tuned Model on General Capability Benchmarks. This figure presents a detailed performance analysis of our fine-tuned model on a wide range of individual sub-tasks from the MATH and MMLU benchmarks, evaluated via the EvalScope framework. The sub-tasks are grouped into two main categories: Math&Science and English. Bars are sorted by accuracy score within each group, and their color intensity corresponds to performance (brighter red for higher scores, purple/blue for lower scores). The results clearly illustrate the “specialization effect”, showcasing strong model performance on most English sub-tasks and foundational math (Levels 1-3), while highlighting performance degradation on highly specialized, out-of-domain tasks such as advanced math (Level 5) and professional_law.

