

An integrated energy system scheduling method considering year-round load variations based on deep reinforcement learning
 0
0 Abstract
With the integration of renewable energy and energy storage in integrated energy systems, their operational and managerial complexity has substantially escalated. This study introduces a novel operational optimization strategy model, convolutional neural network (CNN)-multi agent twin delayed deep deterministic policy gradient (MTD3), based on deep reinforcement learning (DRL). By integrating expert knowledge into DRL, the challenge of failing to shut down certain equipment, which arises when DRL is applied to control continuous actions, has been addressed. Additionally, it mitigates the inappropriate exploration of agents in dynamic load scenarios. The k-means method is used to categorize the annual load, and train specific agents to handle the classified loads. Additionally, a CNN is proposed for load classification and agent selection. Expert knowledge constraints are incorporated into the reward functions. The CNN-MTD3 method not only improves training speed but also reduces annualized operating costs by 4.7% and 10.4% under cooling and heating load scenarios, respectively, compared to the baseline TD3 (twin-delayed deep deterministic policy gradient) method. Notably, the regulation of battery and thermal energy storage equipment by CNN-MTD3 is particularly significant. In continuous day cooling and heating scenarios, the effective operating h of the battery energy storage system increased by 26% and 98%, respectively. Furthermore, there was a 269.2% increase in thermal energy storage system operating in heating scenarios. We conducted a sensitivity analysis on the number of clusters and the CNN classification within CNN-MTD3 to verify the robustness of the method. These outcomes compellingly underscore the efficacy of the methodology proposed in this study.
Keywords
INTRODUCTION
Research background
The integrated energy system (IES) refers to electricity generated near the user side, which can be utilized for electricity generation or combined cooling, heating, and power (CCHP). Compared with centralized energy systems, IES offers the advantages of promoting clean energy consumption and enhancing user-side flexibility[1]. It can leverage multiple energy sources and technologies to achieve grid-connected or off-grid operation. Therefore, it is a promising solution for addressing global energy challenges and alleviating emission reduction pressure[2].
However, the large-scale integration of renewable energy into the IES supports the green transformation of the energy structure[3]. Simultaneously, the uncertainty and randomness of renewable energy pose more significant challenges for IES in achieving efficient and stable control strategies. This necessitates adopting refined and intelligent scheduling strategies to address these challenges[4]. As the elements of IES evolve, their optimization problems and solutions change accordingly. The optimization problem of IES is divided into two categories: traditional methods based on physical models and artificial intelligence (AI) methods, including reinforcement learning (RL)[5]. They are summarized in the following sections.
Optimization algorithm for energy system operation
Traditional optimization dispatch approaches
In existing research, numerous traditional approaches have been proposed to address the scheduling issues of IES[6]. Initially, optimization problems for IES relied on traditional linear programming (LP) methods that were simple and easy to implement[7]. However, with the need to consider discrete and continuous decision problems for each piece of equipment, mixed integer linear programming (MILP) and mixed-integer nonlinear programming (MILNP) in mathematical programming methods are used to handle such optimization problems[8]. Subsequently, the dynamic programming (DP) method was introduced to handle multi-stage decision problems considering time series, such as optimizing the operation of IES over multiple periods[9]. As the scale and complexity of optimization problems increase, the above methods face challenges regarding time and space processing. Heuristic and metaheuristic algorithms, represented by the genetic algorithm (GA)[10], particle swarm optimization (PSO) algorithm[11], and simulated annealing (SA), are widely used due to their advantages in finding approximate solutions to large-scale problems[12].
However, the above traditional mathematical models face challenges in solving energy system operation optimization problems, which are characterized by multivariate, multi-constraint, and multi-dimensional features. Due to the introduction of energy storage and renewable energy, the complexity and randomness of the energy system have increased. Therefore, the application of AI algorithms in the energy field is gradually emerging [13]. Attributed to its robust nonlinear fitting capabilities, model-agnostic nature, and proficient decision-making process, RL as a kind of AI is proposed to address such operation problems in IES[14].
RL application in IES optimization dispatch
RL is a decision-based learning method that can learn optimal strategies through interaction with the environment. This ability makes RL suitable for applications that require continuous decision-making, such as the optimization scheduling of IES under the renewable and load uncertainty scenario[15]. The RL method based on the value function, represented by Q-Learning, is used to learn the value function (Q-value) of long-term expected benefits for taking each possible action under a given state[16]. However, handling high-dimensional state spaces is difficult because they rely on lookup tables to store the values of each state-action pair, which becomes infeasible when the state or action space is large.
Deep reinforcement learning (DRL) performs outstandingly in tasks with complex or high-dimensional state spaces[17] in IES. This technology combines deep learning (DL) with RL[18], utilizing DL models to represent strategies or value functions in RL. According to the characteristics and mechanisms of DRL, it can be divided into value-based methods[19] and policy-based methods[20]. Deep Q network (DQN)[21], double DQN, and double dueling deep Q Net (D3QN) are value-based methods. This approach focuses on learning the value of each state or state-action pair to maximize future expected returns. It is suitable for problems with discrete action spaces, such as starting a device or adjusting power output levels. Zheng et al. used the D3QN method and proposed a multi-stage real-time dispatch method for IES based on RL[22]. The convergence rate is accelerated by reducing the number of actions in the action space and introducing an improved action-choosing strategy[4]. However, this method is hardly applicable when the action space is large and continuous. Compared with the value-based method of DRL, policy-based methods represented by REINFORCE, advantage Actor-Critic (A2C), and Asynchronous Advantage Actor-Critic (A3C) can optimize directly in the policy space, handle continuous action spaces, and directly output the optimal action[23]. Nakabi et al. utilized the A3C algorithm in their study on enhancing the energy management system of a microgrid using DRL[24]. The methods above cannot address IES optimization problems characterized by continuous control.
The deep deterministic policy gradient (DDPG) excels in handling continuous action spaces and leverages deep neural networks for complex environments. It incorporates experience replay and target networks to stabilize training and improve sample efficiency. Despite the potential slower convergence speed, DDPG remains a potent algorithm for solving challenging RL problems. Yang et al. introduced an enhanced DDPG algorithm to address IES’s dynamic energy dispatch challenge[25]. Thus, the improved version of DDPG, Twin Delayed DDPG (TD3), is applied to address the continuous control optimization problem of IES operation in this study.
In conclusion, DRL has yielded specific achievements in addressing the optimization challenges of IES operations. It is well-suited for addressing continuous decision-making problems, yet it presents challenges in handling device shutdown actions. Moreover, in scenarios characterized by high-dimensional action and state spaces, establishing the reward function poses significant challenges, as it is pivotal for quantifying objectives and facilitating interaction between IES and algorithms. An improperly set reward function can readily lead to disordered device output, necessitating the inclusion of specific constraints. Consequently, our literature review focuses on the DRL training sets, agents, and reward functions, as shown in Table 1, and we raise the following questions.
Comparison of DRL methods application in energy systems
| Key algorithm | DRL training set | DRL agent set | DRL reward function set | References | ||
| Training set of load type | Training set length | Agents for load type | Energy storage device | Reward function setting | ||
| A3C | × | 10 days | × | BESS | Cost | [24] |
| SAC | × | 2 months | × | BESS, TESS | Cost | [26] |
| DDPG | × | 1 year | × | BESS | Cost | [25] |
| PPO | × | 120 days | × | / | Cost | [27] |
| SAC | × | 6 months | × | BESS | Cost + Power Constraint | [1] |
| Q-learning | × | / | × | BESS | Cost + Power Constraint | [28] |
| SAC | × | 3 months | × | BESS, TESS | Cost +Power Constraint | [16] |
| DDPG | × | / | × | BESS, TESS | Cost +Power Constraint | [29] |
| DQN | × | 1 month | × | TESS | Cost +Power Constraint | [5] |
| DQN | × | 5 months | × | PHS | Cost +Power Constraint | [30] |
| D3QN | × | / | × | BESS, TESS | Cost +Power Constraint | [22] |
| TD3 | √ | 1 year | √ | BESS, TESS | Cost + Power Constraint + Prior Knowledge | This paper |
(1) For the training set, existing studies predominantly address a single type of load, ranging from a few days to several months, rarely including data for an entire year.
(2) For agent control, the TD3 algorithm can address IES optimization problems involving continuous control. However, the current TD3 agent is commonly used for controlling continuous actions, making it challenging to achieve shutdown actions for devices with discrete action characteristics, such as thermal energy storage system (TESS) and battery energy storage system (BESS) equipment. This results in unreasonable energy storage and other device outputs.
(3) Most studies only consider cost and power constraints for the reward function. Agents have long learning times and slow convergence rates. Furthermore, the limitations in training set length and learning time can lead to insufficient learning by the agents, resulting in improper device operation.
Contribution and research content of this study
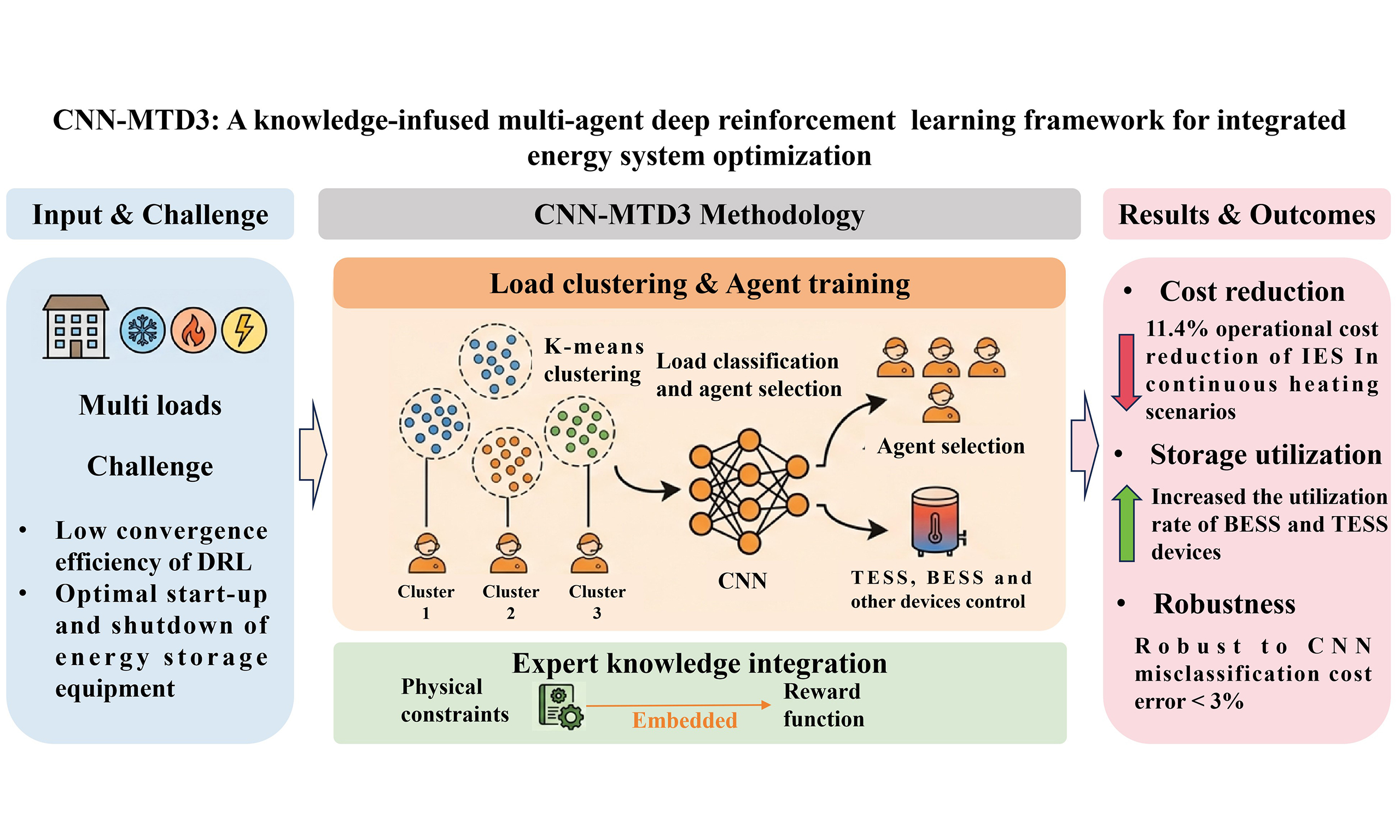
In response to the defects mentioned above, this study proposes a DRL framework called CNN-MTD3, which aims to optimize the scheduling of IES throughout the year. The CNN-MTD3 framework involves training multiple TD3 agents to handle various loads and employing a convolutional neural network (CNN) for agent recognition and control. Expert knowledge is incorporated into the agents to enhance the model’s accuracy and adaptability, thereby mitigating the error issues inherent to the DRL algorithm.
The specific contributions of this study are summarized as follows:
A collaborative training architecture based on k-means load clustering and Task-specific Agents is proposed, which overcomes the core bottleneck of low convergence efficiency of DRL in complex annual cycle scheduling and provides a new paradigm for large-scale time-varying system optimization.
A CNN is designed as an agent dynamic selector, breaking through the limitation of traditional DRL single strategy to realize autonomous decision switching under multi-modal loads. Moreover, a direct control mechanism of CNN for discrete actions of TESS is realized, solving the optimization problem of mixed action spaces.
A deep nesting mechanism of expert rules and reward functions is established. The exploration direction of agents is guided by physical constraints, which solves the problem of equipment disoperation of DRL in continuous control and significantly improves the strategy feasibility and equipment regulation accuracy in dynamic scenarios.
The structure of this paper is summarized as follows: The research background and literature review are presented in Section 1. Section 2 elaborates on IES equipment’s scheduling constraints and objective functions, the DRL methods, and the Markov decision processes (MDP) used. Section 3 introduces the architecture of the study, data clustering approach, integration of prior knowledge, and relevant hyperparameters for training the intelligent agents. The optimization scheduling results through case studies on different scenarios are compared and analyzed in Section 4. Finally, Section 5 summarizes the findings and outlines future research directions of this study.
OPTIMIZATION PROBLEM MODEL
Optimal energy management problem
This study focuses on the optimal scheduling problem of an IES that includes CCHP, BESS, TESS, and photovoltaic (PV) sources. As illustrated in Figure 1, natural gas, the electrical grid and PV are certain and uncertain energy sources for the IES. In this system, the gas engine (GE) provides electricity and heat by consuming natural gas, the electric chiller (EC) and the absorption chiller (AC) are responsible for cooling, the heat pump (HP) is used for heating, while the BESS and TESS store electrical and thermal energy, respectively.
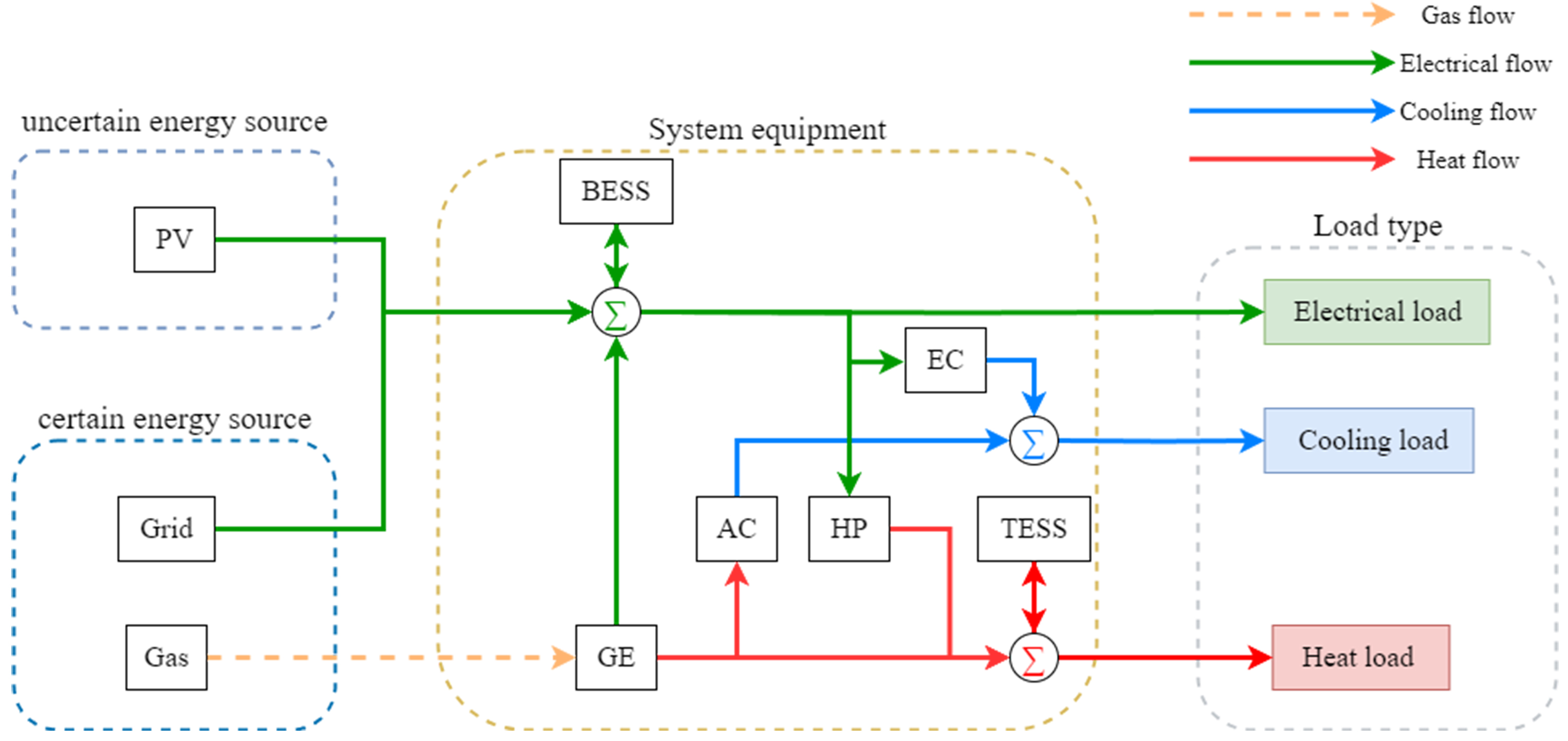
Figure 1. Research object of the IES. PV: Photovoltaic; BESS: battery energy storage systems; GE: gas engine; EC: electricity cooling; AC: absorption cooling; HP: heat pump; TESS: thermal energy storage system.
The research objective is to minimize the operational cost of the comprehensive energy system under the constraint of random source-load conditions. A DRL method, specifically the TD3 algorithm, is adopted to solve the optimal scheduling problem. The manuscript’s overall structure is depicted in Figure 2. The DRL environment represents the operational setting of IES, with the annual load generated by EnergyPlus. The annual load types are clustered, individually matching each clustering outcome to a TD3 agent. A multitasking CNN is trained to serve as a selector for TD3 agents and as a start-stop controller for TESS. The agent is trained under the guidance of expert knowledge and CNN. Subsequently, the impact of clustering, CNN, and expert knowledge on IES is analyzed. The outcomes are examined from the perspectives of system economics and equipment output.
Figure 2. Overview of the methodology for the proposed CNN-TD3 optimization operational framework. CNN: Convolutional neural network; TD3: twin delayed deep deterministic policy gradient; RL: reinforcement learning; DRL: deep reinforcement learning; DES: direct event simulation; TESS: thermal energy storage system.
Objective function and constraints
Objective function
The optimization problem aims to minimize the operational expenses of the energy system. Hence, the daily operational cost is the designated objective function, as given in
where COST represents the cost incurred by the IES, and the variable t signifies the time step denoted in h.
Electricity and natural gas procurement expenditures can be computed by multiplying the consumption by the respective prices using
where
Constraint setting
The constraints primarily encompass limitations on device output concerning performance, along with constraints ensuring energy balance.
(1) Constraints on device performance
The GE must ensure that its electrical and thermal power outputs remain within the specified maximum and minimum generation capacities and the defined maximum and minimum heating capacities.
where
The AC utilizes waste heat from the GE and must operate within the defined maximum and minimum cooling power limits.
where
The HP uses electrical energy to provide heat and must adhere to its COP and maximum and minimum heating power limits.
where
The EC uses electrical energy to provide cooling and must comply with its COP and maximum and minimum cooling power limits.
where
The BESS manages energy through charging and discharging processes and must adhere to its capacity limits and maximum charging and discharging capabilities.
where
The TESS manages energy by storing and releasing heat, and it must adhere to its capacity limits and maximum charging and heat release capabilities.
where
(2) Constraints of energy balance
The load balancing constraints are established to fulfill user demands, and the constraints for cooling, heating, and electricity loads are expressed as follows:
where
MDP
In RL, the environment and the agent are pivotal concepts. The environment encapsulates the task or problem domain that requires resolution. It furnishes state information to the agent and provides feedback on actions executed by the agent. The agent, in turn, is instantiated through neural networks and algorithms tasked with discerning the optimal policy within the environment. Based on the state information provided by the environment, the agent takes various actions and adapts in response to reward signals, with the goal of developing a strategy that maximizes long-term cumulative rewards. Facilitating the interactive learning interplay between the environment and agent mandates formalizing the problem as a MDP model. This model delineates the four principal variables: states, actions, state transition probabilities, and reward functions.
State space
The state space denotes the feasible states of the environment observable by the agent. In this study, the states encompass the energy demand at the user side, PV power generation, electricity price, and SOC of the BESS and TESS at each time step t. To delineate the state space, these states above are defined in
where st denotes the state space.
Action space
The action space represents the set of all conceivable actions accessible to the agent within the environment. In optimizing the IES, the action space encompasses the decision variables within the agent’s control, comprising the output of the GE and the charging or discharging power of the BESS and TESS. These decision variables are expounded upon in
where at denotes the action space.
Reward function
The reward function is pivotal in RL, guiding the agent toward the desired behavior and optimal policy. In this study, the reward function consists of three primary components:
(1) Operating cost: The cost of purchasing electricity from the grid and natural gas, which the agent seeks to minimize.
(2) Supply-demand balance: Encourages stable and reliable operation of the IES.
(3) Expert knowledge penalties: Incorporate domain-specific constraints and preferences to discourage irrational actions.
While the initial two components of the reward function are consistent across the three agents undergoing training, the third component, expert knowledge, is tailored to accommodate the distinct load characteristics. This approach enables the agents to acquire policies attuned to the various load profiles.
Formulating the reward function is a critical step in guiding the RL algorithm towards the targeted optimization objectives for the IES, as given in
where rt represents the reward function, α, β, and γ are constants. α, β, and γ are constants used to describe the weights of cost, energy balance, and penalty, respectively. where α, β, and γ are set to 0.0001, 0.0003, and 0.01, respectively. The results are obtained using the optimal system cost through experiments. EB denotes the amount of energy imbalance, encompassing cooling, heating, and electric load.
TD3 method
With the advancement of neural network research, DRL algorithms such as DQN and DDPG have garnered widespread recognition. These algorithms amalgamate DL and RL techniques, harnessing neural networks’ capabilities to tackle intricate decision-making tasks in dynamic environments. This showcases the potential for substantial advancements in AI research and application domains. This study adopts an enhanced TD3, which is an iteration of DDPG. Figure 3 illustrates the overall interaction between TD3 and the environment.
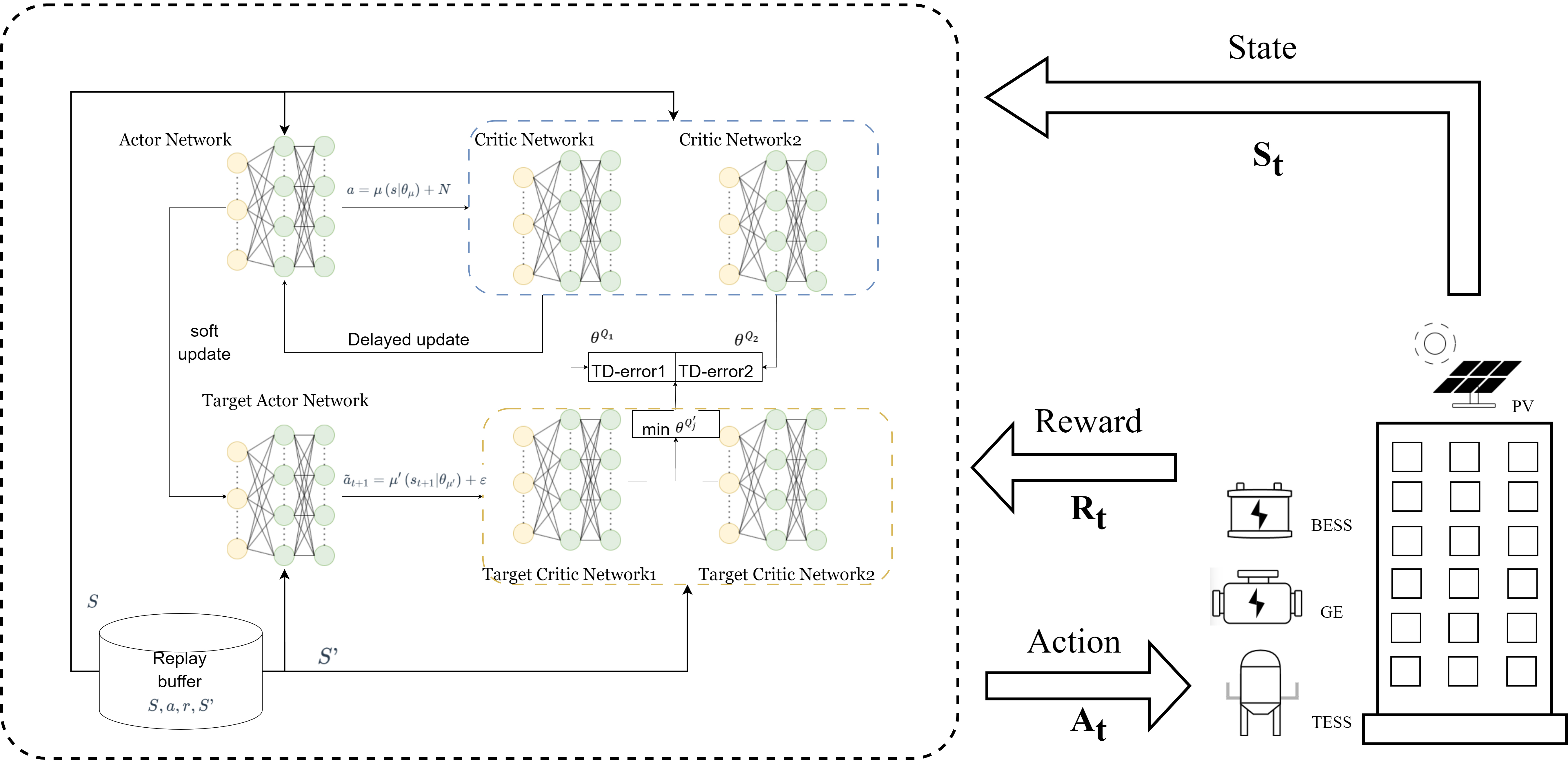
Figure 3. TD3 principal diagram. TD3: Twin delayed deep deterministic policy gradient; TD-error1: temporal difference error 1; TD-error2: temporal difference error 2; BESS: battery electricity energy storage; GE: gas engine; TESS: thermal energy storage system; PV: photovoltaic.
The primary enhancement in TD3 is introducing a dual Critic network to mitigate the overestimation of Q values. The target Critic network in DDPG is expressed as[31],
The updated approach for the target Critic network in TD3, which selects the minimum value, is given as
where yi represents the target value, r(si, ai) denotes the reward received by the agent, γ signifies the discount factor, and
where N represents the number of samples drawn from the sample pool. The update strategy for the Actor is given in
Additionally, TD3 incorporates a delayed update strategy for the Actor-network, aimed at facilitating more accurate assessment by the Critic, thereby stabilizing the learning process.
DQN employs a method known as “hard update” to update the parameters of the target network. In contrast, DDPG utilizes a “soft update” strategy. In the “soft update” strategy, the parameters of the target network are updated at every step but only partially and in proportion. This approach substantially enhances the stability of the learning process. The TD3 algorithm perpetuates this mechanism.
where 𝜏 represents the soft update factor, a hyper-parameter ranging between 0 and 1.
When updating the Critic network, the learning targets of deterministic policies can experience high variance and inaccurate evaluations due to function approximation errors. To balance the trade-off between bias and variance, it is essential to smooth the computation of Q-values to prevent overfitting. To achieve this, truncated normal distribution noise is added as a regularization term to each action, modifying the target policy network as given in
where ε denotes a random noise term that follows a truncated normal distribution N(0, σ) with a range of values between -c and c.
CNN-MTD3 method
This study proposes an RL method named CNN-MTD3. This method utilizes a multi-task CNN to select agents suitable for handling specific load types and constrain discrete devices’ start-stop actions. The algorithm includes three TD3 agents. Initially, the CNN model is trained, after which all TD3 agents are trained under the constraints imposed by the CNN. In the section on DRL algorithms, Python and Stable Baselines3 [32] were utilized for implementation. Additionally, the OpenAI Gym[33]toolkit was employed to simulate the environment of IES. The CNN components were implemented using PyTorch[34] [Figure 4].
Figure 4. CNN-MTD3 method. CNN-MTD3: A deep reinforcement learning algorithm proposed in this paper; CNN: convolutional neural network; TD3: twin delayed deep deterministic policy gradient; PV: photovoltaic; BESS: battery energy storage systems; GE: gas engine; EC: electricity cooling; AC: absorption cooling; HP: heat pump; TESS: thermal energy storage systems.
The specific process is as follows: First, the CNN determines the type of load based on the predicted

Algorithm 1. CNN-MTD3 reinforcement learning method for energy management. CNN-MTD3: A deep reinforcement learning algorithm proposed in this paper; CNN: convolutional neural network; MTD3: multi agent of twin delayed deep deterministic policy gradient.
CASE STUDY
The actual enclosure structure of a building in Shanghai is selected as the research object. The CNN-MTD3 algorithm is applied to the optimization scheduling problem for this building. The core steps include parameter setting, clustering, and incorporating prior knowledge into the reward function.
Parameter setting
The energy consumption of the office building was calculated using the simulation software EnergyPlus. Energy prices are based on the time-of-use electricity rates[35] and natural gas prices[36] in Shanghai as of April 2024. The technical parameters are shown in Table 2.
The technical parameters of the IES
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| CapBESS | 3,000 kWh | CapTESS | 2,500 kWh | | 900 kW | COPHP | 4.0 |
| | 0.9 | | 0.9 | | 180 W | COPEC | 5.0 |
| | 0.1 | | 0.1 | | 5,000 W | COPAC | 1.2 |
| | 0.96 | | 0.96 | | 4,500 W | | 0.8 |
| | 0.96 | | 0.96 | | 1,200 kW | PrGrid | ¥0.5034/ ¥0.96/ ¥1.5079 |
| | 400 kW | | 400 kW | | 600 kW | | 600 kW |
| PrNG | 3.08 ¥/m3 | / | / | / | / | / | / |
Methods for load clustering
After using the K-means clustering method to analyze one year of load data, the optimal number of clusters was determined using the within-cluster sum of squares (WCSS) and the elbow method. As shown in Figure 5, the elbow method indicates an elbow point at WCSS of 3; thus, 3 clusters were chosen.
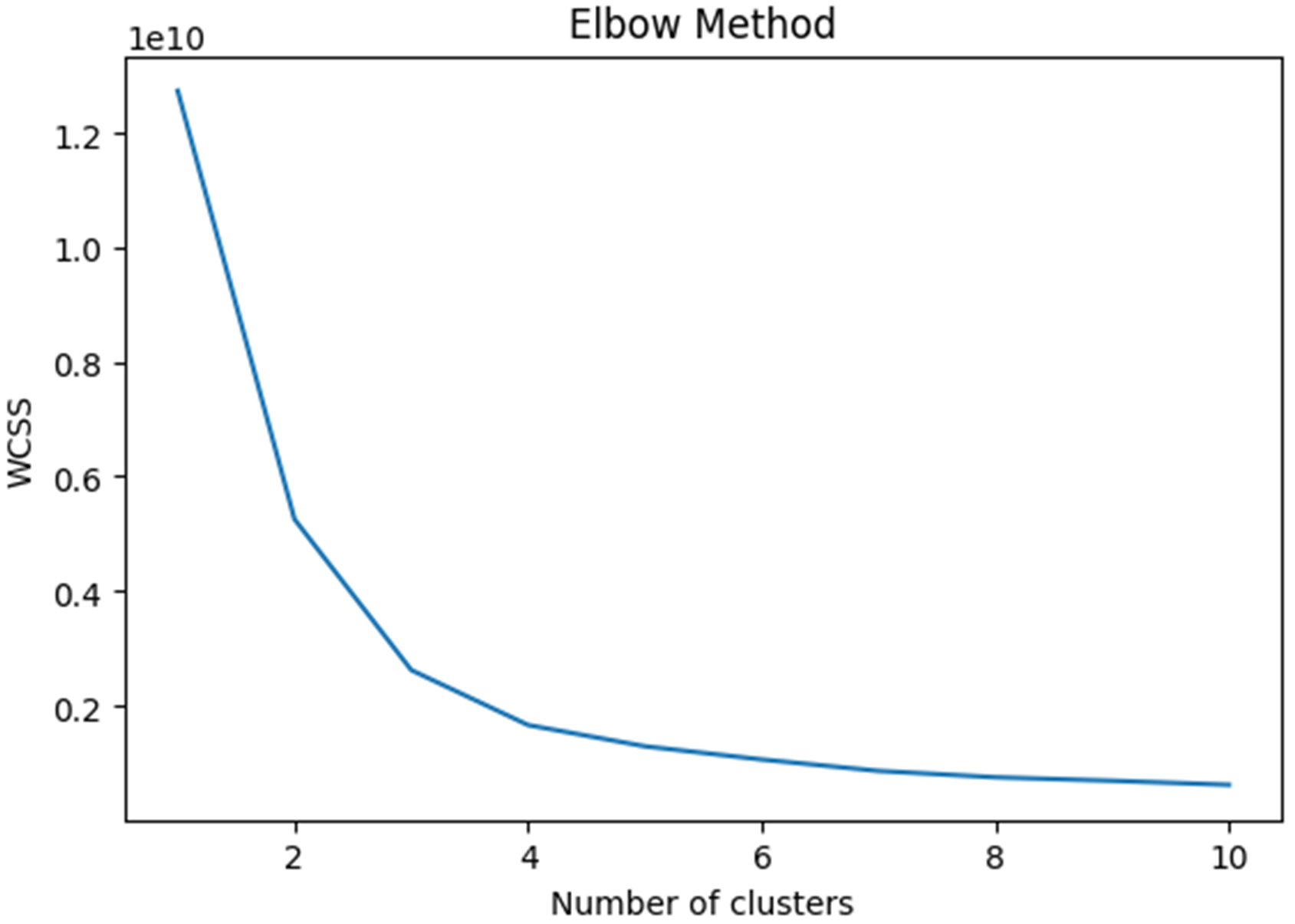
Figure 5. Elbow method for determining the number of clusters. WCSS: Within-cluster sum of squares.
The clustering results are displayed in Figure 6, showing significant differences between the clusters. Cluster 1 has a predominant presence of electrical and cooling loads, with a large overall load representing a typical summer load pattern. Cluster 2 mainly consists of electrical and heating loads, with more prominent heating loads, indicating a typical winter load pattern. Cluster 3 includes electrical loads and cooling and heating loads, which can be seen as a transitional season load pattern. Since the study subject is an office building, this cluster may also capture load characteristics during weekends.
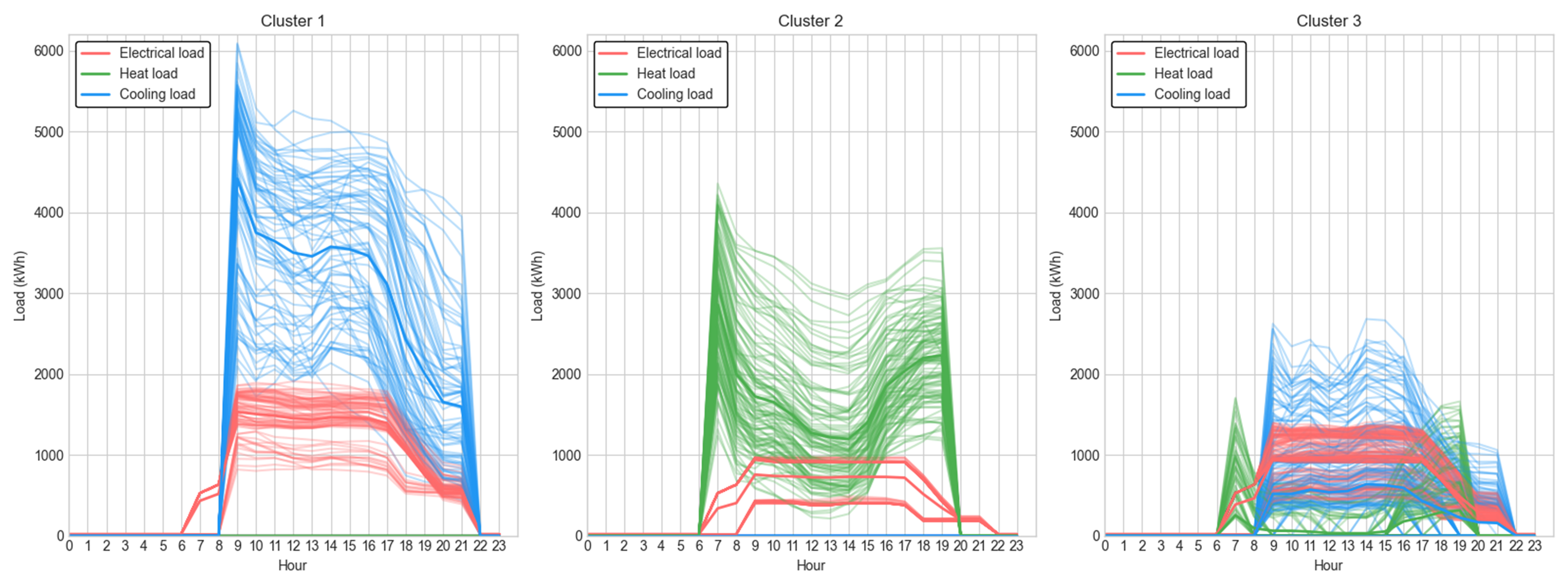
Figure 6. Clustering results of load types including electricity and cooling load scenario (A), electricity and heating load scenario (B), and lower levels of mixed cooling, heating, and power scenario (C).
Setting penalty functions
When setting up the penalty function, we designed it based on the clustering results and some prior knowledge. Figure 7 shows the differences between load types. The penalty function comprises three parts, targeting penalties for GE, BESS, and TESS, as given in
Figure 7. Box plots of loads with different clustering results, including electricity (A), heating (B), and cooling (C) scenarios.
where
(1) For the agent trained on the results of Cluster 1
We devised a specific penalty function. The first penalty is for GE because starting the generator at night to charge the BESS is economically unreasonable. This is because nighttime usually has lower electricity prices, and the waste heat from the generator cannot be efficiently utilized during this time, leading to energy wastage.
where a denotes a constant set to 0.033. Pr refers to the lowest electricity price, as referenced in Table 2.
Second, penalizing BESS for discharging at night is unreasonable. Ideally, BESS should be charged during off-peak electricity pricing (0.5034 ¥/kWh, where ¥ denotes Chinese yuan). Given that the total electricity demand surpasses BESS’s capacity limit, ceasing its charging before reaching a SOC of 0.9 would result in further penalties[37]. Furthermore, charging BESS during peak electricity pricing periods (1.5079 ¥/kWh) is impractical as it substantially elevates energy costs.
where b is a constant set to 0.028.
Finally, as evident from the boxplot, Cluster 1 solely encompasses electrical cooling loads, rendering the incorporation of TESS impractical. Consequently, TESS is deliberately restricted to 0 throughout this agent’s training. This limitation is enforced via a CNN during the final execution process.
(2) For the agent trained on the results of Cluster 2
The penalty function resembles that of clustering result 1. Initially, the treatment of GE and BESS mirrors that of clustering result 1. Despite the diminished electrical load in Cluster 2, BESS can store energy for subsequent supply to HP. Regarding treating TESS, the penalty function resembles that of BESS, as given in equation 33. First, TESS should refrain from emitting heat during nighttime periods due to the absence of heat demand. It is rational to utilize HP for heat storage during off-peak electricity periods. Second, the heat demand substantially surpasses the thermal storage capacity of TESS. Thus, if TESS ceases to store heat before its SOC drops below 0.9[37], it will incur additional penalties. Consequently, to incentivize TESS to promptly release thermal energy when the heat load demand exceeds the maximum thermal energy supplied by GE, TESS will face penalties for either not discharging or continuing to store heat. Consequently, the penalty severity increases with higher TESS SOC levels.
where c is a constant set to 0.031.
(3) For the agent trained based on clustering results 3
The penalty function for GE and BESS remains unchanged. However, given the smaller thermal load in clustering result 3, TESS no longer has a penalty for reaching its storage capacity limit to avoid wastage, as given in equation (34). It is important to note that this formula will only be effective when the CNN determines that TESS needs to be activated.
Setting scenarios and hyper-parameters and training agents
(1) Scenario setting
To validate the effectiveness of the proposed CNN-MTD3 model, seven scenarios are outlined in Table 3.
Scenario setting and corresponding content
| Scenario | Agent | Load characteristic | Expert knowledge |
| Baseline | TD3base | Annual load | / |
| Scenario with clustering | TD3c1 | Electricity and cooling load | / |
| TD3c2 | Electricity and heating load | / | |
| TD3c0 | Lower-level mixed cooling, heating, and electricity | / | |
| Scenario with clustering and expert knowledge | TD3c1-wpk | Electricity and cooling load | Operational limitations of GE, BESS, and TESS |
| TD3c2-wpk | Electricity and heating load | Operational limitations of GE, BESS, and TESS | |
| TD3c0-wpk | Lower-level mixed cooling, heating, and electricity | Operational limitations of GE and BESS |
These scenarios are proposed to assess the impact of load clustering, expert knowledge, and CNNs on the IES’s optimization operations.
(2) Hyperparameters and training agents setting
First, we trained a TD3base agent without load clustering and prior knowledge integration. This agent underwent the lengthiest duration, spanning 168*1,500 timesteps. Here, a time step denotes the dataset utilized for DRL training, encompassing 168 h weekly and comprising 1500 samples per training session. The training process graph illustrates TD3base’s slow convergence coupled with notable fluctuations. This phenomenon stems from each training episode randomly sampling from the entire test set, with the training set encompassing data for an entire year. Given the close correlation between energy cost and load size, this substantial variation in the state space profoundly influences the fitting of the state-value function.
Second, to verify the effectiveness of clustering the training set by load, agents trained on different loads were set to train for 168*500 timesteps. The results demonstrate that load clustering notably enhances convergence speed, as evidenced by Figure 8, which illustrates that clustering effectively regulates the fluctuation range of the reward curve. This illustrates that clustering diminishes the reward volatility associated with energy costs and load sizes, effectively augmenting the agents’ training efficiency.
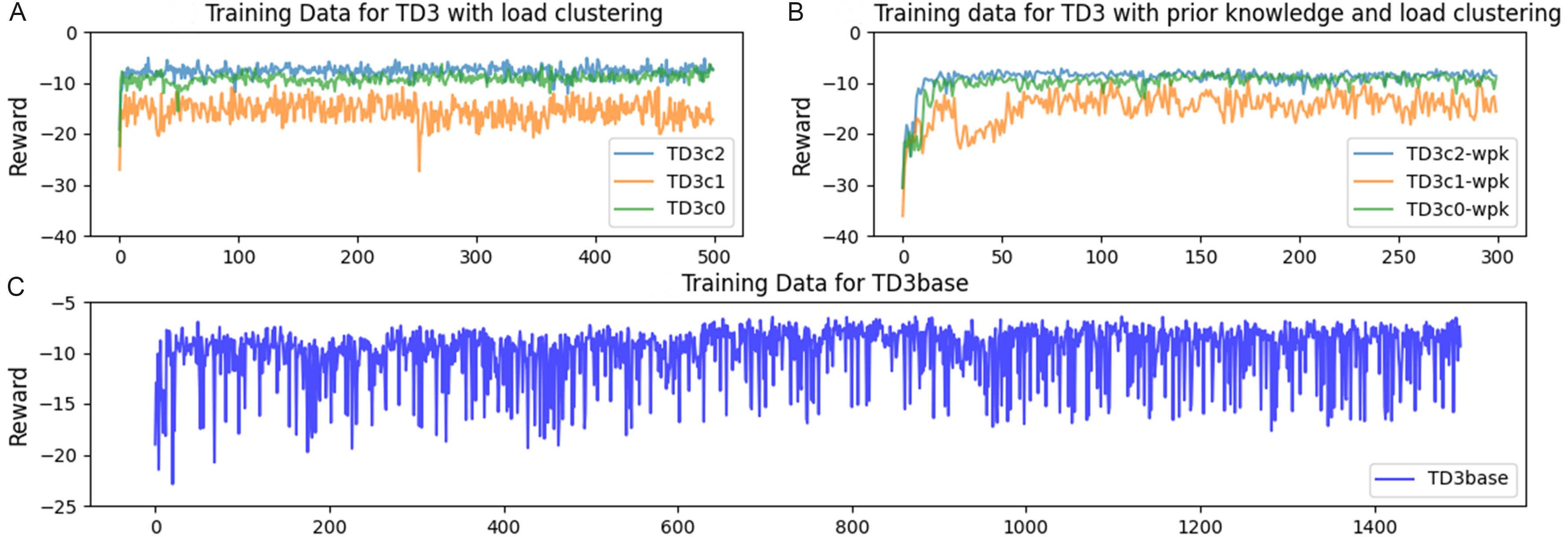
Figure 8. Comparison of training results in different scenarios, including training data for TD3 with load clustering (A), TD3 with prior knowledge and load clustering (B), and baseline scenario (C). TD3: Twin delayed deep deterministic policy gradient; TD3base: this primary scenario does not employ load clustering and does not incorporate expert knowledge into the reward function; TD3c2: scenario with clustering under heating electricity load; TD3c1: scenario with clustering under cooling electricity load; TD3c0:scenario with clustering under lower-level mixed cooling, heating, and electricity;TD3c2-wpk: scenario with clustering and expert knowledge under heating electricity load; TD3c1-wpk: scenario with clustering and expert knowledge under cooling electricity load ; TD3c0-wpk: scenario with clustering and expert knowledge under lower-level mixed cooling, heating, and electricity load..
Lastly, three agents with a prior knowledge penalty function underwent training for the shortest duration of 168 * 300 timesteps to assess the effectiveness of incorporating prior knowledge. Figure 8 indicates that integrating prior knowledge effectively enhances the rewards for TD3c1-wpk and TD3c2-wpk. Despite the substantial penalties initially incurred due to exploratory actions influenced by prior knowledge, it is evident that as training progressed, both agents swiftly improved their rewards, effectively learning from prior knowledge [Table 4]. The slight variance between the final rewards and those obtained solely through clustering primarily arises from the cost associated with each episode, which is randomly selected. Additionally, the penalty from prior knowledge serves to diminish the rewards.
The parameters of the multi-task CNN
| Hyperparameter | Value |
| Convolutional layer 1 | Input channels: 1, Output channels: 4, Kernel size: 3, Stride: 1, Padding: 1 |
| Convolutional layer 2 | Input channels: 4, Output channels: 16, Kernel size: 3, Stride: 1, Padding: 1 |
| Pooling layer | Pooling kernel size: 2 |
| Fully connected layer 1 | Input size: 16 * 3, Output size: 32 |
| Fully connected layer 2 | Input size: 32, Output size: 16 |
| Task 1 FC layer | Input size: 16, Output size: 3 |
| Task 2 FC layer | Input size: 16, Output size: 2 |
| Activation function | ReLU |
| Loss function | Task 1: Cross entropy, Task 2: Cross entropy |
| Optimizer | Adam |
| Learning rate | 0.001 |
RESULTS AND DISCUSSION
In this section, a comparison of these seven agents is conducted within the proposed CNN-MTD3 framework. Typical days are employed to validate clustering, expert knowledge, and the role of CNN in IES separately. However, the use of typical daily load patterns is limited, as it fails to fully demonstrate the advantages of CNN-MTD3 in determining load types and selecting agents. For instance, heat loads are high on weekdays during the heating season’s typical week but drop substantially on weekends due to office buildings being closed. In such cases, the CNN-MTD3 algorithm proposed employs multiple agents trained to handle continuous load data across various types. The resulting impact is particularly notable in controlling various devices, especially storage equipment. To comprehensively assess the effectiveness of the CNN-MTD3 algorithm in optimizing IES operational strategies across diverse scenarios, days during both the heating and cooling seasons were utilized as the training set. Subsequently, the impact of the CNN-MTD3 algorithm on each device was compared and analyzed across these scenarios.
Regarding the logic behind selecting the test set, training set, and validation set, after clustering the annual data, to ensure the generalizability of the model evaluation and prevent data leakage, we adopted the following data partitioning strategy: First, we selected three cluster centers as representative days to conduct operational optimization analysis under these conditions. It is worth noting that Cluster 3 had relatively low heating, cooling, and power loads, with indistinct and similar distribution characteristics. Therefore, instead of selecting a cluster center, we randomly chose a single day as the representative day. Based on the selection of representative days, we selected 120 consecutive h of data containing these three representative days as the test set. All data from the test set was excluded to ensure that the test data was completely excluded from the training process of the CNN. The remaining data was randomly split into a training set and a validation set in a 7:3 ratio. During the partitioning of the test, validation, and training sets, we ensured that different date types were reasonably distributed across the three parts. This method avoids overly optimistic results caused by temporal proximity.
Optimizing results under a typical day
Cluster 1 and 2 encompass two types of loads, with Cluster 2 exerting a notable influence on TESS during the heating season. Consequently, the efficacy of clustering and expert knowledge is validated compared to the TD3base scenario under Cluster 2. Additionally, Cluster 3 comprises three types of loads: cooling, heating, and electricity. In this scenario, the research subjects exhibit similar nighttime state spaces, posing challenges for RL to learn the scheduling of BESS and TESS effectively. Hence, under these circumstances, Cluster 3 is utilized to ascertain the effectiveness of CNN constraints.
Validation of load clustering and expert knowledge under Cluster 2
This section compares and analyzes the impact of expert knowledge and clustering on equipment output and system cost. A typical day under heating conditions is selected as the research object. The device output and heat load distribution are depicted in Figure 9. The heat load is supplied by three devices, namely GE, TESS, and HP, with HP’s electrical energy sourced from GE, PV, Grids, and BESS. HP’s output is distributed based on the current output ratios of Grids, PV, GE, and BESS. It is observed that the TD3c2 agent, without prior knowledge, only learned the scheduling strategy for TESS and failed to learn about BESS. This deficiency is evident in Figure 9, where the absence of the green portion compared to other agents indicates BESS did not contribute to the energy dispatch.
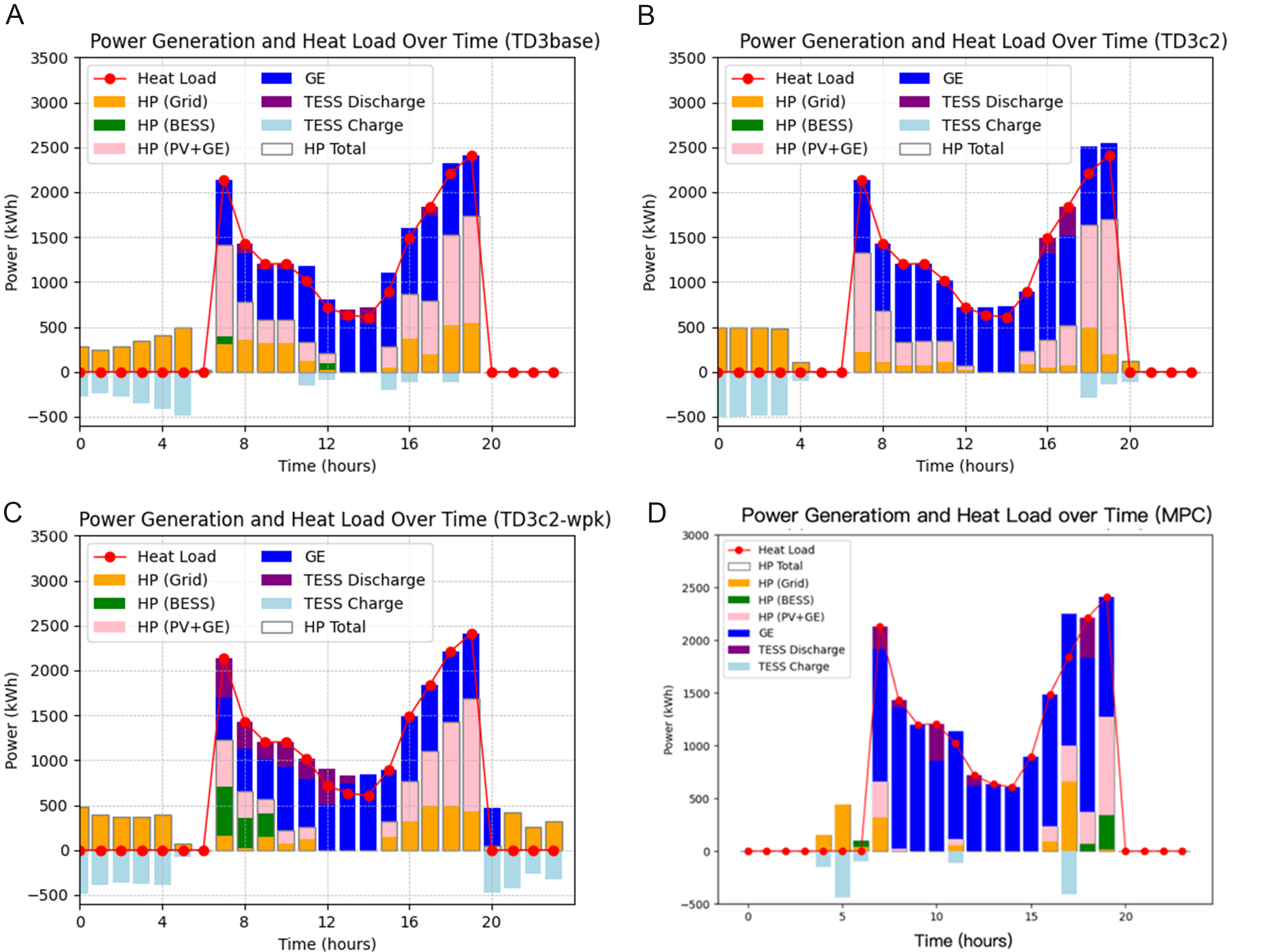
Figure 9. The impact of clustering and expert knowledge on the output of different devices. (A) Output of different devices in TD3base scenario; (B) Output of different devices in TD3c2 scenario; (C) Output of different devices in TD3c2-wpk scenario; (D) Output of different devices in MPC scenario. TD3base: This primary scenario does not employ load clustering and does not incorporate expert knowledge into the reward function; TD3c2: scenario with clustering under heating electricity load; TD3c2-wpk: scenario with clustering and expert knowledge under heating electricity load; MPC: operational optimization using model predictive control algorithms; HP: heat pump; BESS: battery electricity energy storage; PV: photovoltaic; GE: gas engine; TESS: thermal energy storage system.
From the output of HP, it is apparent that BESS did not participate in the energy conversion, resulting in a loss of potential profits from lower nighttime electricity prices. This occurred because TESS scheduling was more accessible to optimize for higher rewards, causing the agent to neglect the scheduling strategy for BESS, which might require longer training steps to achieve. From the graph of TD3base, there is no TESS activity after 20 h. This is attributed to both agents maintaining the SOC of TESS at a high level, thereby lacking effective utilization. Additionally, the power generation of GE in TD3base is lower than the others, leading to a failure in harnessing combined heat and power generation.
As shown in Figure 9D, compared with the TD3 method method, the limited control step size of MPC prevents effective use of heat pumps to store thermal energy in the TESS during periods of low electricity prices, reducing potential benefits. Given that RL possesses long-term planning capabilities, the costs of TD3base, TD3c2, and TD3c2-wpk are all lower than those of MPC.
Table 5 summarizes the impact of clustering and expert knowledge on system cost. Compared to the TD3base scenario, the TD3c2 scenario, after clustering, optimized the output of each device and reduced system costs by 9.3%. After incorporating expert knowledge, the learning of TESS and BESS became more effective, and the TD3-wpk scenario further reduced the cost by 2.4% compared to scenario TD3c2. Due to the inability to perform long-term optimization, its operating cost exceeds the optimization results of all RL scenarios.
Comparison of operation cost under different scenarios
| Agent | Cost (¥) |
| MPC | 13,095.21 |
| TD3base | 12,676.18 |
| TD3c2 | 11,503.58 |
| TD3c2-wpk | 11,229.48 |
Validation of CNN utilized under Cluster 3
In the last scenario of a typical day in cluster result 3, the figures utilize device output and electrical load to explain. Since the test set load encompasses cooling, heating, and electricity, and both cooling and heating loads are minimal, the device schedule differs from the first two typical days, as depicted in Figure 10. From 0 to 5 h, TD3c0 (scenarios representing typical electric cooling and heat loads) utilized Grids to store energy in TESS. However, this typical day had no heat load, resulting in energy waste. TD3c0’s action is attributed to the inclusion of current load demand in the state space and the similar nighttime load demands, with only an electrical load. Consequently, TD3c0 could not ascertain the necessity of storing heat. In contrast, the TD3c0-wpk agent, which incorporates expert knowledge and CNN processors for nested agents based on scenarios representing typical electric cooling and heating loads, effectively schedules the BESS under the constraints of CNN on TESS actions and, when trained with prior knowledge, reduces the system cost by 7.58% [Table 6].
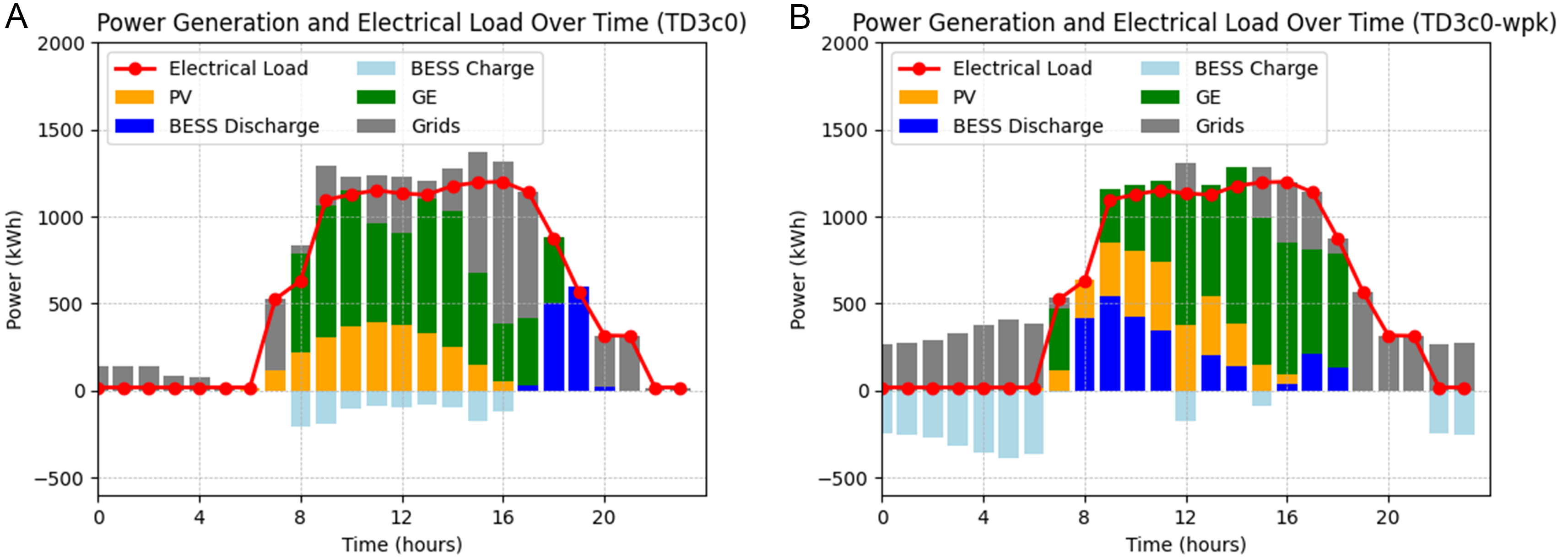
Figure 10. Typical day of cluster result in 3 for TD3 with load clustering (A) TD3 with prior knowledge and load clustering (B). TD3: Twin-delayed deep deterministic policy gradient; TD3c0:scenarios representing typical lower-level mixed cooling, heating, and electricity load loads; TD3c0-wpk: incorporates expert knowledge and CNN processors for nested agents based on scenarios representing typical lower-level mixed cooling, heating, and electricity load; PV: photovoltaic; BESS: battery energy storage system; GE: gas engine.
Cost comparison on typical day of Cluster 3
| Agent | Cost (¥) |
| TD3c0 | 10,220.99 |
| TD3c0-wpk | 9,446.85 |
Optimizing results under 120 h
Validation of CNN-MTD3 under cooling scenario
To validate the comprehensive efficacy of the CNN-MTD3 algorithm framework, this study considers that the benefits of energy storage devices may not be fully discernible within a typical day. Therefore, two scenarios are selected, each spanning 120 h, encompassing both the cooling and heating seasons. A comparison is conducted to assess the impact of this study’s proposed CNN-MTD3 and TD3 baseline on device performance.
During the test period, from August 28th to September 2nd, emphasis is placed on electricity and cooling load as the primary variables. The data generated by each device exemplifies specific equipment actions, as depicted in Figure 11. Notably, the cooling load registers higher levels during the initial three days. In contrast, the subsequent two days witness a decrease due to the operational cycle of the office building. Throughout the first three days, the cooling load peaks between 9 AM and 12 PM, followed by a gradual decline. Employing the CNN-MTD3 method, the BESS exhausts all its stored electricity to fulfill the demand of the peak cooling load. Conversely, during the last two days, characterized by the reduced loads, the stored electricity in BESS takes approximately 9 to 10 h to discharge completely. In contrast, BESS’s involvement in the TD3base algorithm is comparatively lesser, particularly noticeable on the final day at 7 PM. To utilize the surplus electrical energy stored in BESS, the cooling load is solely supported by the EC, necessitating the shutdown of the GE, thereby impacting GE’s subsequent efficiency.
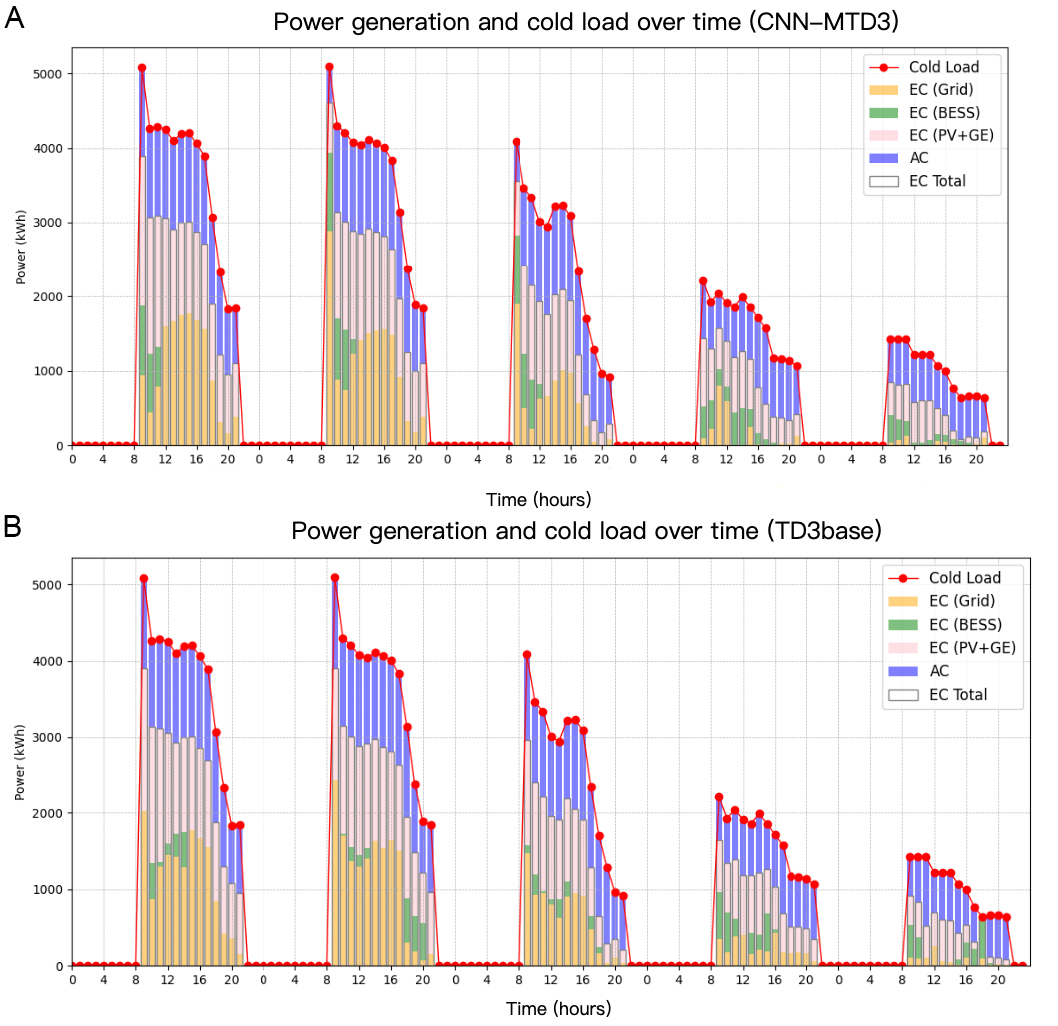
Figure 11. Operation in the cooling scenario for 120 h of CNN-MTD3 (A) and TD3base (B). CNN-MTD3: A deep reinforcement learning algorithm proposed in this paper; CNN: convolutional neural network; MTD3: multi agent of twin delayed deep deterministic policy gradient; EC: electricity cooling; BESS: battery energy storage system; PV: photovoltaic; GE: gas engine; AC: absorption cooling; TD3base: this primary scenario does not employ load clustering and does not incorporate expert knowledge into the reward function.
Validation of CNN-MTD3 under heating scenario
In the second scenario, December 24th to December 31st is chosen as the test set, focusing on electricity and heating loads. Figure 12 illustrates that the TD3base algorithm better understands BESS charging and discharging strategies. BESS’s participation is notably higher than that of TESS. Initially, TD3base fully charges TESS, but it struggles to release stored thermal energy effectively in subsequent scheduling. This may be attributed to TD3base being trained on the annual test set, making learning the BESS strategy easier than TESS. Conversely, within the selected five days of the test set, CNN-MTD3 discovers that both TESS and BESS engage in a broader spectrum of energy exchanges. Notably, TESS utilizes GE’s waste heat for energy storage in the 20th hour of each day, exploiting the surplus electricity load without heat demand, thereby effectively leveraging GE’s waste heat and minimizing energy wastage.
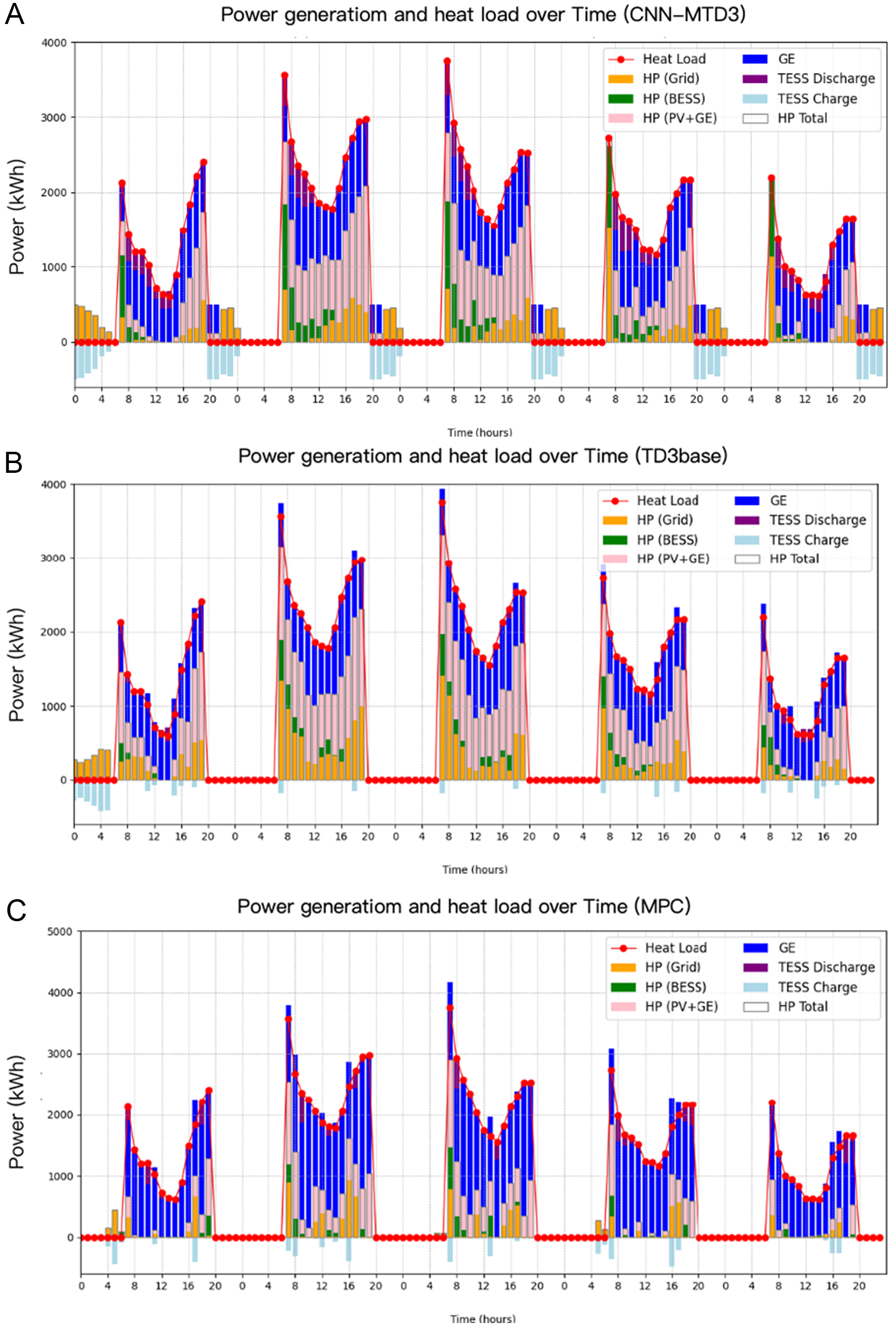
Figure 12. Operation in the heating scenario for 120 h of CNN-MTD3 (A), TD3base (B) and MPC (C). CNN-MTD3: A deep reinforcement learning algorithm proposed in this paper; CNN: convolutional neural network; MTD3: multi agent of twin delayed deep deterministic policy gradient method; TD3base: this primary scenario does not employ load clustering and does not incorporate expert knowledge into the reward function; MPC: operational optimization using model predictive control algorithms; HP: heat pump; BESS: battery electricity energy storage; PV: photovoltaic; GE: gas engine; TESS: thermal energy storage system.
Besides, Figure 12C illustrates a scenario in which MPC was configured for a 120-hour operational optimization. A comparison with TD3base reveals that, under the MPC application, the BESS and TESS were not utilized effectively; energy storage activities continued even during periods when electricity prices were not at off-peak levels, thereby increasing costs.
Performance comparison
This section compares the performance of the TD3base, CNN-MTD3 and MPC models by evaluating the operational cost and effective operating h in different scenarios. As depicted in Table 7, for both cooling and heating scenarios, the cost incurred by the CNN-MTD3 framework is lower than that of the base scenario. Specifically, compared to the base scenario, system costs in the cooling and heating scenarios are reduced by 4.7% and 10.4%, respectively. Furthermore, due to the MPC’s lack of global optimization capabilities, energy storage devices were not utilized to their full potential, resulting in a 9.37% increase in costs compared to the TD3base heating scenario, which operates continuously for 120 h.
Comparison of operating costs in different scenarios
| Cost (¥) | TD3base | CNN-MTD3 | MPC |
| Cooling scenario cost | 82,468.25 | 78,558.56 | / |
| Heating scenario cost | 62,953.05 | 56,435.11 | 69,459.77 |
Effective operating h refer to the actual number of h that equipment operates within a specific time frame. This metric is crucial as it reflects the stability and reliability of the system. By monitoring the adequate operation time of the equipment, one can evaluate the system’s performance and operational efficiency. An increase in effective operating time indicates higher utilization, thereby leading to a more efficient energy supply and cost reduction. Table 8 presents the operating time for both models in the cooling and heating scenarios, respectively.
Effective operating h of equipment in Cluster 1
| Scenario | Cooling scenario | Heating scenario | ||
| Equipment | TD3base | CNN-MTD3 | TD3base | CNN-MTD3 |
| BESS | 18.19 | 23.01 | 10.64 | 21.07 |
| GE | 47.76 | 46.87 | 44.30 | 45.92 |
| EC | 21.04 | 20.87 | / | / |
| AC | 48.02 | 48.76 | / | / |
| HP | / | / | 14.73 | 14.03 |
| TESS | / | / | 5.20 | 19.20 |
The CNN-MTD3 model excels in managing the BESS and AC units for the cooling scenario, as shown in Table 8. It demonstrates an increase in effective operating h by 4.82 and 0.74 h, respectively, compared to the TD3base model. This illustrates the significant advantage of the CNN-MTD3 model in optimizing operational efficiency and control strategies for these devices. Although there is a slight decrease in operating h for the GE and EC devices, the overall difference is minimal, indicating the stable performance of the CNN-MTD3 model with these types of equipment.
For the heating scenario, the CNN-MTD3 model particularly shines with the BESS and TESS devices. As shown in Table 7, it substantially increases the effective operating h by 10.43 and 13.8 h, respectively. This reflects the model’s exceptional ability to manage charging and discharging strategies and the efficiency of energy storage devices. The operating time of the GE equipment increased slightly by 1.62 h. The CNN-MTD3 model primarily achieves a substantial increase in the effective utilization hours of energy storage equipment.
Sensitivity analysis of cluster number and CNN performance on agent selection
Sensitivity analysis of cluster number
To verify the impact of the number of clusters on system performance optimization, we conducted a sensitivity analysis by varying the number of clusters from 2 to 5. The results are shown in Figure 13A. Excessive clustering increases the probability of misclassification in the CNN algorithm. At the same time, too many clusters reduce the size of the training dataset available for each agent, and misclassification during training also hinders the training of the agents. In addition, we conducted a comparative analysis of the system optimization costs under different numbers of clusters, as shown in Figure 13B. It is worth noting that this analysis is based on a typical heating day, where the agents were deployed in strict accordance with the clustering results. Under these conditions, an increase in the number of clusters was not observed to yield significant cost improvements.
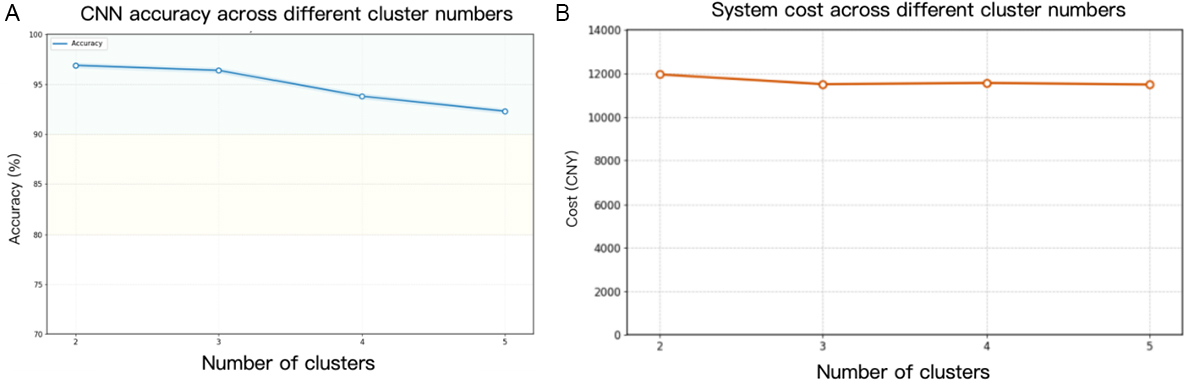
Figure 13. Variation in CNN-based agent classification accuracy (A) and IES cost with different numbers of clusters (B). CNN: Convolutional neural network; IES: integrated energy system.
Sensitivity analysis of CNN performance on agent selection
Throughout the IES operation optimization process in CNN-MTD3, the CNN plays a critical role in load classification and agent selection. To this end, we analyzed the scenarios in which misclassification occurred and their impact on system optimization. Figure 14 displays the loss, accuracy, and start/stop status of TESS for the CNN’s load classification in this study. The loss function exhibits a positive downward trend, indicating stable model training. The CNN classification accuracy exceeds 96%, and the TESS start-stop accuracy is around 95%, indicating that the CNN performs well.
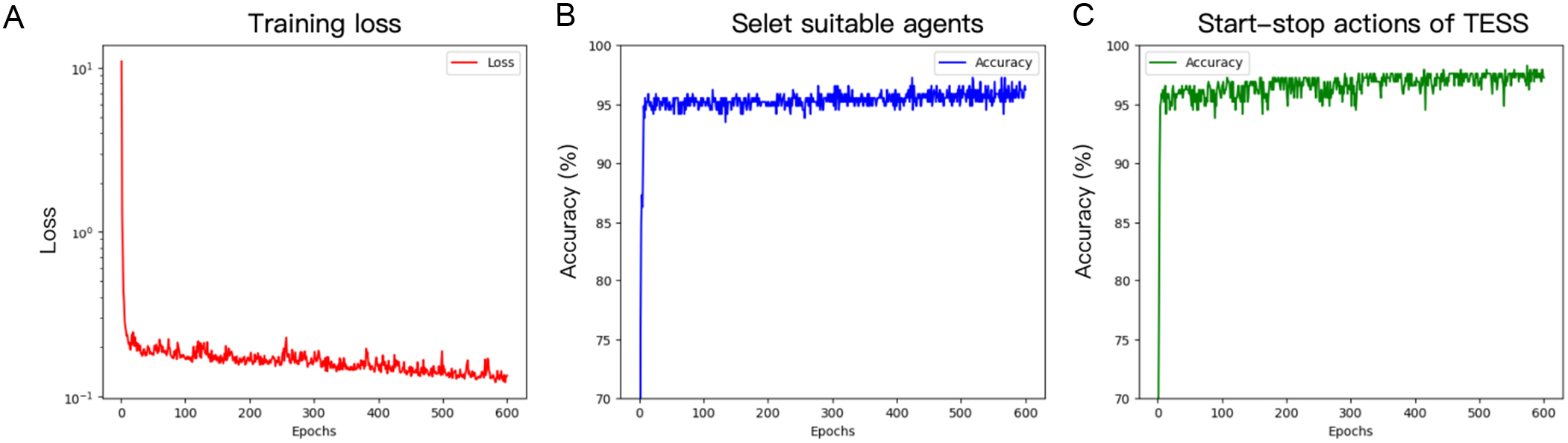
Figure 14. The training process diagram of CNN training loss (A), accuracy of select suitable agents (B), and accuracy of start-stop actions of TESS. CNN: Convolutional neural network; TESS: thermal energy storage system.
Furthermore, Figure 15 shows that, in the 100-day validation dataset, the CNN misclassified on 4 days: days 96, 186, 188, and 329 of the year. In the vast majority of cases, the CNN classifier clearly distinguishes between different scenes (as indicated by the clearly defined blue rectangles). The only four misclassifications (marked by red diamonds) all occurred in the boundary regions between different scene types, representing a typical case of boundary ambiguity rather than a structural failure of the model. The confusion matrix shows the scenarios in which the agents made misclassifications. Agents 1, 2, and 3 made 2, 1, and 1 misclassifications, respectively.
Figure 15. Maximum daily load distribution (A) and confusion matrix (B) for load classification and agent selection on CNN. CNN: Convolutional neural network.
A comparison of the operating costs between the correct and incorrect agents is shown in Table 9. It can be seen that the cost difference is not significant. Compared to the operating cost of the correct agent, the cost under the optimized operation of the incorrect agent increased by a maximum of 2.5%. This is because the similarity of the loads leads to similar decisions by the agents.
Comparison of system operating costs under correct and incorrect agent classification
| Day | Correct agent cost (¥) | Wrong agent cost (¥) |
| 96 | 11,244.14 | 11,412.58 |
| 186 | 23,210.12 | 23,534.11 |
| 188 | 12,745.21 | 12,731.56 |
| 329 | 12,144.60 | 12,456.62 |
CONCLUSIONS
This study demonstrates the effectiveness of using DRL to optimize the operation of IES, considering multiple load variations. First, the clustering algorithm k-means is utilized to classify the load and verify the impact of clustering on system efficiency and training effectiveness. Then, a CNN model is introduced for load classification and agent autonomous selection, systematically optimizing the decision-making process. Finally, by systematically integrating expert knowledge into reward function design, the training speed and effectiveness of the intelligent agent are improved. The results are summarized from two aspects. On the one hand, typical daily scenarios of different load demand types verify the advantages of clustering load, expert knowledge, and CNN. On the other hand, to comprehensively reflect the superior optimization operation ability of the CNN-MTD3 model in dealing with variable continuous load types, continuous cooling and heating scenarios are selected to analyze the impact of CNN-MTD3 on the IES and the performance changes of each piece of equipment are analyzed. The specific conclusions are summarized as follows:
(1) Clustering the training set enhances the agent’s training speed while reducing training volatility and difficulties caused by sudden load changes. Additionally, based on scheduling on a typical heating day, the TD3 agent trained with clustering outperforms the non-clustered one in scheduling the TESS, resulting in a 9.3% reduction in cost.
(2) Incorporating expert knowledge based on clustering typical heating days effectively enhances agents’ performance and improves training speed. Moreover, the TD3c2-wpk agent trained with prior knowledge saves 11.4% in cost compared to TD3base and 2.4% compared to TD3c2 trained with load clustering, respectively.
(3) The multi-task learning CNN is introduced, capable of determining specific load types and matching different agents. It also controls the discrete action switch of TESS.
(4) To fully demonstrate the benefits of energy storage equipment under the CNN-MTD3 proposed in this study, a continuous 120-hour test set is validated. The results indicate that the proposed CNN-MTD3 algorithm framework outperforms TD3base, effectively increasing the effective operating h of BESS and TESS. In cooling and heating scenarios, the effective operating h of BESS were increased by 4.82 and 10.43 h compared to TD3base, while TESS increased by 13.8 h in heating scenarios. The costs in both scenarios decreased by 4.7% and 10.4%, respectively. Additionally, under cooling and heating conditions, the operating time of AC and GE equipment has also slightly improved, with an increase of 0.74 and 1.62 h compared to the baseline, respectively.
(5) To address the robustness of the proposed CNN-MTD3 algorithm, we conducted sensitivity analyses on both the number of clusters and the classification accuracy of the CNN. The results indicate that an excessive number of clusters degrades the training effectiveness, thereby reducing the algorithm’s accuracy. Furthermore, the CNN achieves a classification accuracy of 96% for agent selection. The few misclassifications primarily occur during periods with low cooling, heating, and power loads, where the distribution of data features is less distinct. Nevertheless, due to the similarity in operational strategies across these scenarios, the error margin in operating costs between correctly and incorrectly classified cases does not exceed 3%.
Limitations
For this study’s limitation, integrating prior knowledge with reward functions enhances the application of domain-specific expertise. However, the inherent subjectivity of human judgment may introduce biases. Thus, expert knowledge should be accurately crafted during model generalization to enhance model robustness. Furthermore, as time progresses and the system complexity grows, expert knowledge should be continually updated to align with system characteristics.
Although the CNN-MTD3 method has proven its effectiveness, the incorporation of expert knowledge relies on manual configuration. Recent advancements in the field of AI - particularly the evolution from large language models to autonomous AI agents - are reshaping how complex systems are managed and optimized. Unlike traditional algorithms that execute predefined instructions, AI agents are characterized by their ability to perceive their environment, reason, plan actions, and utilize tools to achieve specific goals in a closed-loop manner. This paradigm shift toward intelligent automation offers a highly promising solution for addressing the growing operational complexity of IES that integrate renewable energy and energy storage.”
DECLARATIONS
Authors’ contributions
Made substantial contributions to conception and design of the study and performed data analysis and interpretation: Liu, Q.; Shen, H.; Xu, T.; Ruan, Y.
Performed data acquisition and provided administrative, technical, and material support: Meng, H.; Qian, F.; Yao, Y.; Gao, Y.
Writing and revision of the initial draft of the manuscript: Liu, Q.; Shen, H.; Xu, T.; Ruan, Y.
Validation and modification for the manuscript: Meng, H.; Qian, F.; Yao, Y.; Gao, Y.
Availability of data and materials
Data can be deposited into data repositories or published as supplementary information in the journal.
AI and AI-assisted tools statement
Not applicable.
Financial support and sponsorship
This work was supported by the National Key R&D Program of China (Grant No. 2023YFC3807100).
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Deng, X.; Zhang, Y.; Jiang, Y.; Zhang, Y.; Qi, H. A novel operation method for renewable building by combining distributed DC energy system and deep reinforcement learning. Appl. Energy. 2024, 353, 122188.
2. Mehigan, L.; Deane, J.; Gallachóir, B.; Bertsch, V. A review of the role of distributed generation (DG) in future electricity systems. Energy 2018, 163, 822-36.
3. Liu, R.; He, G.; Su, Y.; Yang, Y.; Ding, D. Solar energy for low carbon buildings: choice of systems for minimal installation area, cost, and environmental impact. City. Built. Enviro. 2023, 1, 16.
4. Shi, L.; Lao, W.; Wu, F.; Lee, K. Y.; Li, Y.; Lin, K. DDPG-based load frequency control for power systems with renewable energy by DFIM pumped storage hydro unit. Renew. Energy. 2023, 218, 119274.
5. Wang, X.; Kang, X.; An, J.; Chen, H.; Yan, D. Reinforcement learning approach for optimal control of ice-based thermal energy storage (TES) systems in commercial buildings. Energy. Build. 2023, 301, 113696.
6. Yu, D.; Zhou, X.; Qi, H.; Qian, F. Low-carbon city planning based on collaborative analysis of supply and demand scenarios. City. Built. Enviro. 2023, 1, 7.
7. Ghersi, D. E.; Amoura, M.; Loubar, K.; Desideri, U.; Tazerout, M. Multi-objective optimization of CCHP system with hybrid chiller under new electric load following operation strategy. Energy 2021, 219, 119574.
8. Lu, Y.; Wang, S.; Sun, Y.; Yan, C. Optimal scheduling of buildings with energy generation and thermal energy storage under dynamic electricity pricing using mixed-integer nonlinear programming. Appl. Energy. 2015, 147, 49-58.
9. Xiao, Y.; Sun, W.; Sun, L. Dynamic programming based economic day-ahead scheduling of integrated tri-generation energy system with hybrid energy storage. J. Energy. Storage. 2021, 44, 103395.
10. Wang, J.; Jing, Y.; Zhang, C. Optimization of capacity and operation for CCHP system by genetic algorithm. Appl. Energy. 2010, 87, 1325-35.
11. Dai, Y.; Zeng, Y. Optimization of CCHP integrated with multiple load, replenished energy, and hybrid storage in different operation modes. Energy 2022, 260, 125129.
12. Wang, Y.; Qin, Y.; Ma, Z.; Wang, Y.; Li, Y. Operation optimisation of integrated energy systems based on cooperative game with hydrogen energy storage systems. Int. J. Hydrogen. Energy. 2023, 48, 37335-54.
13. Xu, Y.; Yan, C.; Liu, H.; Wang, J.; Yang, Z.; Jiang, Y. Smart energy systems: A critical review on design and operation optimization. Sustain. Cities. Soc. 2020, 62, 102369.
14. Wang, Z.; Xiao, F.; Ran, Y.; Li, Y.; Xu, Y. Scalable energy management approach of residential hybrid energy system using multi-agent deep reinforcement learning. Appl. Energy. 2024, 367, 123414.
15. Ren, K.; Liu, J.; Wu, Z.; Liu, X.; Nie, Y.; Xu, H. A data-driven DRL-based home energy management system optimization framework considering uncertain household parameters. Appl. Energy. 2024, 355, 122258.
16. Salari, A.; Ahmadi, S. E.; Marzband, M.; Zeinali, M. Fuzzy Q-learning-based approach for real-time energy management of home microgrids using cooperative multi-agent system. Sustain. Cities. Soc. 2023, 95, 104528.
17. He, H.; Meng, X.; Wang, Y.; et al. Deep reinforcement learning based energy management strategies for electrified vehicles: Recent advances and perspectives. Renew. Sustain. Energy. Rev. 2024, 192, 114248.
18. Ming, F.; Gao, F.; Liu, K.; Li, X. A constrained DRL-based bi-level coordinated method for large-scale EVs charging. Appl. Energy. 2023, 331, 120381.
19. Xiao, H.; Fu, L.; Shang, C.; Bao, X.; Xu, X.; Guo, W. Ship energy scheduling with DQN-CE algorithm combining bi-directional LSTM and attention mechanism. Appl. Energy. 2023, 347, 121378.
20. Tian, W.; Fu, G.; Xin, K.; Zhang, Z.; Liao, Z. Improving the interpretability of deep reinforcement learning in urban drainage system operation. Water. Res. 2024, 249, 120912.
21. Li, H.; Yang, Y.; Liu, Y.; Pei, W. Federated dueling DQN based microgrid energy management strategy in edge-cloud computing environment. Sustain. Energy. Grids. Netw. 2024, 38, 101329.
22. Zheng, L.; Wu, H.; Guo, S.; Sun, X. Real-time dispatch of an integrated energy system based on multi-stage reinforcement learning with an improved action-choosing strategy. Energy 2023, 277, 127636.
23. Demir, S.; Kok, K.; Paterakis, N. G. Statistical arbitrage trading across electricity markets using advantage actor–critic methods. Sustain. Energy. Grids. Netw. 2023, 34, 101023.
24. Nakabi, T. A.; Toivanen, P. Deep reinforcement learning for energy management in a microgrid with flexible demand. Sustain. Energy. Grids. Netw. 2021, 25, 100413.
25. Yang, T.; Zhao, L.; Li, W.; Zomaya, A. Y. Dynamic energy dispatch strategy for integrated energy system based on improved deep reinforcement learning. Energy 2021, 235, 121377.
26. Brandi, S.; Gallo, A.; Capozzoli, A. A predictive and adaptive control strategy to optimize the management of integrated energy systems in buildings. Energy. Rep. 2022, 8, 1550-67.
27. Zhang, B.; Hu, W.; Cao, D.; Huang, Q.; Chen, Z.; Blaabjerg, F. Deep reinforcement learning–based approach for optimizing energy conversion in integrated electrical and heating system with renewable energy. Energy. Conver. Manage. 2019, 202, 112199.
28. Lingmin, C.; Jiekang, W.; Huiling, T.; Feng, J.; Yanan, W. A Q-learning based optimization method of energy management for peak load control of residential areas with CCHP systems. Electr. Power. Syst. Res. 2023, 214, 108895.
29. Ding, H.; Xu, Y.; Chew Si Hao, B.; Li, Q.; Lentzakis, A. A safe reinforcement learning approach for multi-energy management of smart home. Electr. Power. Syst. Res. 2022, 210, 108120.
30. Jiang, W.; Liu, Y.; Fang, G.; Ding, Z. Research on short-term optimal scheduling of hydro-wind-solar multi-energy power system based on deep reinforcement learning. J. Clean. Prod. 2023, 385, 135704.
31. Zhou, Y.; Huang, Y.; Mao, X.; Kang, Z.; Huang, X.; Xuan, D. Research on energy management strategy of fuel cell hybrid power via an improved TD3 deep reinforcement learning. Energy 2024, 293, 130564.
32. Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-baselines3: reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021. , 22, 1-8. https://github.com/DLR-RM/stable-baselines3 (accessed 2026-03-30).
33. Brockman, G.; Cheung, V.; Pettersson, L.; et al. OpenAI Gym. arXiv 2016. , arXiv:1606.01540. Available online: https://arxiv.org/abs/1606.01540 (accessed 30 March 2026).
34. PyTorch. PyTorch: Tensors and dynamic neural networks in Python with strong GPU acceleration. 2016. Retrieved from https://pytorch.org/. (accessed 2026-03-30).
35. State Grid Home Page. https://www.95598.cn/osgweb/index. (accessed 2026-03-30).
36. Shanghai Municipal Development & Reform Commission Home Page. https://fgw.sh.gov.cn/. (accessed 2026-03-30).
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Data & Comments
Data
0









Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].